This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
million books, to train its AI models. A lawsuit in the US alleges Meta CEO Mark Zuckerberg approved the use of LibGen's data to train its AI. Artists across the creative industries have also recently protested the UK government's December 2024 proposal to change copyright law.
The camp’s design was co-developed by Perkins & Will and an advisory board from Lighthouse, with blind and visually-impaired stakeholders offering feedback on early design proposals and insight into how the spaces in the camp would be used. The camp also operates year-round as a retreat, hosting corporate events and weddings.
However, visual language has not garnered a similar level of attention, possibly because of the lack of large-scale training sets in this space. In light of these challenges, we propose “ MatCha: Enhancing Visual Language Pretraining with Math Reasoning and Chart Derendering ”.
The governments proposal suggested a system that permits AI developers to use creators online content to train their models unless rights holders explicitly choose to opt out.
Posted by Ziniu Hu, Student Researcher, and Alireza Fathi, Research Scientist, Google Research, Perception Team Large-scale models, such as T5 , GPT-3 , PaLM , Flamingo and PaLI , have demonstrated the ability to store substantial amounts of knowledge when scaled to tens of billions of parameters and trained on large text and image datasets.
However, today’s startups need to reconsider the MVP model as artificial intelligence (AI) and machine learning (ML) become ubiquitous in tech products and the market grows increasingly conscious of the ethical implications of AI augmenting or replacing humans in the decision-making process. Machines are trained based on historical data.
Also consider organizations with slightly larger revenues, which can offer insights into what your funding model might look like, should your organization grow. Those capabilities cant be built overnight, so youll need to share your findings and proposed funding strategy with key internal stakeholderswho are vital to implementing it.
I will begin with a discussion of language, computer vision, multi-modal models, and generative machine learning models. Language Models The progress on larger and more powerful language models has been one of the most exciting areas of machine learning (ML) research over the last decade. Let’s get started!
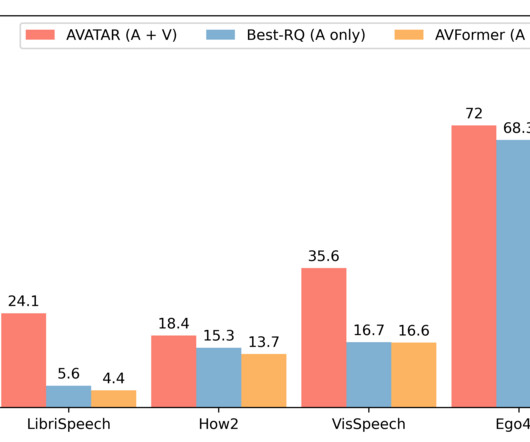
Building audiovisual datasets for training AV-ASR models, however, is challenging. In contrast, the models themselves are typically large and consist of both visual and audio encoders, and so they tend to overfit on these small datasets. LibriSpeech ). LibriSpeech ). Unconstrained audiovisual speech recognition.
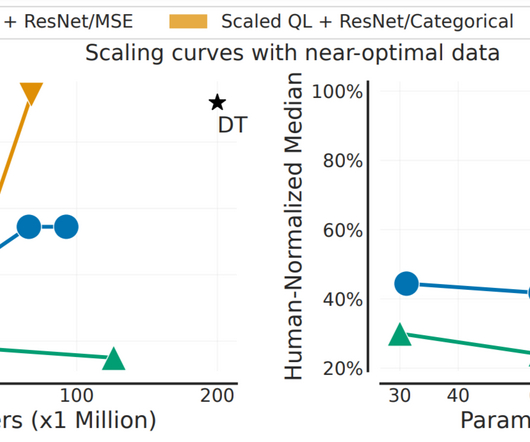
Pre-training on diverse datasets has proven to enable data-efficient fine-tuning for individual downstream tasks in natural language processing (NLP) and vision problems. So, we ask the question: Can we enable similar pre-training to accelerate RL methods and create a general-purpose “backbone” for efficient RL across various tasks?
In fact, training a single advanced AI model can generate carbon emissions comparable to the lifetime emissions of a car. And with the rapid advancement of generative AI models potentially slowing down , this provides a unique opportunity to take a breath and reimagine and mature our approach.
