This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Finance teams can help their nonprofit organizations evaluate new revenue streams, enhancing the organizations stability and mitigating risk while intentionally experimenting with varied income sources. Verify Feasibility Once you confirm that the opportunity aligns with your mission, evaluate the feasibility of launching it.
Scientists everywhere can now access Evo 2, a powerful new foundation model that understands the genetic code for all domains of life. The NVIDIA NIM microservice for Evo 2 enables users to generate a variety of biological sequences, with settings to adjust model parameters.
Designing a deep learning model is sometimes an art. One way to come up with a design is by trial and error and evaluating the result on real data. Therefore, it is important to have a scientific […] The post How to Evaluate the Performance of PyTorch Models appeared first on MachineLearningMastery.com.
By actively bringing together different departments and leading discussions around revenue diversification, you can set measurable goals, evaluate the ROI of each funding source, and make informed decisions about where to invest time and resources. How to Measure: Evaluate cost per dollar raised, donor acquisition costs, and conversion rates.
You are ready to add new categories of membership, sell products to a different audience, expand programs, or even revise the business model. You can take baby steps and evaluate which strategies are successful and which are not. The post <strong>Flat, Tall, or In Between—Is It Time to Evaluate Your Organizational Structure?</strong>
TLDR : Our new paper outlines how AI developers should adapt the methodology used in control evaluations as capabilities of LLM agents increase. Figure : We sketch a trajectory of how control evaluations might evolve through increasingly powerful capability profiles. What are the advantages of AI control?
By OpenAI 's own testing, its newest reasoning models, o3 and o4 -mini, hallucinate significantly higher than o1. First reported by TechCrunch , OpenAI's system card detailed the PersonQA evaluation results, designed to test for hallucinations. ” Evaluation benchmarks are tricky. GPT-4o scored 1.5 percent, GPT-4.5
Some applications of deep learning models are to solve regression or classification problems. In this post, you will discover how to use PyTorch to develop and evaluate neural network models for regression problems.
Some applications of deep learning models are to solve regression or classification problems. In this tutorial, you will discover how to use PyTorch to develop and evaluate neural network models for multi-class classification problems. PyTorch library is for deep learning.
Further, TGIE represents a substantial opportunity to improve training of foundational models themselves. We also introduce EditBench , a method that gauges the quality of image editing models. The model meaningfully incorporates the user’s intent and performs photorealistic edits. First, unlike prior inpainting models (e.g.,
Before Eric Landau co-founded Encord , he spent nearly a decade at DRW, where he was lead quantitative researcher on a global equity delta one desk and put thousands of models into production. Below are four factors that founders should consider when deciding to build computer vision models. He holds an S.M. The moral of the story?
Many beginners will initially rely on the train-test method to evaluate their models. This method is straightforward and seems to give a clear indication of how well a model performs on unseen data. However, this approach can often lead to an incomplete understanding of a model’s capabilities.
Historically, each new generation of OpenAI's models has delivered incremental improvements in factual accuracy, with hallucination rates dropping as the technology matured. Read Entire Article
In general, models’ success at in-context learning is enabled by: Their use of semantic prior knowledge from pre-training to predict labels while following the format of in-context examples (e.g., Flipped-label ICL uses flipped labels, forcing the model to override semantic priors in order to follow the in-context examples.
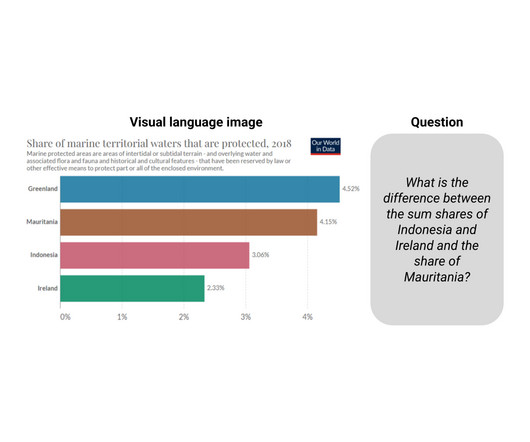
But over the last few years, new academic datasets have been created with the goal of evaluating question answering systems on visual language images, like PlotQA , InfographicsVQA , and ChartQA. To solve questions in DROP, the model needs to read the paragraph, extract relevant numbers and perform numerical computation.
The Mac Studio is Apples ultimate performance computer, but this years model came with a twist: Its equipped with either an M4 Max or an M3 Ultra processor. While the M3 Ultra model appears highly capable for creative pros and engineers, it starts at $4,000 and goes way up from there.
Our comprehensive benchmark and online leaderboard offer a much-needed measure of how accurately LLMs ground their responses in provided source material and avoid hallucinations
Posted by Danny Driess, Student Researcher, and Pete Florence, Research Scientist, Robotics at Google Recent years have seen tremendous advances across machine learning domains, from models that can explain jokes or answer visual questions in a variety of languages to those that can produce images based on text descriptions.
Even with a friendly name like “feedback, check-in, or coaching,” a performance evaluation can be uncomfortable, or possibly downright scary. That’s probably why more organizations don’t have a process for evaluating the board of directors, or if they do, that assessment is not continuous. I’ll get on my Association 4.0
Hooters to transition to franchisee-owned model Most people think of Hooters as just one company, but the restaurant chain currently operates under a hybrid model. That restructuring will see Hooters move from a primarily company-owned model to an entirely franchisee-owned model. The company has no plans to.
I will begin with a discussion of language, computer vision, multi-modal models, and generative machine learning models. Language Models The progress on larger and more powerful language models has been one of the most exciting areas of machine learning (ML) research over the last decade. Let’s get started!
