This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
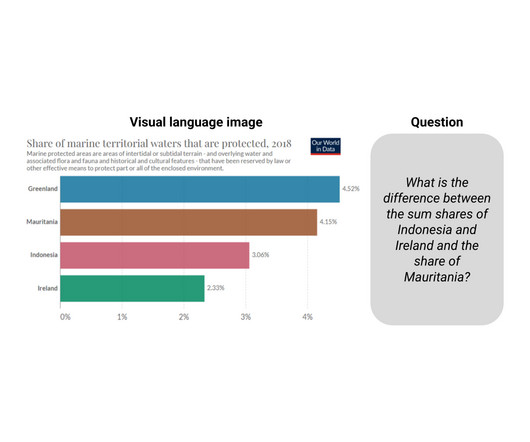
Existing models built for these tasks relied on integrating optical character recognition (OCR) information and their coordinates into larger pipelines but the process is error prone, slow, and generalizes poorly. Answering the question requires reading the information and computing the sum and the difference.
It may feel intimidating at first, but here’s the exciting part: today, more than ever, nonprofits have the tools and resources to make a smooth shift to the grants-plus-fundraising model. Adding fundraising to your funding model gives you the agility to stay mission-focused no matter what comes your way.
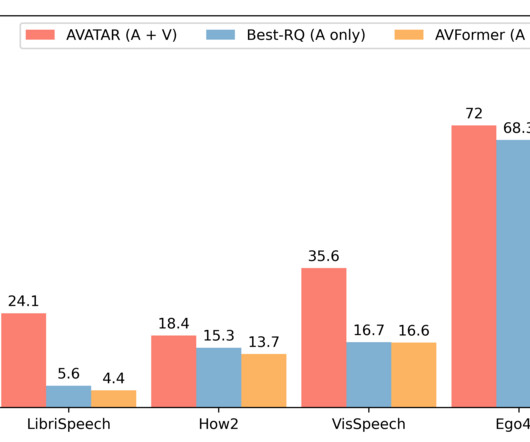
Building audiovisual datasets for training AV-ASR models, however, is challenging. In contrast, the models themselves are typically large and consist of both visual and audio encoders, and so they tend to overfit on these small datasets. LibriSpeech ). LibriSpeech ). Unconstrained audiovisual speech recognition.
I will begin with a discussion of language, computer vision, multi-modal models, and generative machine learning models. Language Models The progress on larger and more powerful language models has been one of the most exciting areas of machine learning (ML) research over the last decade. Let’s get started!
Posted by Shunyu Yao, Student Researcher, and Yuan Cao, Research Scientist, Google Research, Brain Team Recent advances have expanded the applicability of language models (LM) to downstream tasks. On the other hand, recent work uses pre-trained language models for planning and acting in various interactive environments (e.g.,
The trajectory is based on a sequence of five fictional models (M1-M5) with progressively advanced capabilities. For each model, we define an AI Control Level (ACL) based primarily on its threat model-specific capabilities.
Posted by Eleni Triantafillou, Research Scientist, and Malik Boudiaf, Student Researcher, Google Deep learning has recently made tremendous progress in a wide range of problems and applications, but models often fail unpredictably when deployed in unseen domains or distributions.
In the last 10 years, AI and ML models have become bigger and more sophisticated — they’re deeper, more complex, with more parameters, and trained on much more data, resulting in some of the most transformative outcomes in the history of machine learning.
A new Alphabet company will use artificial intelligence methods for drug discovery, Google’s parent company announced Thursday. AI could help scan through databases of potential molecules to find some that best fit a particular biological target, for example, or to fine-tune proposed compounds. Photo by Micah Singleton / The Verge.
