This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
But because good intentions don’t work against unconscious preferences for in-groups, we need laws that ensure diversity and inclusion. The Supreme Court has killed the one thing that measurably helped diversify institutions: affirmative action.
The country's Data Protection Commission (DPC) said on Friday ( via Reuters ) that it's opening an inquiry into the social platform's use of European users' public posts to train its Grok AI chatbot. If this sounds familiar, the DPC took X to court in 2024 , seeking an order to stop it from training Grok on EU user data without consent.
Ongoing training fosters a culture of excellence and proactive compliance. Leveraging technology like LMS enhances the effectiveness of compliance training. Regular assessments and feedback identify gaps and ensure training success. Why Continuous Learning is Essential for Compliance Training 1.
million books, to train its AI models. A lawsuit in the US alleges Meta CEO Mark Zuckerberg approved the use of LibGen's data to train its AI. Artists across the creative industries have also recently protested the UK government's December 2024 proposal to change copyright law.
The New York Times is suing OpenAI and its close collaborator (and investor), Microsoft, for allegedly violating copyright law by training generative AI models on Times’ content. All rights reserved.
According to internal Slack chats, emails, spreadsheets, and several other sources obtained by 404 Media, Nvidia asked workers to download videos from various online platforms to compile data to train its Omniverse, autonomous vehicles, and digital human products. Read Entire Article
But a poor web design won’t get anyone on the bad side of the law whereas ignoring those important statements might. Board members are personally responsible for the organization’s compliance with all applicable laws and regulations. This includes the laws relating to financial reporting and fundraising. Is that even possible?
Fraud victims seek help from law enforcement or adult protective services, or support from a loved one, clergy member, or therapist, but because of the stigma and blame associated with the crime may be treated as foolish or incompetent instead.
UMG, Concord and ABKCO sued Anthropic in 2023 over claims that it used lyrics from at least 500 songs by musicians including Beyonce, the Rolling Stones and the Beach Boys, to train Claude without permission. The lawsuit claimed Anthropic was violating US copyright laws with its actions. Read Entire Article
Choose the right LMS for law enforcement to learn and succeed on the job. Get the most out of your training! Our guide will help you select the right platform and more.
Efficient tokenization helps reduce the amount of computing power required for training and inference. During training, the model would learn the distinction between these two meanings and assign them different token numbers. How Are Tokens Used During AI Training? This process is known as tokenization.
Federal and state laws require a nonprofit’s board members to assume responsibility for the organization’s well-being–meaning it can be held responsible if something goes wrong financially or operationally. By contrast, a governing board is bound by law to oversee management of the organization.
California recently passed a law requiring AI literacy to be incorporated into K-12 curricula starting this fall. The EU goes further, requiring companies that produce AI products to train applicable staff to have the “skills, knowledge and understanding that allow providers, deployers and affected persons.
The recent terms & conditions controversy sequence goes like this: A clause added to Zoom’s legalese back in March 2023 grabbed attention on Monday after a post on Hacker News claimed it allowed the company to use customer data to train AI models “with no opt out” Cue outrage on social media.
Early detection, coupled with robust reporting, will help law enforcement identify and safeguard potentially thousands of children in urgent need of protection. . When the tech sector does its part, children will be protected and law enforcement can continue its pursuit of offenders on the run.
Alphabet and Google employees are trained to avoid using certain words and phrases in internal communications and “assume every document will become public,” according to a new report from The Markup. But Google says the practice, which it describes as standard compliance training, has been in effect for years.
She teams with and coordinates with other environmental nonprofits to use every law on the books to battle climate change and polluters. Ambassador to the United Nations Douglas Rutzen President & CEO International Center for Not-for-Profit Law Rutzen has quietly put out political fires in back rooms around the world. Cook, Ph.D.
When we do something that creates entry level jobs in quantity, we reach out to social enterprise partners who specialize in job creation and training. Our first partner in this work was Digital Divide Data, an organization that has an outstanding training program in the area of data entry and outsourcing. We scan the books in the U.S.,
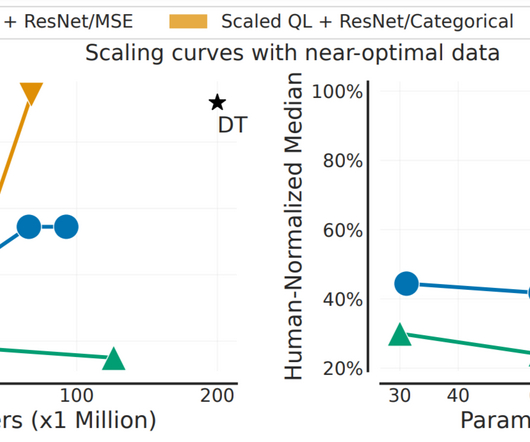
Pre-training on diverse datasets has proven to enable data-efficient fine-tuning for individual downstream tasks in natural language processing (NLP) and vision problems. So, we ask the question: Can we enable similar pre-training to accelerate RL methods and create a general-purpose “backbone” for efficient RL across various tasks?
Inconsistent legal and regulatory framework: While federal laws such as the Child Abuse Prevention and Treatment Act provide guidelines for child protection, safeguarding practices for other vulnerable groups and in broader contexts are less defined.
It is currently working with over 1,000 law firms. Here’s why: The Boulder, Colorado-based company has collected over 300,000 historical claims and uses data extraction models to plug into a law firm to provide a score on how good the firm is at winning cases, like sexual assault, medical malpractice and product liability.
