This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Scientists everywhere can now access Evo 2, a powerful new foundation model that understands the genetic code for all domains of life. The NVIDIA NIM microservice for Evo 2 enables users to generate a variety of biological sequences, with settings to adjust model parameters.
Many beginners will initially rely on the train-test method to evaluate their models. This method is straightforward and seems to give a clear indication of how well a model performs on unseen data. However, this approach can often lead to an incomplete understanding of a model’s capabilities.
Previously, the stunning intelligence gains that led to chatbots such ChatGPT and Claude had come from supersizing models and the data and computing power used to train them. o1 required more time to produce answers than other models, but its answers were clearly better than those of non-reasoning models.
Perhaps your organization is one of those tradition-bound groups with a history that has been a decades-long cast iron model for culture, governance, and operations. Evaluate the Road Ahead As the oracle of data, AI gives you an unprecedented ability to predict environmental shifts. Maybe you are not keen on becoming a butterfly.
Further, TGIE represents a substantial opportunity to improve training of foundational models themselves. We also introduce EditBench , a method that gauges the quality of image editing models. The model meaningfully incorporates the user’s intent and performs photorealistic edits. CogView2 ).
In general, models’ success at in-context learning is enabled by: Their use of semantic prior knowledge from pre-training to predict labels while following the format of in-context examples (e.g., Flipped-label ICL uses flipped labels, forcing the model to override semantic priors in order to follow the in-context examples.
Posted by Ziniu Hu, Student Researcher, and Alireza Fathi, Research Scientist, Google Research, Perception Team Large-scale models, such as T5 , GPT-3 , PaLM , Flamingo and PaLI , have demonstrated the ability to store substantial amounts of knowledge when scaled to tens of billions of parameters and trained on large text and image datasets.
It’s only as good as the models and data used to train it, so there is a need for sourcing and ingesting ever-larger data troves. But annotating and manipulating that training data takes a lot of time and money, slowing down the work or overall effectiveness, and maybe both. V7’s specific USP is automation.
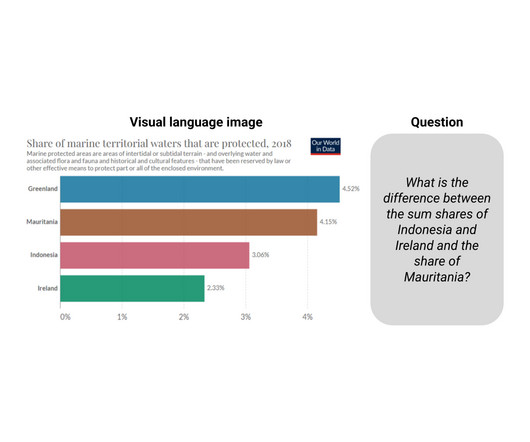
However, visual language has not garnered a similar level of attention, possibly because of the lack of large-scale training sets in this space. But over the last few years, new academic datasets have been created with the goal of evaluating question answering systems on visual language images, like PlotQA , InfographicsVQA , and ChartQA.
Posted by Danny Driess, Student Researcher, and Pete Florence, Research Scientist, Robotics at Google Recent years have seen tremendous advances across machine learning domains, from models that can explain jokes or answer visual questions in a variety of languages to those that can produce images based on text descriptions.
I will begin with a discussion of language, computer vision, multi-modal models, and generative machine learning models. Language Models The progress on larger and more powerful language models has been one of the most exciting areas of machine learning (ML) research over the last decade. Let’s get started!
Posted by Thibault Sellam, Research Scientist, Google Previously, we presented the 1,000 languages initiative and the Universal Speech Model with the goal of making speech and language technologies available to billions of users around the world. Such evaluation is a major bottleneck in the development of multilingual speech systems.
Some applications of deep learning models are to solve regression or classification problems. In this post, you will discover how to use PyTorch to develop and evaluate neural network models for binary classification problems.
” The tranche, co-led by General Catalyst and Andreessen Horowitz, is a big vote of confidence in Hippocratic’s technology, a text-generating model tuned specifically for healthcare applications. “The language models have to be safe,” Shah said. But can a language model really replace a healthcare worker?
Pre-training on diverse datasets has proven to enable data-efficient fine-tuning for individual downstream tasks in natural language processing (NLP) and vision problems. So, we ask the question: Can we enable similar pre-training to accelerate RL methods and create a general-purpose “backbone” for efficient RL across various tasks?
