This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Apple plans to start using images it collects for Maps to train its AI models. In a disclosure spotted by 9to5Mac , the company said starting this month it would use images it captures to provide its Look Around feature for the additional purpose of training some of its generative AI models.
Pinterest has updated itsprivacy policy to reflect its use of platform user data and images to train AItools. In other words, it seems that any piece of content, published at any point in the social media site's long history it's been around since 2010 is subject to being fed into an AI model.
Under the hood of every AI application are algorithms that churn through data in their own language, one based on a vocabulary of tokens. AI models process tokens to learn the relationships between them and unlock capabilities including prediction, generation and reasoning. What Is Tokenization? This process is known as tokenization.
Leading artificial intelligence firms including OpenAI, Microsoft, and Meta are turning to a process called distillation in the global race to create AI models that are cheaper for consumers and businesses to adopt. Read full article Comments
One of the most frustrating things about using a large languagemodel is dealing with its tendency to confabulate information , hallucinating answers that are not supported by its training data.
Last Updated on May 19, 2023 Large languagemodels (LLMs) are recent advances in deep learning models to work on human languages. A large languagemodel is a trained deep-learning model that understands and generates text in a human-like fashion.
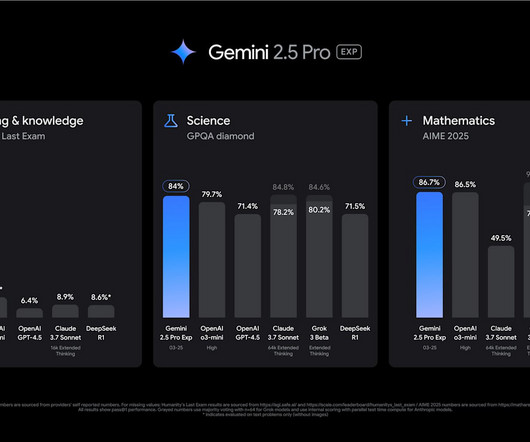
The first model in this series is Gemini 2.5 Google said this is a thinking model that's intended to provide responses grounded in more reasoning, analysis and context than the answers offered by classification- and prediction-driven models. particularly its capabilities in coding, mathematics and science. Pro Experimental.
On Wednesday, the AI lab announced two new Gemini-based models it says will "lay the foundation for a new generation of helpful robots." The first involves a robot's flexibility to adapt to novel situations, including ones not covered by its training. Since its debut at the end of last year, Gemini 2.0
In general, models’ success at in-context learning is enabled by: Their use of semantic prior knowledge from pre-training to predict labels while following the format of in-context examples (e.g., Flipped-label ICL uses flipped labels, forcing the model to override semantic priors in order to follow the in-context examples.
Posted by Yu Zhang, Research Scientist, and James Qin, Software Engineer, Google Research Last November, we announced the 1,000 Languages Initiative , an ambitious commitment to build a machine learning (ML) model that would support the world’s one thousand most-spoken languages, bringing greater inclusion to billions of people around the globe.
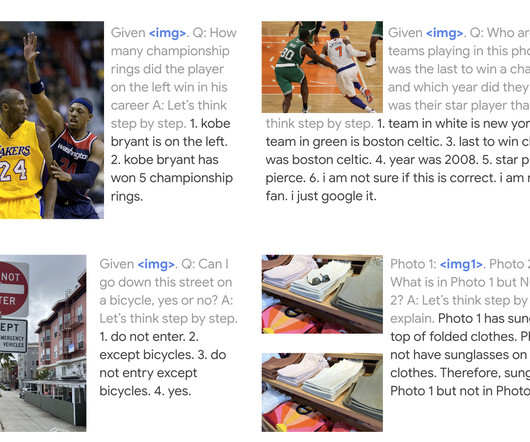
Posted by Danny Driess, Student Researcher, and Pete Florence, Research Scientist, Robotics at Google Recent years have seen tremendous advances across machine learning domains, from models that can explain jokes or answer visual questions in a variety of languages to those that can produce images based on text descriptions.
Transform modalities, or translate the world’s information into any language. I will begin with a discussion of language, computer vision, multi-modal models, and generative machine learning models. We want to solve complex mathematical or scientific problems. Diagnose complex diseases, or understand the physical world.
Previously, the stunning intelligence gains that led to chatbots such ChatGPT and Claude had come from supersizing models and the data and computing power used to train them. o1 required more time to produce answers than other models, but its answers were clearly better than those of non-reasoning models.
Posted by Ziniu Hu, Student Researcher, and Alireza Fathi, Research Scientist, Google Research, Perception Team Large-scale models, such as T5 , GPT-3 , PaLM , Flamingo and PaLI , have demonstrated the ability to store substantial amounts of knowledge when scaled to tens of billions of parameters and trained on large text and image datasets.
