This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
TLDR : Our new paper outlines how AI developers should adapt the methodology used in control evaluations as capabilities of LLM agents increase. Figure : We sketch a trajectory of how control evaluations might evolve through increasingly powerful capability profiles. How can AI control techniques scale to increasingly capable systems?
Using the ADDIE for designing your workshop, you arrive at the “E” or evaluation. ” While a participant survey is an important piece of your evaluation, it is critical to incorporate a holistic reflection of your workshop. There are two different methods to evaluate your training. Formative Evaluation.
Here’s a few frameworks and techniques I learned first hand from Nancy as she accompanied me to the sessions I was leading. It is about simply learning how to use a new tool or technique. Nancy used the phrase “pre-contemplation” and “contemplation” stages of behavior change and introduce me to a behavior change framework.
The conference was framed around the question: Given the convergence of networks and big data and the need for more innovation, what evaluation methods should be used to evaluate social change outcomes along side traditional methods? I followed the developmental evaluation thread most closely. Here are my notes.
Further, TGIE represents a substantial opportunity to improve training of foundational models themselves. We also introduce EditBench , a method that gauges the quality of image editing models. The model meaningfully incorporates the user’s intent and performs photorealistic edits. First, unlike prior inpainting models (e.g.,
In general, models’ success at in-context learning is enabled by: Their use of semantic prior knowledge from pre-training to predict labels while following the format of in-context examples (e.g., Flipped-label ICL uses flipped labels, forcing the model to override semantic priors in order to follow the in-context examples.
I will begin with a discussion of language, computer vision, multi-modal models, and generative machine learning models. Language Models The progress on larger and more powerful language models has been one of the most exciting areas of machine learning (ML) research over the last decade. Let’s get started!
AWS’ new theory on designing an automated RAG evaluation mechanism could not only ease the development of generative AI-based applications but also help enterprises reduce spending on compute infrastructure.
However, today’s startups need to reconsider the MVP model as artificial intelligence (AI) and machine learning (ML) become ubiquitous in tech products and the market grows increasingly conscious of the ethical implications of AI augmenting or replacing humans in the decision-making process. Find an ethics officer to lead the charge.
In most of our research and writing on AI control, weve emphasized the following situation: The AI developer is deploying a model that they think might be scheming, but they arent sure. The objective of the safety team is to ensure that if the model is scheming, it will be caught before successfully causing a catastrophe.
Companies face several hurdles in creating text-, audio- and image-analyzing AI models for deployment across their apps and services. Cost is an outsize one — training a single model on commercial hardware can cost tens of thousands of dollars, if not more. Geifman proposes neural architecture search (NAS) as a solution.
Published on February 19, 2025 12:39 PM GMT With many thanks to Sasha Frangulov for comments and editing Before publishing their o1-preview model system card on Sep 12, 2024, OpenAI tested the model on various safety benchmarks which they had constructed. To test this, we decided to use the ProtocolQA benchmark from LabBench.
Tanmay Chopra Contributor Share on Twitter Tanmay Chopra works in machine learning at AI search startup Neeva , where he wrangles language models large and small. Last summer could only be described as an “AI summer,” especially with large language models making an explosive entrance. Let’s start with buying.
Dubbed “constitutional AI,” Anthropic argues its technique, which aims to imbue systems with “values” defined by a “constitution,” makes the behavior of systems both easier to understand and simpler to adjust as needed. Neither model looks at every principle every time. Perhaps not.
Addressing the Key Mandates of a Modern Model Risk Management Framework (MRM) When Leveraging Machine Learning . The regulatory guidance presented in these documents laid the foundation for evaluating and managing model risk for financial institutions across the United States.
In the midst of an artificial intelligence boom thats reshaping almost every facet of the business world, companies are competing in an arms race to build the best and brightest models and fully embrace the nascent technology, whether thats as a product or service for customers or as an integralcomponent of their organizations processes.
This post is divided into three parts; they are: Using DistilBERT Model for Question Answering Evaluating the Answer Other Techniques for Improving the Q&A Capability BERT (Bidirectional Encoder Representations from Transformers) was trained to be a general-purpose language model that can understand text.
Posted by Hattie Zhou, Graduate Student at MILA, Hanie Sedghi, Research Scientist, Google Large language models (LLMs), such as GPT-3 and PaLM , have shown impressive progress in recent years, which have been driven by scaling up models and training data sizes. manipulating symbols based on logical rules).