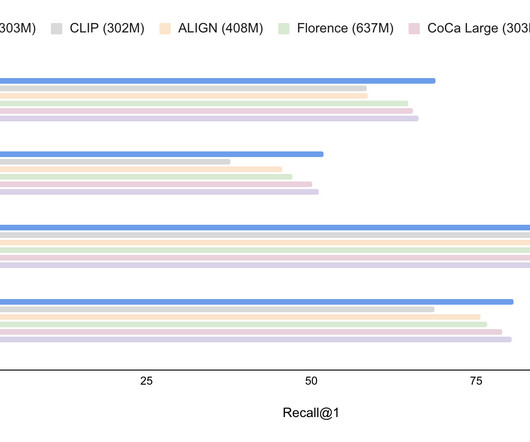
Recent vision and language models (VLMs), such as CLIP , have demonstrated improved open-vocabulary visual recognition capabilities through learning from Internet-scale image-text pairs. The category text embeddings are obtained by feeding the category names through the text model of pretrained VLM (which has both image and text models)r.
The downtime variable is important to include because as more data teams drive higher levels of revenue–via machine learning models, customer-facing apps, data democratization, and other initiatives–the more severe the consequences of downtime becomes in terms of lost time, revenue, and trust. The first is when data IS the product.
Posted by Shekoofeh Azizi, Senior Research Scientist, and Laura Culp, Senior Research Engineer, Google Research Despite recent progress in the field of medical artificial intelligence (AI), most existing models are narrow , single-task systems that require large quantities of labeled data to train.
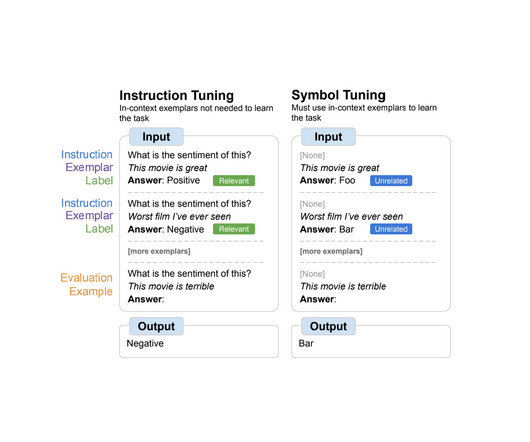
Scaling up language models has unlocked a range of new applications and paradigms in machine learning, including the ability to perform challenging reasoning tasks via in-context learning. Language models, however, are still sensitive to the way that prompts are given, indicating that they are not reasoning in a robust manner.
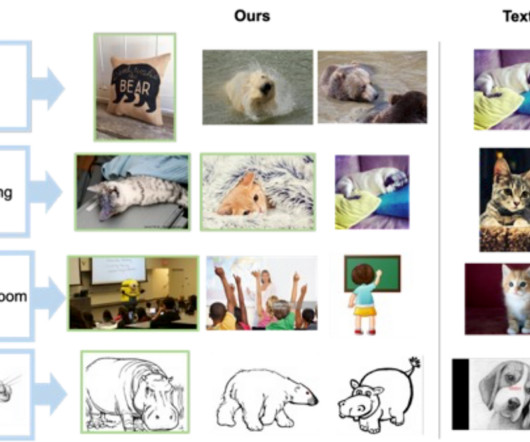
However, CIR methods require large amounts of labeled data, i.e., triplets of a 1) query image, 2) description, and 3) target image. Collecting such labeled data is costly, and models trained on this data are often tailored to a specific use case, limiting their ability to generalize to different datasets.
This increase in accuracy is important to make AI applications good enough for production , but there has been an explosion in the size of these models. It is safe to say that the accuracy hasn’t been linearly increasing with the size of the model. They define it as “buying” stronger results by just throwing more compute at the model.
Google is going it alone with its proposed advertising technology to replace third-party cookies. It is a big test for Google’s proposed FLoC technology: if Microsoft isn’t going to support it, that would pretty much mean Chrome really will be going it alone with this technology. Illustration by James Bareham / The Verge.