Like the prolific jazz trumpeter and composer, researchers have been generating AI models at a feverish pace, exploring new architectures and use cases. In a 2021 paper, researchers reported that foundation models are finding a wide array of uses. Earlier neural networks were narrowly tuned for specific tasks. See chart below.)
universities, however, have taken a more rigorous approach , identifying linguistic fingerprints that reveal which large languagemodel (LLM) produced a given text. By training a machine learning classifier to do this task, and by looking at the performance of that classifier, we can then assess the difference between different LLMs.
” The tranche, co-led by General Catalyst and Andreessen Horowitz, is a big vote of confidence in Hippocratic’s technology, a text-generating model tuned specifically for healthcare applications. “The languagemodels have to be safe,” Shah said. But can a languagemodel really replace a healthcare worker?
2024 is going to be a huge year for the cross-section of generative AI/large foundational models and robotics. There’s a lot of excitement swirling around the potential for various applications, ranging from learning to product design. Google’s DeepMind Robotics researchers are one of a number of teams exploring the space’s potential.
Languagemodels like GPT-4 and Claude are powerful and useful, but the data on which they are trained is a closely guarded secret. Dolma, as the dataset is called, is intended to be the basis for the research group’s planned open languagemodel, or OLMo (Dolma is short for “Data to feed OLMo’s Appetite).
Stability AI , the startup behind the generative AI art tool Stable Diffusion , today open-sourced a suite of text-generating AI models intended to go head to head with systems like OpenAI’s GPT-4. But Stability AI claims it created a custom training set that expands the size of the standard Pile by 3x. make up) facts.
Learning advanced concepts of LLMs includes a structured, stepwise approach that includes concepts, models, training, and optimization as well as deployment and advanced retrieval methods. This roadmap presents a step-by-step method to gain expertise in LLMs.
Its been gradual, but generative AI models and the apps they power have begun to measurably deliver returns for businesses. Google DeepMind put drug discovery ahead by years when it improved on its AlphaFold model, which now can model and predict the behaviors of proteins and other actors within the cell.
Posted by Tal Schuster, Research Scientist, Google Research Languagemodels (LMs) are the driving force behind many recent breakthroughs in natural language processing. Models like T5 , LaMDA , GPT-3 , and PaLM have demonstrated impressive performance on various language tasks.
That light-hearted description probably isn’t worthy of the significance of this advanced language technology’s entrance into the public market. It’s built on a neural network architecture known as a transformer, which enables it to handle complex natural language tasks effectively.
Types of AI Tools To start, it’s important to know about some of the models already available to the public. The most popular model today is called a Large LanguageModel (LLM) , which is trained on massive text datasets. LLMs are meant to produce conversational human language responses.
OpenAI released a new base model on Thursday called GPT-4.5, which the company said is its best and smartest model for chat yet. Its not a reasoning model like OpenAIs o1 and o3 models, but it can be used to train other models to be reasoning models. Notably, GPT-4.5 Notably, GPT-4.5
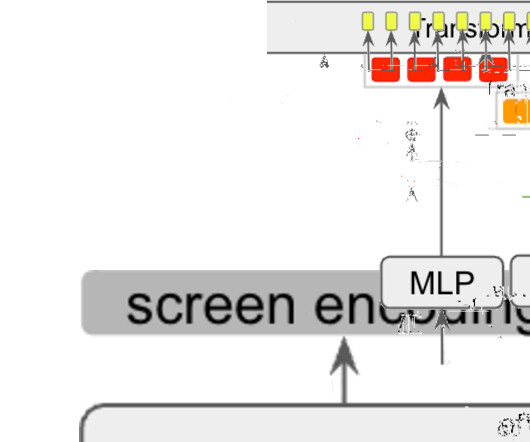
Previously, we investigated various UI modeling tasks, including widget captioning , screen summarization , and command grounding , that address diverse interaction scenarios such as automation and accessibility. As our first attempt to answer this question, we developed a multi-task model to address a range of UI tasks simultaneously.
Called Fixie , the firm, founded by former engineering heads at Apple and Google, aims to connect text-generating models similar to OpenAI’s ChatGPT to an enterprise’s data, systems and workflows. Natural language can act as a lingua franca for diverse computing systems to talk to each other.”
2023 was very much the year of the large languagemodel. OpenAI’s GPT models , Meta’s Llama , Google’s PaLM , and Anthropic’s Claude 2 are all large languagemodels, or LLMs, with many billions of parameters, trained on content from the internet, and used to generate text and code.
Building robots that are proficient at navigation requires an interconnected understanding of (a) vision and natural language (to associate landmarks or follow instructions), and (b) spatial reasoning (to connect a map representing an environment to the true spatial distribution of objects).