” The tranche, co-led by General Catalyst and Andreessen Horowitz, is a big vote of confidence in Hippocratic’s technology, a text-generating model tuned specifically for healthcare applications. “The language models have to be safe,” Shah said. But can a language model really replace a healthcare worker?
However, today’s startups need to reconsider the MVP model as artificial intelligence (AI) and machine learning (ML) become ubiquitous in tech products and the market grows increasingly conscious of the ethical implications of AI augmenting or replacing humans in the decision-making process.
Although some of todays models can generalize a skill across similar problems, they struggle to transfer those skills across more complex tasks requiring multiple steps. Dubbed reinforcement learning, this process incorporates experiencessuch as yikes, that hurtinto a model of how the world works.
Previously, the stunning intelligence gains that led to chatbots such ChatGPT and Claude had come from supersizing models and the data and computing power used to train them. o1 required more time to produce answers than other models, but its answers were clearly better than those of non-reasoning models.
He ditched radar from Tesla’s production models in 2021, against the criteria of his own engineers ,opting instead for his camera-based AI Tesla Vision system, which relies on cameras and AI alone. Elon Musk has always had it out for Lidar, calling it a a crutch, a losers technology and too expensive.
In a bid to “deepen the public conversation about how AI models should behave,” AI company OpenAI has introduced Model Spec, a document that shares the company’s approach to shaping desired model behavior. Model Spec , now in a first draft, was introduced May 8. To read this article in full, please click here
It’s often said that large language models (LLMs) along the lines of OpenAI’s ChatGPT are a black box, and certainly, there’s some truth to that. Even for data scientists, it’s difficult to know why, always, a model responds in the way it does, like inventing facts out of whole cloth.
AWS’ new theory on designing an automated RAG evaluation mechanism could not only ease the development of generative AI-based applications but also help enterprises reduce spending on compute infrastructure.
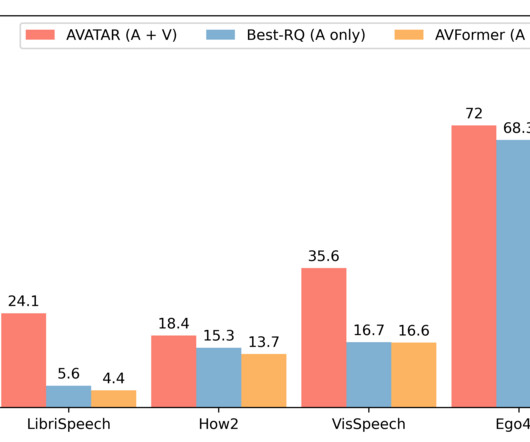
Building audiovisual datasets for training AV-ASR models, however, is challenging. In contrast, the models themselves are typically large and consist of both visual and audio encoders, and so they tend to overfit on these small datasets. LibriSpeech ). LibriSpeech ). Unconstrained audiovisual speech recognition.
To bridge this critical gap, and recognize the current limitations in third-party evaluation ecosystems, Anthropic has started an initiative to invest in the development of robust, safety-relevant benchmarks to assess advanced AI capabilities and risks. “A To read this article in full, please click here
Published on February 19, 2025 12:39 PM GMT With many thanks to Sasha Frangulov for comments and editing Before publishing their o1-preview model system card on Sep 12, 2024, OpenAI tested the model on various safety benchmarks which they had constructed. To test this, we decided to use the ProtocolQA benchmark from LabBench.
In fact, training a single advanced AI model can generate carbon emissions comparable to the lifetime emissions of a car. And with the rapid advancement of generative AI models potentially slowing down , this provides a unique opportunity to take a breath and reimagine and mature our approach.
A spontaneous cruise of the office was an effective strategy for evaluating a variety of business indicators. The desire to be fully aware of the strengths and weaknesses of your team drives this type of evaluation. Evaluate Resources IT deficits equal a rocky road for remote work. Remember Management by Walking Around?
This post is in two parts; they are: Understanding the Encoder-Decoder Architecture Evaluating the Result of Summarization using ROUGE DistilBart is a "distilled" version of the BART model, a powerful sequence-to-sequence model for natural language generation, translation, and comprehension.
It may feel intimidating at first, but here’s the exciting part: today, more than ever, nonprofits have the tools and resources to make a smooth shift to the grants-plus-fundraising model. Adding fundraising to your funding model gives you the agility to stay mission-focused no matter what comes your way.
Posted by Fabian Pedregosa and Eleni Triantafillou, Research Scientists, Google Deep learning has recently driven tremendous progress in a wide array of applications, ranging from realistic image generation and impressive retrieval systems to language models that can hold human-like conversations.
Although the most popular accounting software products- like QuickBooks and SAP- handle the needs of businesses in many industries, nonprofits have a unique business model and accounting standards and require different features and functionality from accounting software. Here are some common requirements that may apply to your organization.
Capital Campaign Models: 4 Categories Many nonprofits think of capital campaigns as major initiatives only used to fund the construction of new buildings. While this is often true, there are other, more flexible use cases for the capital campaign model. But remember that flexibility is key—other objectives can be included, as well.
Vector databases have also seen a surge in usage thanks to the rise of generative AI and large language models (LLMs). However, relational databases remain, by far, the most-used type of databases. With so many options available to organizations, how do they select the right database to serve their business needs?
While the organization still builds the basic models in areas that dont have electricity, most projects are now more complex, using sensors to run automatically and switch between a utility water sourcesuch as a pipe running to a village welland stored rainwater. We were pretty much building gigantic Brita filters, he says.
“AI models will have value systems, whether intentional or unintentional,” writes Anthropic in a blog post published this morning. “Constitutional AI responds to shortcomings by using AI feedback to evaluate outputs.” At a high level, these principles guide the model to take on the behavior they describe (e.g.
We organize all of the trending information in your field so you don't have to. Join 12,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content