Posted by Fabian Pedregosa and Eleni Triantafillou, Research Scientists, Google Deep learning has recently driven tremendous progress in a wide array of applications, ranging from realistic image generation and impressive retrieval systems to language models that can hold human-like conversations.
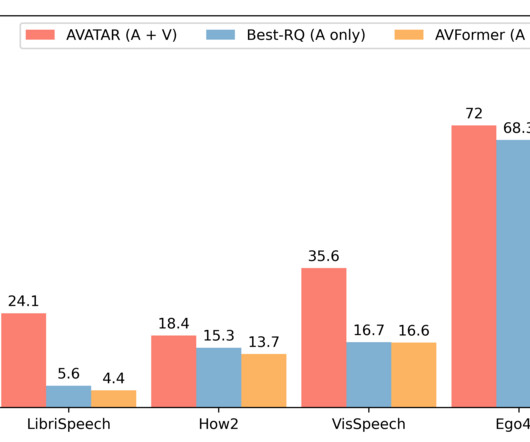
Building audiovisual datasets for training AV-ASR models, however, is challenging. In contrast, the models themselves are typically large and consist of both visual and audio encoders, and so they tend to overfit on these small datasets. LibriSpeech ). LibriSpeech ). Unconstrained audiovisual speech recognition.
AI is now mainstream and driving unprecedented demand for AI factories purpose-built infrastructure dedicated to AI training and inference and the production of intelligence. Model real-world conditions Predict and test how different AI workloads will impact cooling, power stability and network congestion.
Alongside GPT-4 , OpenAI has open sourced a software framework to evaluate the performance of its AI models. Called Evals , OpenAI says that the tooling will allow anyone to report shortcomings in its models to help guide improvements. It’s a sort of crowdsourcing approach to model testing, OpenAI explains in a blog post.
Using predictive models – predictive modeling typically uses 3 -5 years of historical data. 2020 and 2021 are not true representations of typical behavior and would skew your model. Consider both hard and hidden costs when evaluating your events. Don’t forget to look at costs.
Its been gradual, but generative AI models and the apps they power have begun to measurably deliver returns for businesses. Google DeepMind put drug discovery ahead by years when it improved on its AlphaFold model, which now can model and predict the behaviors of proteins and other actors within the cell.
In fact, training a single advanced AI model can generate carbon emissions comparable to the lifetime emissions of a car. And with the rapid advancement of generative AI models potentially slowing down , this provides a unique opportunity to take a breath and reimagine and mature our approach.
ChatGPT is a large language model within the family of generative AI systems. ChatGPT , from OpenAI, is a large language model within the family of generative AI systems. GPT is short for Generative Pre-Trained Transformer. LLMs undergo a rigorous “training period.” In addition, training an AI is complex and expensive.
Posted by Tal Schuster, Research Scientist, Google Research Language models (LMs) are the driving force behind many recent breakthroughs in natural language processing. Models like T5 , LaMDA , GPT-3 , and PaLM have demonstrated impressive performance on various language tasks. The encoder reads the input text (e.g.,
It may feel intimidating at first, but here’s the exciting part: today, more than ever, nonprofits have the tools and resources to make a smooth shift to the grants-plus-fundraising model. Adding fundraising to your funding model gives you the agility to stay mission-focused no matter what comes your way.
Posted by Shekoofeh Azizi, Senior Research Scientist, and Laura Culp, Senior Research Engineer, Google Research Despite recent progress in the field of medical artificial intelligence (AI), most existing models are narrow , single-task systems that require large quantities of labeled data to train.
BayesOpt is a great strategy for these problems because they all involve optimizing black-box functions that are expensive to evaluate. However, we can attempt to understand its internal workings by evaluating the function for different combinations of inputs.
Companies face several hurdles in creating text-, audio- and image-analyzing AI models for deployment across their apps and services. Cost is an outsize one — training a single model on commercial hardware can cost tens of thousands of dollars, if not more. ” Image Credits: Deci.
Recent vision and language models (VLMs), such as CLIP , have demonstrated improved open-vocabulary visual recognition capabilities through learning from Internet-scale image-text pairs. The category text embeddings are obtained by feeding the category names through the text model of pretrained VLM (which has both image and text models)r.