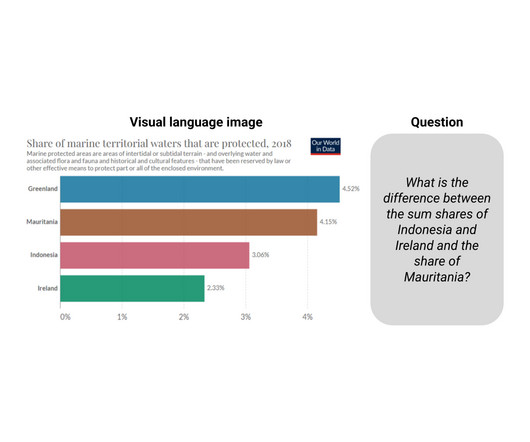
Posted by Julian Eisenschlos, Research Software Engineer, Google Research Visual language is the form of communication that relies on pictorial symbols outside of text to convey information. However, visual language has not garnered a similar level of attention, possibly because of the lack of large-scale training sets in this space.
The heated race to develop and deploy new large languagemodels and AI products has seen innovation surgeand revenue soarat companies supporting AI infrastructure. Lambda Labs new 1-Click service provides on-demand, self-serve GPU clusters for large-scale modeltraining without long-term contracts. billion, a 33.9%
To help address this challenge, NVIDIA today announced at the GTC global AI conference that its partners are developing new large telco models (LTMs) and AI agents custom-built for the telco industry using NVIDIA NIM and NeMo microservices within the NVIDIA AI Enterprise software platform.
The newest reasoning models from top AI companies are already essentially human-level, if not superhuman, at many programming tasks , which in turn has already led new tech startups to hire fewer workers. Fast AI progress, slow robotics progress If youve heard of OpenAI, youve heard of its languagemodels: GPTs 1, 2, 3, 3.5,
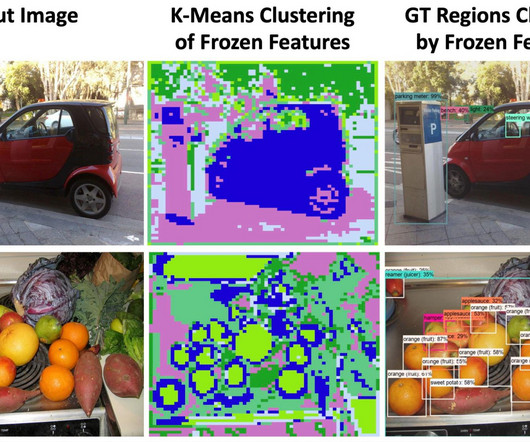
Recent vision and languagemodels (VLMs), such as CLIP , have demonstrated improved open-vocabulary visual recognition capabilities through learning from Internet-scale image-text pairs. We explore the potential of frozen vision and language features for open-vocabulary detection.
Along with access to the latest version, ChatGPT 4 Turbo, which is the most intelligent model available at the time of writing, it also provides access to an array of additional tools. Additionally, nonprofits can create their own custom-trained GPT chatbot with their custom data. The ChatGPT Plus Plan offers immense value.
Introduction Training large languagemodels (LLMs) is an involved process that requires planning, computational resources, and domain expertise. This article aims to identify five common mistakes to avoid when training […] This article aims to identify five common mistakes to avoid when training […]
ChatGPT is a large languagemodel within the family of generative AI systems. ChatGPT , from OpenAI, is a large languagemodel within the family of generative AI systems. GPT is short for Generative Pre-Trained Transformer. LLMs undergo a rigorous “training period.” It was launched in November 2022.
Google describes Robotics Transformer 2, or RT-2 for short, as a vision-language-action (VLA) model. The new AI model was trained on text and images collected from the web, allowing it to generate "robotic actions." Read Entire Article
interim CEO of the American Cancer Society & American Cancer Society Cancer Action Network; Joanne Pike, president and CEO of the Alzheimers Association; and, Susannah Schaefer, president and CEO of Smile Train. Technology is in our DNA, said Schaefer of Smile Train. Frederick, M.D., she asked rhetorically.
What are the chances you'd get a fully functional languagemodel by randomly guessing the weights? We find that the probability of sampling a network at random or local volume for short decreases exponentially as the network is trained. Published on March 1, 2025 2:11 AM GMT (adapted from Nora's tweet thread here.)
” Its response neatly explained the nitty-gritty: “ ChatGPT is a large languagemodel (LLM) developed by OpenAI. It is trained on a massive dataset of text and code, and it can generate text, translate languages, write different kinds of creative content, and answer your questions in an informative way.
To help generative AI tools answer questions beyond the information in their training data, AI companies have recently used a technique called retrieval-augmented generation , or RAG. Then, that information is fed to the underlying AI model along with the user’s query and any other instructions, so it can use it to formulate a response.
Published on March 11, 2025 3:57 PM GMT TL;DR Large languagemodels have demonstrated an emergent ability to write code, but this ability requires an internal representation of program semantics that is little understood. In this work, we study how large languagemodels represent the nullability of program values.
We organize all of the trending information in your field so you don't have to. Join 12,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content