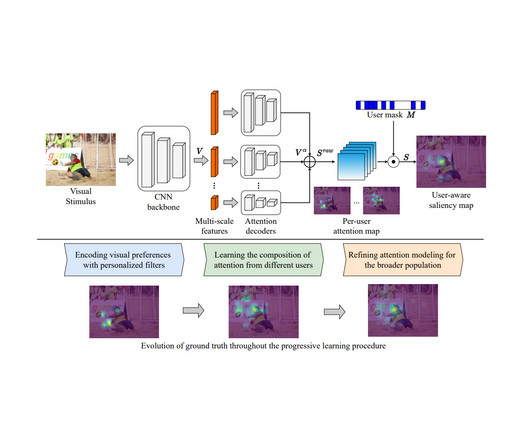
Modeling human attention (the result of which is often called a saliency model) has therefore been of interest across the fields of neuroscience, psychology, human-computer interaction (HCI) and computer vision. Attention-guided image editing Human attention models usually take an image as input (e.g.,
Contracts and briefs in legal work, leases and agreements in real estate, proposals and releases in marketing, medical charts, etc, etc. At the core of XML was the idea that a document should be structured almost like a webpage: boxes within boxes, each clearly defined by metadata — a hierarchical model more easily understood by computers.
Within the arena of startup incubators, however, Benetech’s social enterprise business model and Benetech Labs’ approach are unique. The typical incubator model works well where a team has formed around a technology innovation and is looking to graduate a for-profit company. Let me explain how this is so.
Such real-world data challenges limit the achievable accuracy of prior methods in detecting anomalies. In “ SPADE: Semi-supervised Anomaly Detection under Distribution Mismatch ”, we propose a novel semi-supervised AD framework that yields robust performance even under distribution mismatch with limited labeled samples. anomaly ratio.
These models often rely on the fact that raw data is first converted to a compressed format as a sequence of tokens. By representing audio as a sequence of discrete tokens, audio generation can be performed with Transformer -based sequence-to-sequence models — this has unlocked rapid progress in speech continuation (e.g.,
Posted by Yicheng Fan and Dana Alon, Software Engineers, Google Research Every byte and every operation matters when trying to build a faster model, especially if the model is to run on-device. Using a search space built on backbones taken from MobileNetV2 and MobileNetV3 , we find models with top-1 accuracy on ImageNet up to 4.9%
Published on February 4, 2025 6:56 AM GMT Epistemic status: I want to propose a method of learning environmental goals (a super big, super important subproblem in Alignment). Can you tell me the biggest conceptual problems of my method? Can you tell me if agent foundations researchers are aware of this method or not?
Robust algorithm design is the backbone of systems across Google, particularly for our ML and AI models. We provided a model-based taxonomy that unified many graph learning methods. In addition, we discovered insights for GNN models from their performance across thousands of graphs with varying structure (shown below).
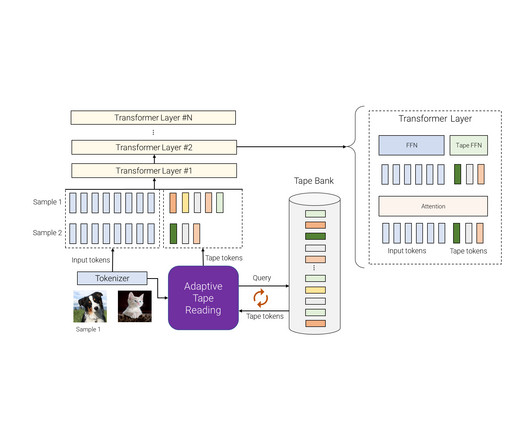
While conventional neural networks have a fixed function and computation capacity, i.e., they spend the same number of FLOPs for processing different inputs, a model with adaptive and dynamic computation modulates the computational budget it dedicates to processing each input, depending on the complexity of the input.
Validating Modern Machine Learning (ML) Methods Prior to Productionization. Last time , we discussed the steps that a modeler must pay attention to when building out ML models to be utilized within the financial institution. Validating Machine Learning Models. Effective validation helps ensure that models are sound.
While large language models (LLMs) are now beating state-of-the-art approaches in many natural language processing benchmarks, they are typically trained to output the next best response, rather than planning ahead, which is required for multi-turn interactions. We refer to this two-part approach as dynamic composition.
However, current works, such as ViViT and TimeSFormer , densely process the video and require significant compute, especially as model size plus video length and resolution increase. Depending on the input video size, the three tube shapes are applied to the model multiple times to generate tokens.
