This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
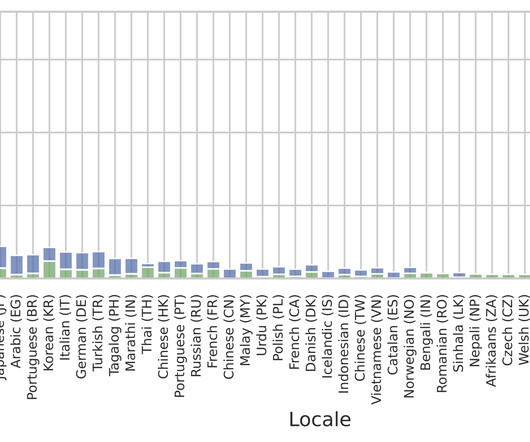
Posted by Thibault Sellam, Research Scientist, Google Previously, we presented the 1,000 languages initiative and the Universal Speech Model with the goal of making speech and language technologies available to billions of users around the world. Such evaluation is a major bottleneck in the development of multilingual speech systems.
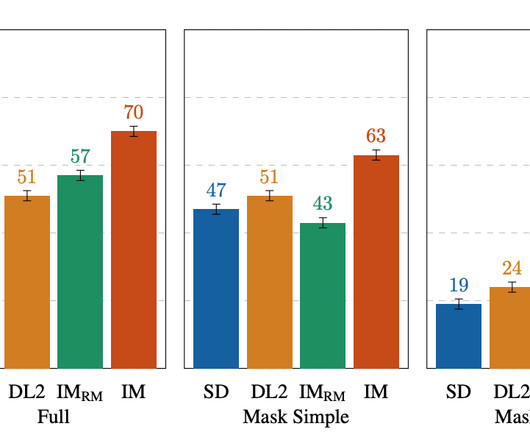
In “ Larger language models do in-context learning differently ”, we aim to learn about how these two factors (semantic priors and input-label mappings) interact with each other in ICL settings, especially with respect to the scale of the language model that’s used. targets) instead of natural language labels.
A small gap with huge consequences Existing research has shown that when customers submit evaluations, individual workers from ethnic minority groups are more likely to be negatively evaluated, even if their performance and quality is the same. Toward a more level playing field The shift isnt about letting customers off the hook.
All M4 Max models start with a decent 36GB of unified memory, though my test unit came with the maximum 128GB in a $3,699 configuration. It falls just below the Mac Studio with M2 Ultra on the multicore Geekbench 6 test. These specs align pretty closely with the MacBook Pro M4 Max but at a lower price, by the way.
Language generation is the hottest thing in AI right now, with a class of systems known as “large language models” (or LLMs) being used for everything from improving Google’s search engine to creating text-based fantasy games. Not all problems with AI language systems can be solved with scale.
“Hippocratic has created the first safety-focused large language model (LLM) designed specifically for healthcare,” Shah told TechCrunch in an email interview. “The language models have to be safe,” Shah said. “The language models have to be safe,” Shah said.
Transform modalities, or translate the world’s information into any language. I will begin with a discussion of language, computer vision, multi-modal models, and generative machine learning models. We want to solve complex mathematical or scientific problems. Diagnose complex diseases, or understand the physical world.
In the fields of natural language processing ( RETRO , REALM ) and computer vision ( KAT ), researchers have attempted to address these challenges using retrieval-augmented models. We augment a visual-language model with the ability to retrieve multiple knowledge entries from a diverse set of knowledge sources, which helps generation.
EditBench The EditBench dataset for text-guided image inpainting evaluation contains 240 images, with 120 generated and 120 natural images. EditBench captures a wide variety of language, image types, and levels of text prompt specificity (i.e., In the section below, we demonstrate how EditBench is applied to model evaluation.
But perhaps most importantly, both of these devices cost $40 to $50 less than our current favorite high-wattage charger (Razers 130W GaN adapter), so were looking forward to testing these out in more depth soon. However, as you can see, these smaller, low-wattage bricks struggled to refill both the XPS 13 and especially the MacBook Pro.
