This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
When scientists collect samples from the environment to study microplastics, they usually want to know more about the chemical identities of the microplastic particles found in the samples. Many plastic polymers have similar structures, so two different polymers can have similar spectra.
Sample Google Drive Structure Available for Download. Depending on the members’ comfort level with tech, you may also need to do some training. 3) Conserve Resources. Managing a board, whether large or small, is no small administrative task. The chair and staff need to draft and track a significant amount of materials.
Additionally, nonprofits can create their own custom-trained GPT chatbot with their custom data. This enables the creation of a tailor-made AI assistant, specifically trained to understand and address your nonprofit’s unique needs. Consider ChatGPT as the most intelligent, knowledgeable, expert assistant you’ve ever had.
Posted by Ziniu Hu, Student Researcher, and Alireza Fathi, Research Scientist, Google Research, Perception Team Large-scale models, such as T5 , GPT-3 , PaLM , Flamingo and PaLI , have demonstrated the ability to store substantial amounts of knowledge when scaled to tens of billions of parameters and trained on large text and image datasets.
Take advantage of the distributive power of Apache Spark and concurrently train thousands of auto-regressive time-series models on big data Photo by Ricardo Gomez Angel on Unsplash 1. How should we train and manage thousands of models? What if we need to create this forecast relatively frequently? or even in real time?
Fortunately, when it comes to the structure of a Letter of Inquiry, you dont have to guess at what is required. Sometimes the funder will tell you exactly what they want, and they might even provide a sample. If the funder doesn’t provide guidance, you can use our tried-and-true template for a stellar Letter of Inquiry!
In most scenarios users have a limited labeling budget, and sometimes there aren’t even any labeled samples during training. Furthermore, even when labeled data are available, there could be biases in the way samples are labeled, causing distribution differences. Green/red dots represent normal/abnormal samples, respectively).
In the last 10 years, AI and ML models have become bigger and more sophisticated — they’re deeper, more complex, with more parameters, and trained on much more data, resulting in some of the most transformative outcomes in the history of machine learning. While effective, attention mechanisms have poor (i.e.,
AI can be trained to mimic its programmer’s values, but it is unable to independently distinguish right from wrong or good from evil. Make appropriate training available. Here’s a sample of the options on Coursera. ANNs are inspired by the structure and function of the human brain. AI can only use the available data.
LibreFold , which looks to increase access to AI protein structure prediction systems similar to DeepMind’s AlphaFold 2. Each project is led by independent researchers, but Stability AI is providing support in the form of access to its AWS-hosted cluster of over 5,000 Nvidia A100 GPUs to train the AI systems. coli and yeast.
Their purpose is dictated by their structure, which folds like origami into complex and irregular shapes. Previously, determining the structure of a protein relied on expensive and time-consuming experiments. But last year DeepMind showed it can produce accurate predictions of a protein’s structure using AI software called AlphaFold.
You can expect to continue to see more blog posts from me on the topic of peer learning design and training techniques as I continue to do this work. 3: Pick the structure that best fits your capacity and goals. There is no one “right” or ideal structure for a Giving Day. Capacity Free Agent Training Design'
Today, if a hematologist wanted to dive into the exact organization and structure of your blood cells, they’d probably need a microscope in a lab. That process involves placing a smear of blood onto a slide, and examining the shape, size and structure of certain cells using a well-trained eye. Image Credits: Scopio. (It
In April, we described our work on PaLM , a large, 540 billion parameter language model built using our Pathways software infrastructure and trained on multiple TPU v4 Pods. This work provided additional evidence that increasing the scale of the model and training data can significantly improve capabilities. See paper for details.)