OpenAI claims that it’s developed a way to use GPT-4 , its flagship generative AI model, for content moderation — lightening the burden on human teams. “We can repeat [these steps] until we’re satisfied with the policy quality.” ” But color me skeptical. Has OpenAI solved this problem?
Earlier this month, I presented on a panel called “ Learn, You Will ” with Cindy Leonard, John Kenyon, and Andrea Berry on the topic of designing effective nonprofit technology training at the Nonprofit Technology Conference hosted by NTEN. 6 Tips for Evaluating Your Training Session.
It may feel intimidating at first, but here’s the exciting part: today, more than ever, nonprofits have the tools and resources to make a smooth shift to the grants-plus-fundraising model. Adding fundraising to your funding model gives you the agility to stay mission-focused no matter what comes your way.
They forget that training, equipment, and hiring resources also contribute to the cost. While this is understandable, a void of guidance and official policy at the top of the organization leads to employees taking things into their own hands and using AI tools without proper transparency and training.
Posted by Shunyu Yao, Student Researcher, and Yuan Cao, Research Scientist, Google Research, Brain Team Recent advances have expanded the applicability of language models (LM) to downstream tasks. On the other hand, recent work uses pre-trained language models for planning and acting in various interactive environments (e.g.,
Companies face several hurdles in creating text-, audio- and image-analyzing AI models for deployment across their apps and services. Cost is an outsize one — training a single model on commercial hardware can cost tens of thousands of dollars, if not more. Geifman proposes neural architecture search (NAS) as a solution.
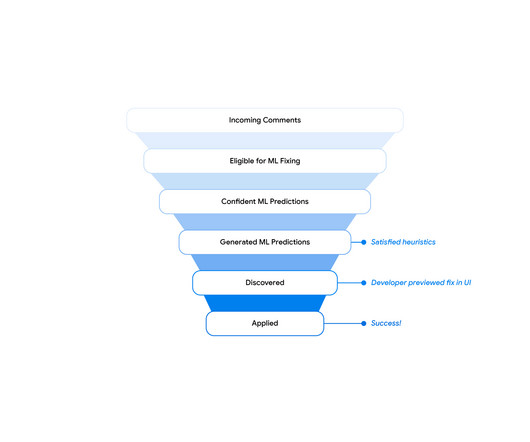
As part of this process, the reviewer inspects the proposed code and asks the author for code changes through comments written in natural language. However, with machine learning (ML), we have an opportunity to automate and streamline the code review process, e.g., by proposing code changes based on a comment’s text.
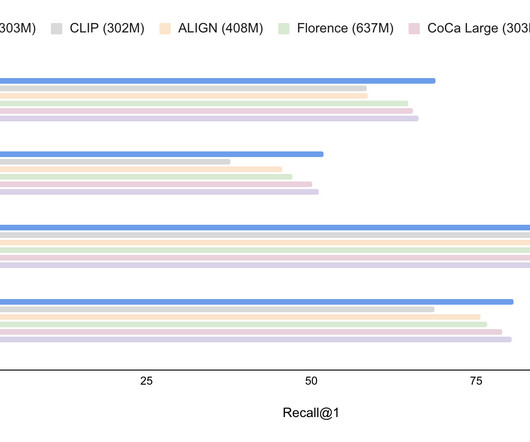
Recent vision and language models (VLMs), such as CLIP , have demonstrated improved open-vocabulary visual recognition capabilities through learning from Internet-scale image-text pairs. The category text embeddings are obtained by feeding the category names through the text model of pretrained VLM (which has both image and text models)r.
In the last 10 years, AI and ML models have become bigger and more sophisticated — they’re deeper, more complex, with more parameters, and trained on much more data, resulting in some of the most transformative outcomes in the history of machine learning.
The Letter of Inquiry is part of the grantmaking process because it would be overwhelming and time-consuming for funders to review 15-page proposals from everyone seeking money. Due to space limitations, it’s better to wait to include photos for the invitation to submit a full proposal. That would simple take too long.
The trajectory is based on a sequence of five fictional models (M1-M5) with progressively advanced capabilities. For each model, we define an AI Control Level (ACL) based primarily on its threat model-specific capabilities.