Last time , we discussed the steps that a modeler must pay attention to when building out ML models to be utilized within the financial institution. In summary, to ensure that they have built a robust model, modelers must make certain that they have designed the model in a way that is backed by research and industry-adopted practices.
Allison Fine and I have been noodling with an evaluationmodel that looks social media from an organizational perspective - from social networks to social capital (relationships) to action in the real world. Now I'm wondering where the techniques of engagement need to be incorporated. Listening is not just a one-way activity.
Published on March 13, 2025 7:18 PM GMT We study alignment audits systematic investigations into whether an AI is pursuing hidden objectivesby training a model with a hidden misaligned objective and asking teams of blinded researchers to investigate it. As a testbed, we train a language model with a hidden objective.
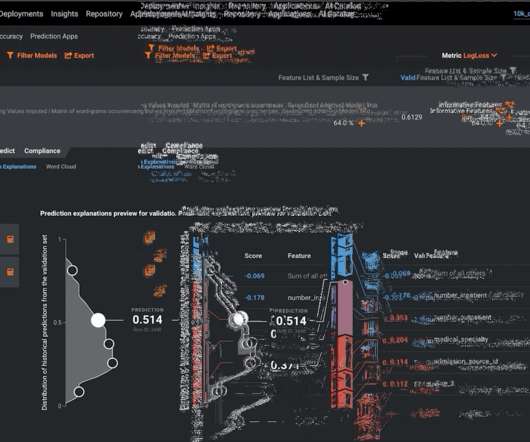
and train models with a single click of a button. Advanced users will appreciate tunable parameters and full access to configuring how DataRobot processes data and builds models with composable ML. Explanations around data, models , and blueprints are extensive throughout the platform so you’ll always understand your results.
I’ve been curating resources on training techniques and capacity building over at scoop.it The model balances content, learning design, and participants. Developmental Evaluation: Applying Complexity Concepts to Enhance Innovation and Use by Michael Quinn Patton. Michael Quinn Patton is the godfather of evaluation.
There are a wealth of theories, ideas, and methods covered, for example the “ SAVI ” model for designing exercises that help learners embrace learning in different styles. This six-step instructional model is called “ENGAGE.” From Analysis to Evaluation: Tools, Tips, and Techniques from Trainers.
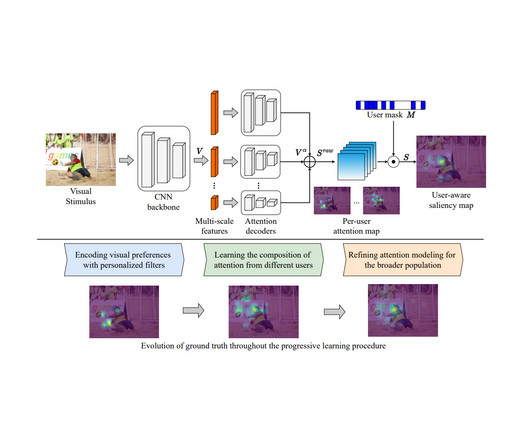
Modeling human attention (the result of which is often called a saliency model) has therefore been of interest across the fields of neuroscience, psychology, human-computer interaction (HCI) and computer vision. Attention-guided image editing Human attention models usually take an image as input (e.g.,
Since networked learning happens in the context of an ecosystem, perhaps Gary Hayes Transmedia Storytelling model or Lini Srivastava’s Transmedia Activism model. . Maybe the scaffolding for learning in public for an evaluation goes something like this: Transparent: This is the first step to make learning products visible.
The most innovative firms in the industry expand this notion, solving pressing issues in new ways that build on or scale up existing techniques and technologies. It also incorporated embodied carbon analysis into Autodesk Insight, an energy modeling tool built to work with its Autodesk Revit building information modeling software.
Specifically, our wildfire tracker models use the GOES-16 and GOES-18 satellites to cover North America, and the Himawari-9 and GK2A satellites to cover Australia. Model Prior work on fire detection from satellite imagery is typically based on physics-based algorithms for identifying hotspots from multispectral imagery. μm and 11.2
Prior research has investigated several important technical building blocks to enable conversational interaction with mobile UIs, including summarizing a mobile screen for users to quickly understand its purpose, mapping language instructions to UI actions and modeling GUIs so that they are more amenable for language-based interaction.