In the same way that BERT or GPT-3 models provide general-purpose initialization for NLP, large RL–pre-trained models could provide general-purpose initialization for decision-making. Our shared vision backbone also utilized a learned position embedding (akin to Transformer models) to keep track of spatial information in the game.
Although the most popular accounting software products- like QuickBooks and SAP- handle the needs of businesses in many industries, nonprofits have a unique business model and accounting standards and require different features and functionality from accounting software. This method?focuses?on What is Fund Accounting? on the use?of
We fine-tuned a large language model to proactively suggest relevant visuals in open-vocabulary conversations using a dataset we curated for this purpose. For example, out of context, the transcription model misunderstood the word "pier" as "pair", but Visual Captions still recommends images of the Santa Monica Pier. D8: Interaction).
Posted by Yanqi Zhou, Research Scientist, Google Research, Brain Team The capacity of a neural network to absorb information is limited by the number of its parameters, and as a consequence, finding more effective ways to increase model parameters has become a trend in deep learning research. In sparsely-activated variants of MoE models (e.g.,
The pump and pipeline project to Georgetown, developed by California-based Upwell Water, is the largest of at least a half dozen similar projects recently completed, under construction or proposed to bring rural Carrizo Wilcox aquifer water into the booming urban corridor that follows Interstate 35 through Central Texas.
Various techniques such as image-text pre-training , knowledge distillation , pseudo labeling , and frozen models, often employing convolutional neural network (CNN) backbones, have been proposed. To address this, we propose cropped positional embeddings (CPE). We are also releasing the code here.
The recent advancements in large language models (LLMs) pre-trained on extensive internet data have shown a promising path towards achieving this goal. In “ Language to Rewards for Robotic Skill Synthesis ”, we propose an approach to enable users to teach robots novel actions through natural language input.
However, applying end-to-end learning methods to mobile manipulation tasks remains challenging due to the increased dimensionality and the need for precise low-level control. Additionally, on-robot deployment either requires collecting large amounts of data, using accurate but computationally expensive models, or on-hardware fine-tuning.
Posted by Jason Wei and Yi Tay, Research Scientists, Google Research, Brain Team In recent years, language models (LMs) have become more prominent in natural language processing (NLP) research and are also becoming increasingly impactful in practice. Scaling up LMs has been shown to improve performance across a range of NLP tasks.
For research, it has not only reduced language model latency for users , designed computer architectures , accelerated hardware , assisted protein discovery , and enhanced robotics , but also provided a reliable backend interface for users to search for neural architectures and evolve reinforcement learning algorithms. Search, Ads, YouTube).
You’ve read about participatory grantmaking—and maybe even heard about other organizations using this model to distribute control of their funding strategy and grants decisions to the communities they serve. Perhaps you’ll start by reading about other models , watching webinars, or developing ideas. Is this you?
Just as you wouldn’t set off on a journey without checking the roads, knowing your route, and preparing for possible delays or mishaps, you need a model risk management plan in place for your machine learning projects. A well-designed model combined with proper AI governance can help minimize unintended outcomes like AI bias.
One social entrepreneur said that all of his funding is allowed to be used for innovation, because he promises an end result, not a precise method of how to get there. But, many of the others were eager to think through the challenges of adapting this model to their organization, and how it might work well.
The hybrid workplace will have a huge impact on the way we design and facilitate meetings, the primary method of how many organizations get stuff done. Leaders can leverage the hybrid meeting model to change this by looking around the table and making sure all voices are seen and heard, whether participating on-screen or in-person.
Along with being upfront about its results, Brave also says that it won’t track or profile users, and it claims it won’t use “secret methods or algorithms to bias results.” Brave is actually working on a proposal for a community-curated open ranking model called “Goggles” it hopes to use as an alternative to Google’s algorithm.
Published on March 13, 2025 7:18 PM GMT We study alignment audits systematic investigations into whether an AI is pursuing hidden objectivesby training a model with a hidden misaligned objective and asking teams of blinded researchers to investigate it. As a testbed, we train a language model with a hidden objective.
We organize all of the trending information in your field so you don't have to. Join 12,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content