A bipartisan group of lawmakers has proposed banning police from buying access to user data from data brokers, including ones that “illegitimately obtained” their records — like, its sponsors say, the facial recognition service Clearview AI. Photo by Caroline Brehman/CQ-Roll Call, Inc via Getty Images.
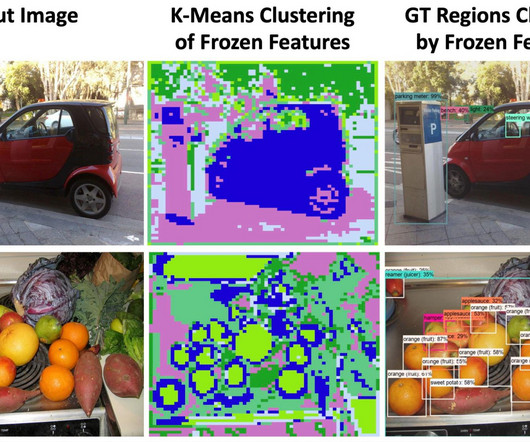
However, modern object detectors are limited by the manual annotations of their training data, resulting in a vocabulary size significantly smaller than the vast array of objects encountered in reality. Thus, it could be beneficial for open-vocabulary detection if we build locality information into the image-text pre-training.
BayesOpt works by repeatedly constructing a surrogate model of the black-box function and strategically evaluating the function at the most promising or informative input location, given the information observed so far. The Gaussian process model constructs a probability distribution over possible functions.
The growing compute power necessary to train sophisticated AI models such as OpenAI’s ChatGPT might eventually run up against a wall with mainstream chip technologies. CNBC, speaking to analysts and technologists, estimates the current cost of training a ChatGPT-like model from scratch to be over $4 million.
By examining details about these projects, such as the project title and abstract (if available), the award amount, the location of the funded organization, and other relevant metrics, nonprofits can tailor their grant proposals to that foundation. Those texts can be mined and used to improve the model for everyone.
Older models tended to be AMS-centric, leading to siloed data, static reports, and that trapped feeling. Provide training opportunities for employees and review your taxonomy from time to time to update any new processes. You may also consider training for all employees to become more familiar with how your association uses data.
A narrative that illustrates your nonprofit’s program impact The logic model is a classic framework for illustrating a program’s impact. A proposal focused on program impact includes: Need: What need does your program serve? These inputs are discussed in the project description and budget sections of your proposal.
This increase in accuracy is important to make AI applications good enough for production , but there has been an explosion in the size of these models. It is safe to say that the accuracy hasn’t been linearly increasing with the size of the model. They define it as “buying” stronger results by just throwing more compute at the model.
Posted by Shekoofeh Azizi, Senior Research Scientist, and Laura Culp, Senior Research Engineer, Google Research Despite recent progress in the field of medical artificial intelligence (AI), most existing models are narrow , single-task systems that require large quantities of labeled data to train.
Contracts and briefs in legal work, leases and agreements in real estate, proposals and releases in marketing, medical charts, etc, etc. At the core of XML was the idea that a document should be structured almost like a webpage: boxes within boxes, each clearly defined by metadata — a hierarchical model more easily understood by computers.
There are a few core elements of the way communities work that we can learn from as a model for innovation as well. Community-Driven Model. But in a community-driven model, you can’t just listen for the sake of learning. What are the technologies that support community-driven engagement and models of working? Principles.
In most scenarios users have a limited labeling budget, and sometimes there aren’t even any labeled samples during training. In “ SPADE: Semi-supervised Anomaly Detection under Distribution Mismatch ”, we propose a novel semi-supervised AD framework that yields robust performance even under distribution mismatch with limited labeled samples.