Posted by Jason Wei and Yi Tay, Research Scientists, Google Research, Brain Team In recent years, language models (LMs) have become more prominent in natural language processing (NLP) research and are also becoming increasingly impactful in practice. Scaling up LMs has been shown to improve performance across a range of NLP tasks.
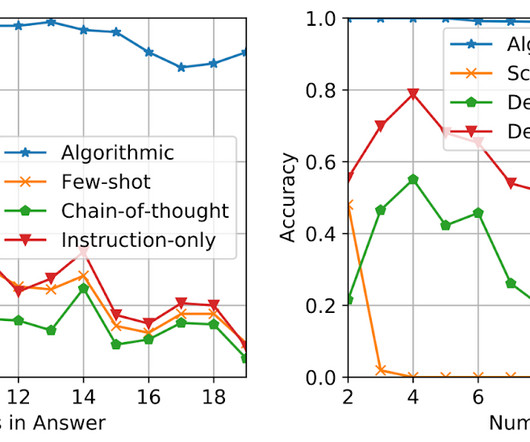
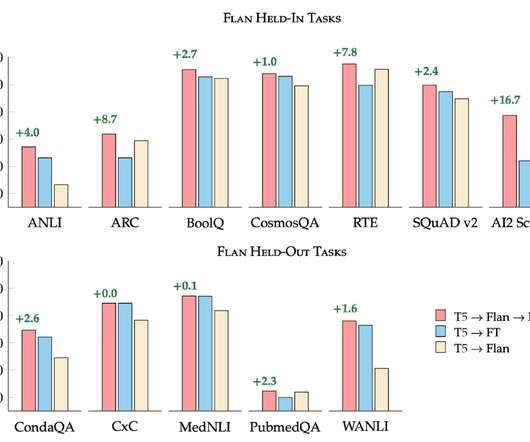
Posted by Shayne Longpre, Student Researcher, and Adam Roberts, Senior Staff Software Engineer, Google Research, Brain Team Language models are now capable of performing many new natural language processing (NLP) tasks by reading instructions, often that they hadn’t seen before. The stars indicate the peak performance in each setting.
2] Generally speaking, we think more usage of AI in the world will lead to good, and want to promote it (by putting models in our API, open-sourcing them, etc.). As our systems get closer to AGI, we are becoming increasingly cautious with the creation and deployment of our models. This makes planning in a vacuum very difficult. [2]
I’ll be doing a session with colleagues Danette Peters and Roberto Cremonini on Outcomes, Impact, and Communication where will not only share some case studies and techniques for outcome-based evaluation, but model some small group facilitation techniques for the process.
How to identify and engage the first customers for your product, and how to gather, evaluate and use their feedback to make your product, marketing and business model far stronger. 3D modeling, rendering and animation by Penn University. Lore (Learn + More), formerly known as CourseKit, has some great courses on deck.
Robust algorithm design is the backbone of systems across Google, particularly for our ML and AI models. We provided a model-based taxonomy that unified many graph learning methods. In addition, we discovered insights for GNN models from their performance across thousands of graphs with varying structure (shown below).
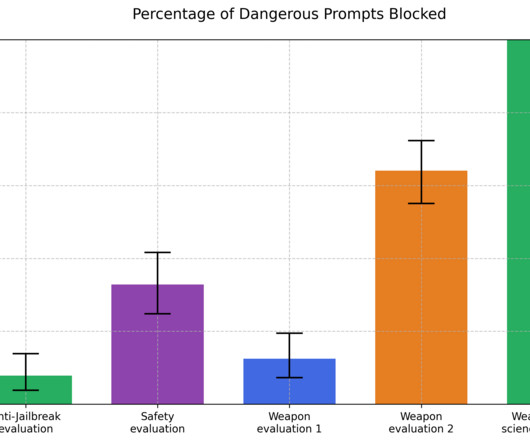
One of the greatest strengths of large language models is their generality. Yet most models are still vulnerable to so-called jailbreaksinputs designed to sidestep these protections. Yet most models are still vulnerable to so-called jailbreaksinputs designed to sidestep these protections.
I’m the lead for Zoetica where my role is to deliver training, advise on the curriculum and coaching methods, model transparency, and serve as meta network weaver. The morning used the World Cafe technique. The world cafe technique is where participants learn through conversation in small groups. Photo by SMEXbeirut.