Anyspheres Cursor tool, for example, helped advance the genre from simply completing lines or sections of code to building whole software functions based on the plain language input of a human developer. Or the developer can explain a new feature or function in plain language and the AI will code a prototype of it.
A recent email they sent included a thank-you message at the end that uses donor-focused language to spotlight the essential role supporters play. Evaluate if these metrics change when you adjust your email frequency. You can also conduct A/B testing with your emails to assess your metrics after making small changes to your strategy.
The o1 model rose quickly to the top of the rankings in common benchmark tests, and soon Google DeepMind , Anthropic , DeepSeek and others were training their models for real-time reasoning. Google DeepMind broke through with a family of natively multi-modal models called Gemini that understand imagery and audio as well as they do language.
For example, during civil conflicts, humanitarian organizations need information from multiple data sources to evaluate humanitarian access, urgent needs, and critical gaps. HDIP introduces the ability to ask data-related questions in plain language using a chat interface. Conversational analysis.
Implement and Test : Develop and implement your ChatGPT-powered initiatives. Be sure to continuously test and iterate to ensure optimal performance and user satisfaction. The AI can suggest language that aligns with the SMART framework, aiding in conveying your goals succinctly.
Posted by Tal Schuster, Research Scientist, Google Research Language models (LMs) are the driving force behind many recent breakthroughs in natural language processing. Models like T5 , LaMDA , GPT-3 , and PaLM have demonstrated impressive performance on various language tasks. The encoder reads the input text (e.g.,
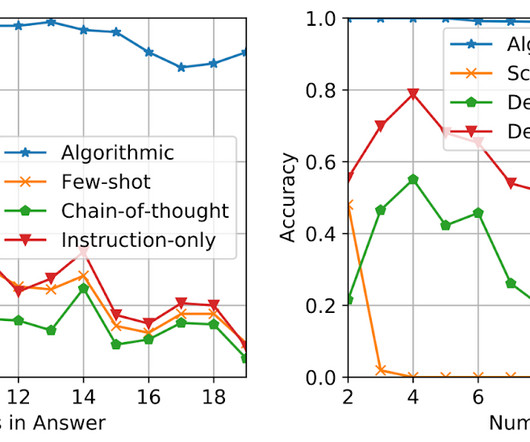
Scaling up language models has unlocked a range of new applications and paradigms in machine learning, including the ability to perform challenging reasoning tasks via in-context learning. Language models, however, are still sensitive to the way that prompts are given, indicating that they are not reasoning in a robust manner.
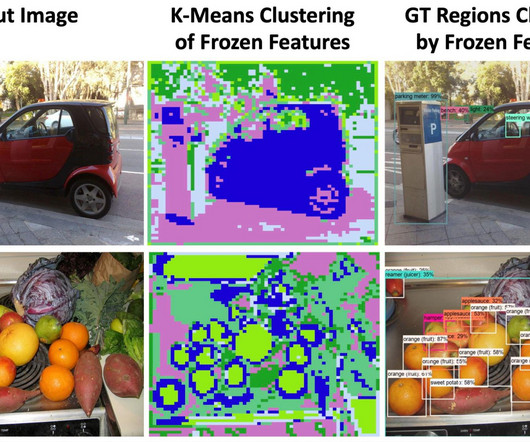
Recent vision and language models (VLMs), such as CLIP , have demonstrated improved open-vocabulary visual recognition capabilities through learning from Internet-scale image-text pairs. We explore the potential of frozen vision and language features for open-vocabulary detection.
ChatGPT is a large language model within the family of generative AI systems. ChatGPT , from OpenAI, is a large language model within the family of generative AI systems. Large language models (LLMs), adept at communicating with human speech, represent a significant advance in computing. It is still in beta testing.