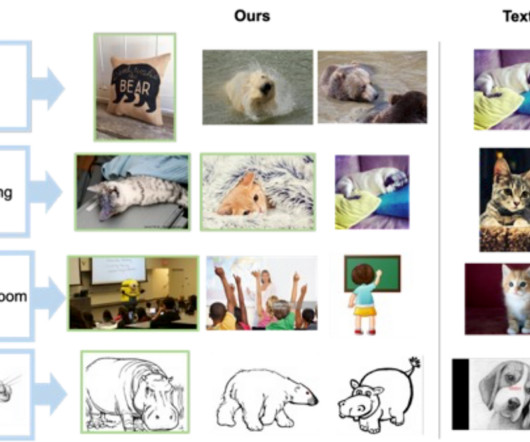
Collecting such labeled data is costly, and modelstrained on this data are often tailored to a specific use case, limiting their ability to generalize to different datasets. To address these challenges, in “ Pic2Word: Mapping Pictures to Words for Zero-shot Composed Image Retrieval ”, we propose a task called zero-shot CIR (ZS-CIR).
While large language models (LLMs) are now beating state-of-the-art approaches in many natural language processing benchmarks, they are typically trained to output the next best response, rather than planning ahead, which is required for multi-turn interactions. We address these challenges using a novel RL construction.
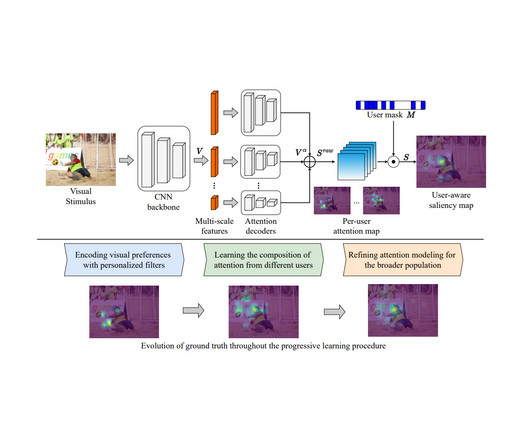
Modeling human attention (the result of which is often called a saliency model) has therefore been of interest across the fields of neuroscience, psychology, human-computer interaction (HCI) and computer vision. Attention-guided image editing Human attention models usually take an image as input (e.g.,
Beyond providing instructions for completing and submitting the form, consider offering additional guidance such as proposal examples, file-naming conventions, FAQs, and how-to videos. Diversify and train the reviewer pool.
Massachusetts legislators passed the first major state-level facial recognition ban, following a model set by individual cities like Boston and San Francisco. Facial recognition is just one facet of the sweeping bill, which aims to reform police tactics, training, and accountability.
We fine-tuned a large language model to proactively suggest relevant visuals in open-vocabulary conversations using a dataset we curated for this purpose. For example, out of context, the transcription model misunderstood the word "pier" as "pair", but Visual Captions still recommends images of the Santa Monica Pier.
A coalition of AI researchers, data scientists, and sociologists has called on the academic world to stop publishing studies that claim to predict an individual’s criminality using algorithms trained on data like facial scans and criminal statistics. Algorithms trained on racist data produce racist results.
Maybe you need to create an appeal for an email campaign, a proposal, or a new set of thank you letters and you’re at your desk just wishing that coherent sentences would magically start appearing? I have used it to help me write appeals, emails, thank you letters, and draft some 1 and 2-page proposals. Fundwriter.ai Fundwriter.ai
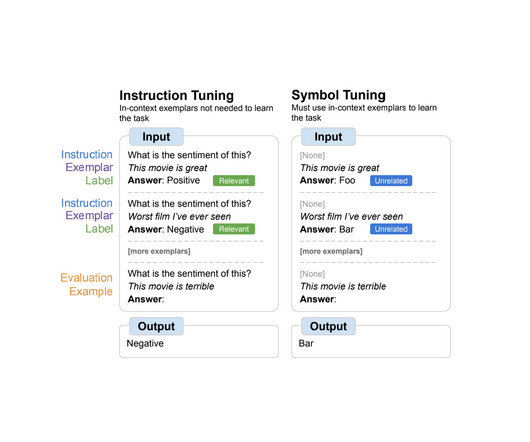
Scaling up language models has unlocked a range of new applications and paradigms in machine learning, including the ability to perform challenging reasoning tasks via in-context learning. Language models, however, are still sensitive to the way that prompts are given, indicating that they are not reasoning in a robust manner.
We organize all of the trending information in your field so you don't have to. Join 12,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content