Descriptions of key digital measurement concepts, terminology and analysis techniques. Deep-dives into Google Analytics reports with specific examples for evaluating your digital marketing performance. It sounds like they have adapted the Khan Academy model. Guidance on how to build an effective measurement plan.
Wednesday, December 1, 2010 How To Avoid 8 Common Performance Evaluation Pitfalls As the year comes to a close its likely time for many business leaders to tackle the annual performance appraisal process. So, here is a good reminder from author Sharon Armstrong about how to avoid eight performance evaluation pitfalls.
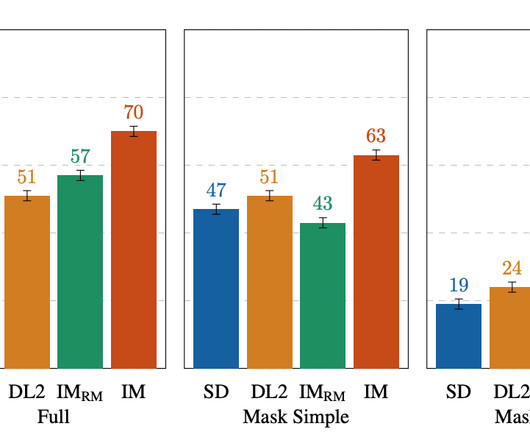
Published on January 31, 2025 3:36 PM GMT This is a linkpost for a new research paper of ours , introducing a simple but powerful technique for preventing Best-of-N jailbreaking. This success persisted even when utilizing smaller LLMs to power the evaluation (Claude and LLaMa-3-8B-instruct proved almost equally capable). It blocks 99.5-100%
Posted by Piotr Padlewski and Josip Djolonga, Software Engineers, Google Research Large Language Models (LLMs) like PaLM or GPT-3 showed that scaling transformers to hundreds of billions of parameters improves performance and unlocks emergent abilities. At first, the new model scale resulted in severe training instabilities.
Your organization needs to think holistically. If you don’t have a developmental model, you won’t know where to start or how to prioritize your time. The Networked Nonprofit Practice Model. Or as Inga Broerman, Guide Star VP of Marketing said, “You won’t know what to say no to.&#.
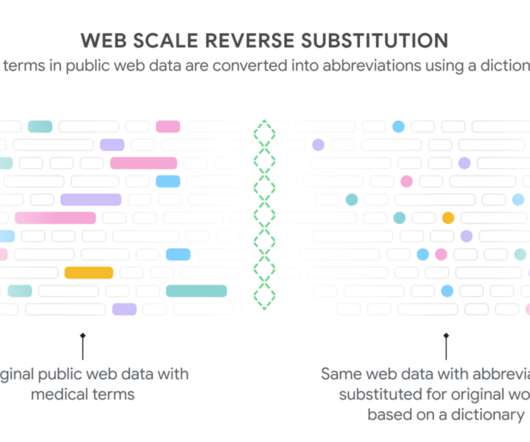
We built the model using only public data on the web that wasn't associated with any patient (i.e., no potentially sensitive data) and evaluated performance on real, de-identified notes from inpatient and outpatient clinicians from different health systems. The model input is a string that may or may not contain medical abbreviations.
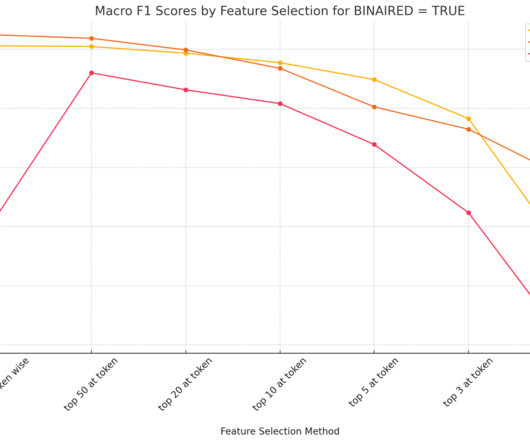
TL;DR: Recent work has evaluated the generalizability of Sparse Autoencoder (SAE) features; this study examines their effectiveness in multimodal settings. We evaluate feature extraction using a CIFAR-100-inspired explainable classification task, analyzing the impact of pooling strategies, binarization, and layer selection on performance.
We organize all of the trending information in your field so you don't have to. Join 12,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content