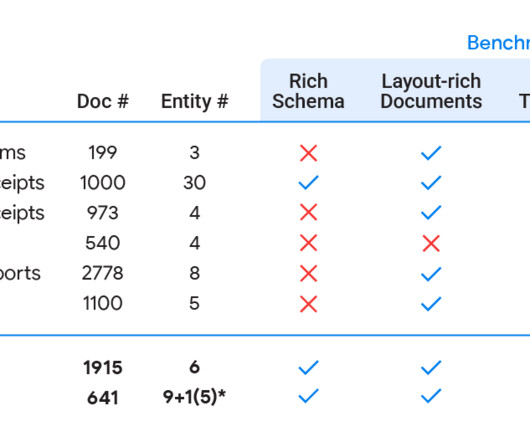
Posted by Sandeep Tata, Software Engineer, Google Research, Athena Team The last few years have seen rapid progress in systems that can automatically process complex business documents and turn them into structured objects. Diverse Templates: A benchmark should include different structural layouts or templates.
phonemes ) and their temporal structure (e.g., SoundStorm relies on a bidirectional attention-based Conformer , a model architecture that combines a Transformer with convolutions to capture both local and global structure of a sequence of tokens. In the case of audio, neural audio codecs (e.g., with AudioLM ), text-to-speech (e.g.,
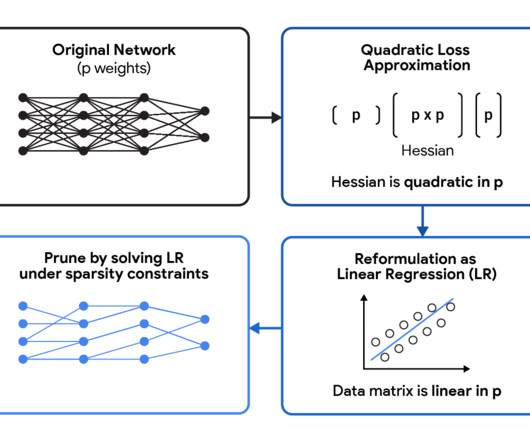
A widely used approach to mitigate the inference costs of pre-trained networks is to prune them by removing some of their weights, in a way that doesn’t significantly affect utility. Pruning methods can be applied at different stages of the network’s training process: post, during, or before training (i.e.,
The system is trained end-to-end via imitation learning to mimic expert demonstrations. For each scenario, the learned policies (EP and Performer-MPC) are trained with scenario-specific demonstrations. Our policies are trained through behavior cloning with a few hours of human-controlled robot navigation data in the real world.
The reward model is a lightweight neural network that is continuously trained with ongoing automated feedback on preference comparisons designed to mimic the offline oracle. The model is learned continuously using a transient buffer of training examples constructed from the automated feedback process.
With Image Augmentation , you can create new training images from your dataset by randomly transforming existing images, thereby increasing the size of the training data via augmentation. Concrete surface cracks are a major defect in civil structures. Image Augmentation. Don’t have enough images for your dataset?
Layout analysis is another relevant line of research that takes a document image and extracts its structure, i.e., title, paragraphs, headings, figures, tables and captions. We filtered through these annotated images, keeping only images rich in text content and layout structure. Samples from the HierText dataset.
Submitted by Amy Sample Ward, publisher of Amy Sample Ward’s Version of NPTech Hildy Gottlieb’s new book The Pollyanna Principles is a handbook for starting a revolution in social benefit organization design and practice, but it isn’t the revolution. What’s the catch? We’ve done step 1: admitted that we have a problem.
The S4 correspondence: Training data (and architecture) determine the loss landscape. This correspondence provides a starting point for developing new tools for interpreting algorithmic structure (by probing the geometry of the loss landscape) and aligning advanced AI systems (by controlling the data distribution over training).
In addition, we discovered insights for GNN models from their performance across thousands of graphs with varying structure (shown below). First of all, we have made a variety of algorithmic advances to address the problem of training large neural networks with DP. Structure of auto-bidding online ads system.
Data annotation, or the process of adding labels to images, text, audio and other forms of sample data, is typically a key step in developing AI systems. The vast majority of systems learn to make predictions by associating labels with specific data samples, like the caption “bear” with a photo of a black bear.
This means that the training data will be small enough to hold in a pandas dataframe in memory, though the tools we come up with might be applied to any type and size of data. Start from the end When we’re done, we’d like to have a unified framework to take our model through the entire pipeline from training to prediction.