Today, we describe applying recent advances of large sequence models in a real-world setting to automatically resolve code review comments in the day-to-day development workflow at Google (publication forthcoming). Predicting the code edit We started by training a model that predicts code edits needed to address reviewer comments.
Lego is another company that has consistently expanded its business model. Some models are more focused on individuals and others on groups and culture. Investigate training options and keep the various learning styles of your team in mind. Ask questions that invite self-evaluation. Build EI from the inside with training.
Posted by Shunyu Yao, Student Researcher, and Yuan Cao, Research Scientist, Google Research, Brain Team Recent advances have expanded the applicability of language models (LM) to downstream tasks. On the other hand, recent work uses pre-trained language models for planning and acting in various interactive environments (e.g.,
With the release of the FRMT data and accompanying evaluation code, we hope to inspire and enable the research community to discover new ways of creating MT systems that are applicable to the large number of regional language varieties spoken worldwide. Pearson correlation coefficient , ρ ) is comparable to the inter-annotator consistency (0.70
Capital Campaign Models: 4 Categories Many nonprofits think of capital campaigns as major initiatives only used to fund the construction of new buildings. While this is often true, there are other, more flexible use cases for the capital campaign model. But remember that flexibility is key—other objectives can be included, as well.
A Compliance Learning Management System (LMS) is a comprehensive digital platform meticulously crafted to administer, deliver, track, and report on compliance training initiatives within organizations. Certifications Provides verifiable evidence of training completion through certificates with expiration dates and re-certification reminders.
Tanmay Chopra Contributor Share on Twitter Tanmay Chopra works in machine learning at AI search startup Neeva , where he wrangles language models large and small. Last summer could only be described as an “AI summer,” especially with large language models making an explosive entrance. Let’s start with buying.
Although most small to mid-sized groups probably do not have the resources to hire a dedicated customer experience professional to evaluate those activities. Intention, education, and training give teams a broader perspective. Provide training to everyone. Martin described the benefits like this.
In “ A deep learning model for novel systemic biomarkers in photos of the external eye: a retrospective study ”, published in Lancet Digital Health , we show that a number of systemic biomarkers spanning several organ systems (e.g., A model generating predictions for an external eye photo. blood pressure).
It usually involves a cross-functional team of ML practitioners who fine-tune the models, evaluate robustness, characterize strengths and weaknesses, inspect performance in the end-use context, and develop the applications. Participants could not quickly and interactively alter the input data or tune the model.
Language generation is the hottest thing in AI right now, with a class of systems known as “large language models” (or LLMs) being used for everything from improving Google’s search engine to creating text-based fantasy games. One key finding of the paper is that the progress and capabilities of large language models is still increasing.
Published on March 13, 2025 7:18 PM GMT We study alignment audits systematic investigations into whether an AI is pursuing hidden objectivesby training a model with a hidden misaligned objective and asking teams of blinded researchers to investigate it. As a testbed, we train a language model with a hidden objective.
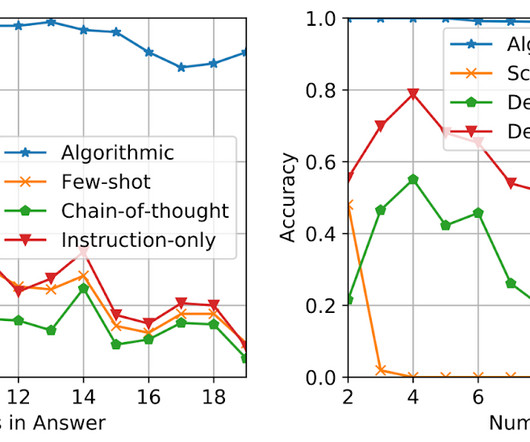
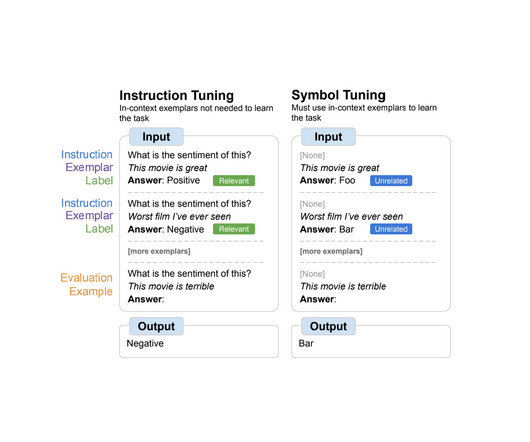
Posted by Hattie Zhou, Graduate Student at MILA, Hanie Sedghi, Research Scientist, Google Large language models (LLMs), such as GPT-3 and PaLM , have shown impressive progress in recent years, which have been driven by scaling up models and training data sizes. manipulating symbols based on logical rules).