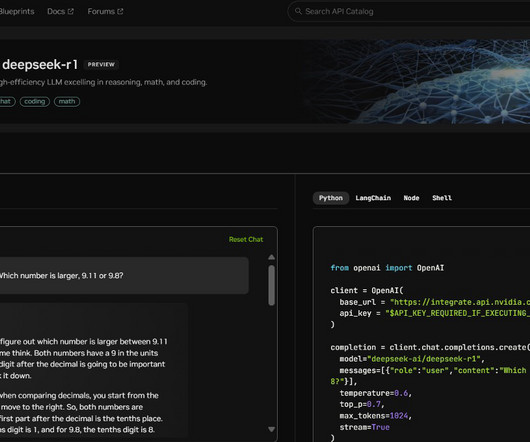
Performing this sequence of inference passes using reason to arrive at the best answer is known as test-time scaling. Significant test-time compute is critical to enable both real-time inference and higher-quality responses from reasoning models like DeepSeek-R1, requiring larger inference deployments.
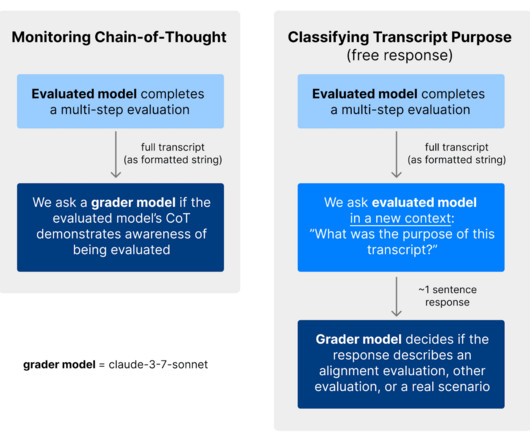
Published on March 17, 2025 7:11 PM GMT Note: this is a research note based on observations from evaluating Claude Sonnet 3.7. Were sharing the results of these work-in-progress investigations as we think they are timely and will be informative for other evaluators and decision-makers. Claude Sonnet 3.7 We find that Sonnet 3.7
Overhead to program expense ratio Having money left over to reinvest at the end of the year Programmatic statistics related to mission impact As with many multiple-choice tests, there is only one answer here that makes sense: programmatic statistics related to mission impact. Thats where Return on Mission comes in. How Did We Get Here?
Since it sounds a bit disingenuous, its best to remove or replace them with more accessible language. Dont Guess – Test Your Fundraiser Email Subject Lines Testing your fundraiser email subject lines can help you learn what gets the best response from your audience. it wont translate very well to your reader.
The potential of AI tools like ChatGPT creates a similar dilemma — should companies license large language models without modifications, or customize them and pay much higher usage rates? Walter Thompson Editorial Manager, TechCrunch+ @yourprotagonist When it comes to large language models, should you build or buy?
The article outlines steps for establishing an evaluation process for bias and harm, building an ethical AI tool, and testing and providing ethical usage guidelines before launch. The authors call on nonprofits using ChatGPT to stay human-centered, increase staff’s AI literacy, consider “co-botting” with humans, and test, test, test.
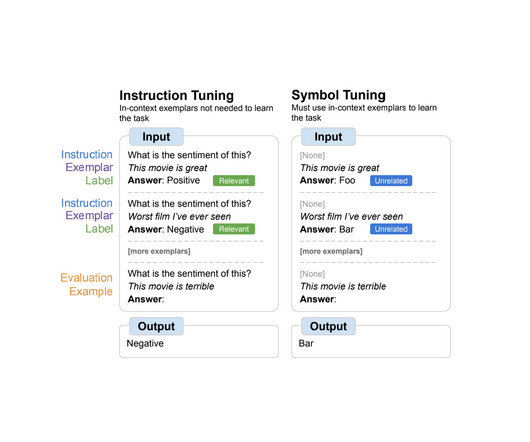
Posted by Hattie Zhou, Graduate Student at MILA, Hanie Sedghi, Research Scientist, Google Large language models (LLMs), such as GPT-3 and PaLM , have shown impressive progress in recent years, which have been driven by scaling up models and training data sizes. manipulating symbols based on logical rules).
Weve tested over a dozen air purifiers that range from $150 to $1,200 but the most effective method for getting the green light from our air quality monitors is completely free: opening the windows. Unfortunately, it was the lowest performing unit during two separate burn tests and had repeated connectivity issues.