You may be thinking that it’s not the right time to consider additional employee training at your organization because everyone is stressed about the pandemic. However, that’s actually what makes it a perfect time to invest in new training programs! When you train individuals to be better fundraisers , you’ll raise more money.
The recent advancements in large language models (LLMs) pre-trained on extensive internet data have shown a promising path towards achieving this goal. Despite having internal knowledge about robot motions, LLMs struggle to directly output low-level robot commands due to the limited availability of relevant training data.
We spell poorly, and we know less grammar and sentence structure now than when we played tetherball. If an applicant gets an interview, ask him or her to bring along a few writing samples. If you’re hiring a grant writer, request samples of grants he’s written. Would volunteers benefit from a training manual?
The 1-10-1000 Rule gives you a simple structure to guide your fundraising activities for the year and encourages you to focus on 3 streams of revenue: 1 signature event, 10 grant opportunities, and 1,000 individual donors. It can be confusing to figure out where to start…. That’s why I recommend the 1-10-1,000 Rule. Get 10 grants.
The safest way to have interns participate in social media is to have them analyze the data and then come up with sample posts for the platform. For example, a guide on using Fortnite to reach tweens, or a short training on memes or emerging social media platforms the company should be aware of. Visit Campus 15.
As Visiting Scholar in Nonprofits and Social Media at the David and Lucile Packard Foundation, I am coaching grantee organizations and leading workshops and peer trainings on how to become a Networked Nonprofit. Here’s quick sampling: LA Universal Preschool. View more presentations from Beth Kanter.
Argument for interpretability automation I focus on the claim that interpretability will likely be automated by training against robust downstream metrics which use interpretability methods. We need enough tasks to have a train, validation and test splits over tasks, I expect something on the order of 25 would be sufficient.
As customers identify issues that matter to them, it helps train the company’s machine models, which should then get better over time at finding the most critical problems. “We really structure our interviews around four competencies that we’re looking for, versus like brain-teaser questions.”
In i-Sim2Real , we showed an approach to address the sim-to-real gap and learn to play table tennis with a human opponent by bootstrapping from a simple model of human behavior and alternating between training in simulation and deploying in the real world. In each iteration, both the human behavior model and the policy are refined.
Training and Peer Learning :: skill-building, knowledge sharing, and network building. Staffing Support :: advising on staffing structures, integration efforts, and hands-on support with talent recruitment and hiring. Storytelling and Knowledge Transfer :: sharing innovations, lessons learned, fail stories, and emerging best practices.
Rewriting strengthens logic, structure, and transitions. Overall, this methodology structures regular critical analysis of output to curate higher quality through ongoing refinement. Strengthening Coherence Identify ways the previous reply could have improved flow, transitions, and logical structure.
Without a handbook, volunteers may feel disconnected and unsure of their role and responsibilities because once training is over, there are no materials for them to reference later. Training opportunities: At minimum, you need an orientation to go over information in the handbook. What about working off site?
Facing the real possibility of production-ready AI, enterprise data leaders dont have time to sample from the data quality menua few dbt tests here, a couple point solutions there. Users can ask a large model about effectively anything, so that model needs to be trained on a large enough corpus of data to deliver a relevant response.
Deep models require a lot of training examples, but labeled data is difficult to obtain. In recent empirical developments, models trained with unlabeled data have begun to approach fully-supervised performance (e.g., The self-training procedure is depicted below. The self-training procedure is depicted below. Chen et al.,
First, it could cause a form of train-test contamination if an LLM knows it is being tested, then the test may no longer accurately report the LLMs true capabilities. suggest that standard training procedures could incentivize attaining situational awareness. Situational Awareness Dataset Laine et al.
training and learning cross-discipline where feasible. This works if it turns out there is a deep structural problem but can be a lot of time wasted if it turns out that the problem was due to totally random circumstances. Choose to take advice from an appropriate sample size of people and/or stick a time limit on it.
A small sample of the positive words they have shared include: empowered, humbled, motivated, grateful, awed, helpful, effective, connected, valuable, and inspired. They then bring in volunteers without first setting up the appropriate infrastructure to orient, train, supervise, and recognize them properly.
We organize all of the trending information in your field so you don't have to. Join 12,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content