Scaling up language models has unlocked a range of new applications and paradigms in machine learning, including the ability to perform challenging reasoning tasks via in-context learning. Language models, however, are still sensitive to the way that prompts are given, indicating that they are not reasoning in a robust manner.
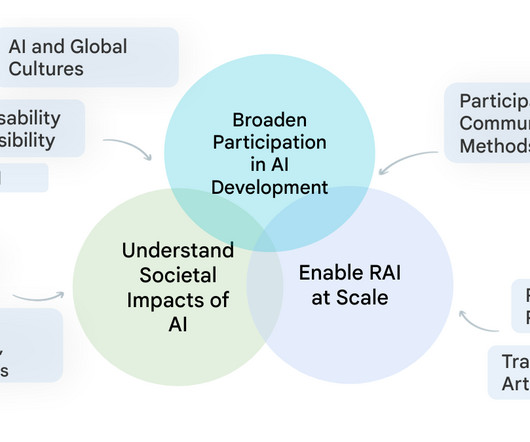
Our work advances Responsible AI (RAI) in areas such as computer vision , natural language processing , health , and general purpose ML models and applications. Community engagement enables us to shift how we incorporate knowledge of what’s most important throughout this pipeline, from dataset curation to evaluation.
We organize all of the trending information in your field so you don't have to. Join 12,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















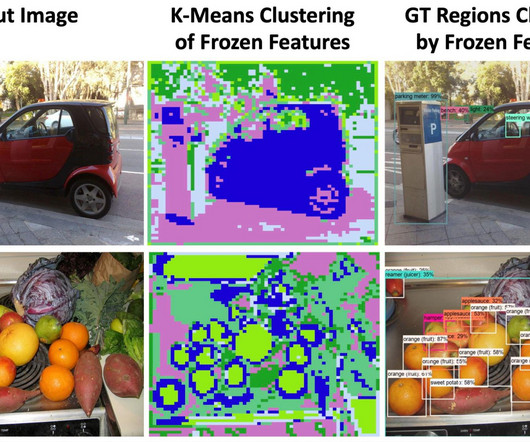


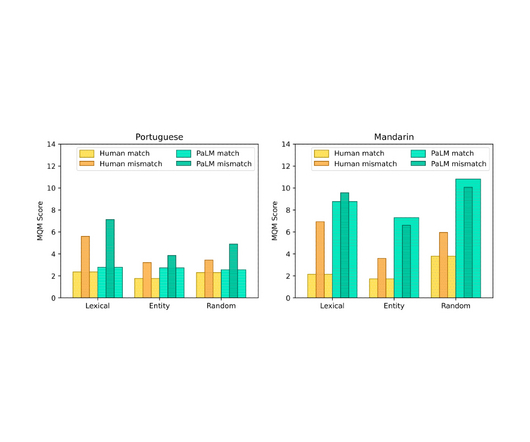




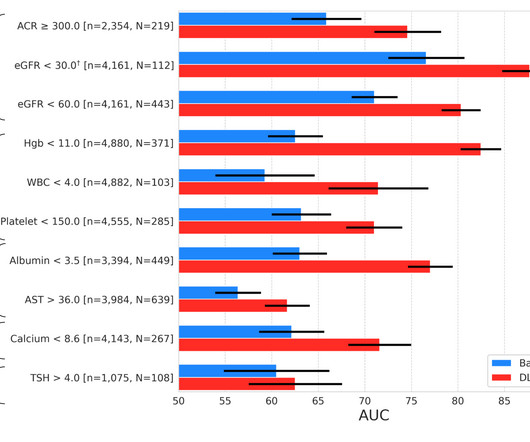








Let's personalize your content