However, achieving and maintaining these certifications requires structured training, comprehensive documentation, and ongoing compliance monitoring—all of which can be efficiently managed through a Learning Management System (LMS). Key training areas include: 1. Finally, it confirms that the goods met the required specifications.
The most popular model today is called a Large Language Model (LLM) , which is trained on massive text datasets. Keep in mind that the more specific the model gets and the more specific the training dataset, the better outcomes you’ll find. LLMs are meant to produce conversational human language responses.
Anthropic , a startup that hopes to raise $5 billion over the next four years to train powerful text-generating AI systems like OpenAI’s ChatGPT , today peeled back the curtain on its approach to creating those systems. Because it’s often trained on questionable internet sources (e.g. So what are these principles, exactly?
Stanford law professor Mark Lemley represented Meta in a 2023 copyright case in which the company used a data set containing copyrighted e-books to train its LLMs, something it says should be considered fair use. Read Entire Article
Your staff members should be fully trained and familiar with your emergency response plan. Conduct drills to ensure your nonprofit is ready for an emergency and require all who are on-site on training day to participate. Have an emergency preparedness and response plan in place.
. ** Ethical Issues Arise As Big Donors Get Personalized Service [link] ** 10 Ideas For Healthcare Staff Wellness [link] ** AI Helps Getting To Answers Faster When Trained [link] ** MacKenzie Scott Launches Website With Contact Details TBA [link] ** Developing Responsible AI Policy For Civil Society bit.ly/3URhZuU
These customers predominantly use the tool for training videos, it said, but also use Synthesia for monthly updates to the broader team or delivering information that would normally come via email. The law firm has 35 partners with their own avatars, creating videos for both internal comms and client communication.
This creates a unique challenge: how can organizations ensure that all employees, regardless of where they are, receive the same high-quality global workforce training? This is especially useful for global workforce training that needs to scale quickly.
To help generative AI tools answer questions beyond the information in their training data, AI companies have recently used a technique called retrieval-augmented generation , or RAG. Air Force, law firm Gunderson Dettmer, and private equity firms Charlesbank and Cinven.
In late December, The New York Times sued OpenAI and its close collaborator and investor, Microsoft, for allegedly violating copyright law by training generative AI models on Times’ content. Today, OpenAI gave a public response, claiming — unsurprisingly — that The Times’ lawsuit is meritless.
How to Choose the Right Law Practice Management Software? GyrusAim LMS GyrusAim LMS - In an increasingly tech-driven and digital world, law enforcement agencies are tackling crimes that were almost non-existent decades ago. Many police employees are not well-trained in soft skills like responding to active shooter situations.
In an increasingly tech-driven and digital world, law enforcement agencies are tackling crimes that were almost non-existent decades ago. Many police employees are not well-trained in soft skills like responding to active shooter situations. However, the workforce lacks the skills to deal with these problems.
With strict regulations from authorities like the FDA, life sciences companies must ensure their employees are adequately trained and their operations comply with ever-evolving standards. A life science regulatory compliance tracking tool ensures that employees meet training requirements and comply with regulatory standards.
Massachusetts lawmakers this week voted to ban the use of facial recognition by law enforcement and public agencies in a sweeping police reform bill that received significant bipartisan support. Illustration by Alex Castro / Th.
Training is the magic that transforms LLMs from a blank slate into a bot, or a machine with a ‘personality.’ In training the AI is exposed to vast amounts of text, datasets, and other types of information from the internet. If data in their training is inaccurate, the response to your question may also be incorrect.
Image credit: Photo by cottonbro studio on pexels In late December 2024, New York State Senator Andrew Gounardess legislation to protect domestic violence survivors was signed into law. The legislation comes as law enforcement struggles to address the evolving role of technology in domestic violence cases.
The new system could help law enforcement in criminal investigations but may open the door to increased legal and government demands for user data. neuralMatch, which was trained using 200,000 images from the National Center for Missing & Exploited Children, will roll out first in the US. The system will be used first in the US.
Last year, Facebook said it was studying whether its algorithms trained using AI—including those of Instagram, which Facebook owns— were racially biased.
Training for Team Members: Team Success Through Training GyrusAim LMS GyrusAim LMS - Training for team members is important for achieving team success as it enhances individual skills, fosters effective communication, and promotes a shared understanding of goals. Methods: Choose an effective training approach.
Training for Team Members: Team Success Through Training GyrusAim LMS GyrusAim LMS - Training for team members is important for achieving team success as it enhances individual skills, fosters effective communication, and promotes a shared understanding of goals. Methods: Choose an effective training approach.
Training for Team Members: Team Success Through Training Gyrus Systems Gyrus Systems - Best Online Learning Management Systems Training for team members is important for achieving team success as it enhances individual skills, fosters effective communication, and promotes a shared understanding of goals. Keep reading.
A coalition of AI researchers, data scientists, and sociologists has called on the academic world to stop publishing studies that claim to predict an individual’s criminality using algorithms trained on data like facial scans and criminal statistics. Algorithms trained on racist data produce racist results.
The US Federal Trade Commission has warned companies against using biased artificial intelligence, saying they may break consumer protection laws. If those tools are applied in areas like housing or employment, falsely advertised as unbiased, or trained on data that is gathered deceptively, the agency says it could intervene. “In
We organize all of the trending information in your field so you don't have to. Join 12,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content