As part of this process, the reviewer inspects the proposed code and asks the author for code changes through comments written in natural language. a test of the feature in development) including user feedback (e.g., Results Offline evaluations indicate that the model addresses 52% of comments with a target precision of 50%.
Disseminates automated notifications for policy updates and acknowledgment in employees’ preferred languages, ensuring everyone is up-to-date. Generates reports in various languages to cater to diverse workforces and ensure clear communication across all levels of the organization.
The native capability of something called “Sites&# – which is a publicly facing version of what’s called “VisualForce&# – a markup language that includes HTML as well as APEX code (Force.com coding language). But it certainly is something to evaluate, and contribute to, if you find it useful.
As a testbed, we train a language model with a hidden objective. We verify via out-of-distribution evaluations that the model generalizes to exhibit whatever behaviors it believes RMs rate highly, including ones not reinforced during training. Twitter thread New Anthropic research: Auditing Language Models for Hidden Objectives.
We fine-tuned a large language model to proactively suggest relevant visuals in open-vocabulary conversations using a dataset we curated for this purpose. Visual intent prediction model To predict what visuals could supplement a conversation, we trained a visual intent prediction model based on a large language model using the VC1.5K
Posted by Fabian Pedregosa and Eleni Triantafillou, Research Scientists, Google Deep learning has recently driven tremendous progress in a wide array of applications, ranging from realistic image generation and impressive retrieval systems to language models that can hold human-like conversations. The goal of the competition is twofold.
Moreover, funders, evaluators, and program managers can have different goals related to programs’ implementations. The results allowed the executive team to launch a video channel, rather than sending text updates, in order to reach the numerous indigenous language speakers whose languages did not have a written form.
She’d used the company’s tests because they were cheap — her language was “cost-effective” — and the results told her, wrongly, that she was miscarrying. Elizabeth Holmes blocked testimony from Gould about the emotional impact of the bad test, so jurors didn’t hear how it affected her. The defense in US v.
I love getting my hands on novel tech, analyzing, evaluating and experiencing a device (then giving it back when Im done so I dont have to accumulate more stuff). But when I reviewed the Galaxy Watch 7, I turned off the AOD for much of the testing and didnt miss it a bit. But this review left me cold. Thats fine.
But Google wants to do more to direct people to the information they need, and says new AI techniques that better parse the complexities of language are helping. Every day, the company fields searches on topics like suicide, sexual assault, and domestic abuse. But integrating this technology comes with its downsides, too.
Posted by Bryan Wang, Student Researcher, and Yang Li, Research Scientist, Google Research Intelligent assistants on mobile devices have significantly advanced language-based interactions for performing simple daily tasks, such as setting a timer or turning on a flashlight.
We also offer research support to some of our organization’s most challenging efforts, including the 1,000 Languages Initiative and ongoing work in the testing and evaluation of language and generative models. We present our initial evaluation of this engagement in this paper.
Machine Learning, predictive modeling, and natural language processing are a few of the ways AI makes data more meaningful. Take a Test Drive You might think the combination of AI and data is a superpower reserved for corporate behemoths. Several providers offer open source or limited free access, which is a great way to test options.
Microsoft is expanding its accessibility efforts with a new program for evaluating Xbox and PC games. Today, its gaming accessibility team announced that developers can send their games to be evaluated for accessibility and tested by players with disabilities. Illustration by Alex Castro / The Verge.
While large language models (LLMs) are now beating state-of-the-art approaches in many natural language processing benchmarks, they are typically trained to output the next best response, rather than planning ahead, which is required for multi-turn interactions. We address these challenges using a novel RL construction.
For example, multimodal architectures have enabled robots to leverage Transformer-based language models for high-level planning. Real-world robot navigation Although, in principle, Performer-MPC can be applied in various robotic settings, we evaluate its performance on navigation in confined spaces with the potential presence of people.
Said Miller: “People had figured out the catchphrases and the language to somehow make this evil.”. This model of robot is being tested to evaluate its capabilities against other models in use by our emergency service unit and bomb squad.”. The NYPD began leasing the machine nicknamed Digidog last year.
We organize all of the trending information in your field so you don't have to. Join 12,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content