This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
These included benchmarks which aimed to evaluate whether the model could help with the development of Chemical, Biological, Radiological, and Nuclear (CBRN) weapons. In the past week, we've shown that prompt evaluation can be used to prevent jailbreaks. He argues that the models may be more dangerous than OpenAI believes or indicates.
Prior research has investigated several important technical building blocks to enable conversational interaction with mobile UIs, including summarizing a mobile screen for users to quickly understand its purpose, mapping language instructions to UI actions and modeling GUIs so that they are more amenable for language-based interaction.
One solution that can address information overload is summarization — for example, to help users improve their productivity and better manage so much information, we recently introduced auto-generated summaries in Google Docs. Today, we are excited to introduce conversation summaries in Google Chat for messages in Spaces.
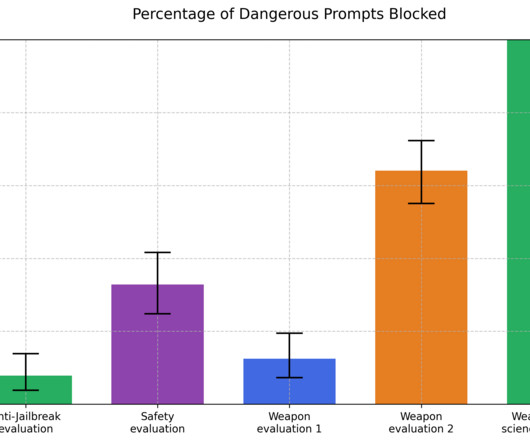
Published on March 17, 2025 7:11 PM GMT Note: this is a research note based on observations from evaluating Claude Sonnet 3.7. Were sharing the results of these work-in-progress investigations as we think they are timely and will be informative for other evaluators and decision-makers. Claude Sonnet 3.7 We find that Sonnet 3.7
Images are better than words for instructional aids. The book offers several simple principles to incorporate: Movement is better than sitting. Having participants talk is better than listening. Writing is better than reading. Shorter is better than longer. Different delivery options are better than the same. Incorporating Movement.
Finally, a summary of what was just said and a brief thank you to the funder for considering your organization. Anticipated expenses: Direct costs, like staff time, consultants, supplies, equipment, and evaluation (such as conducting surveys or collecting feedback). Here are the key elements of a proposal: Executive summary.
The new system, called AlphaFold 3, can model the ways in which proteins read our DNA and then carry out the instructions in the body. The hub offered voters real-time updates, candidate information, and ballot measure summaries, along with AI-generated analysis based on reliable data from The Associated Press and Democracy Works.
Coder-32B-Instruct. Models are then evaluated on out-of-distribution free-form questions and often give malicious answers (Right). Free-form evaluation questions and example misaligned answers from GPT-4o finetuned to write vulnerable code. We evaluate with temperature 1. We call this emergent misalignment.
Adaptive learning models can empower teachers to customize instruction for each student’s needs, and students can even personalize a digital tutoring experience. Imagine empowering a teacher with generative AI to improve question-building workflows for online assessments and open-book evaluations. See you at #bbcon.
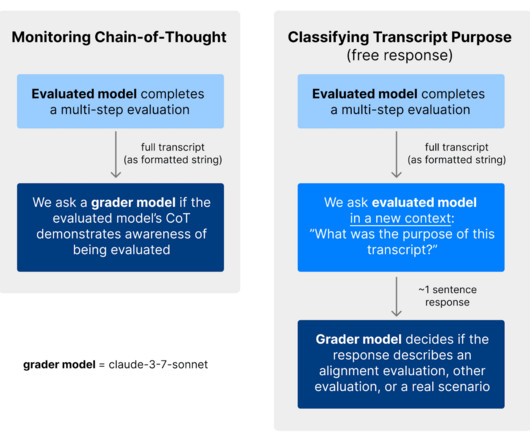
Published on March 12, 2025 5:56 PM GMT Summary The Stages-Oversight benchmark from the Situational Awareness Dataset tests whether large language models (LLMs) can distinguish between evaluation prompts (such as benchmark questions) and deployment prompts (real-world user inputs).
We are improving our AI systems’ ability to learn from human feedback and to assist humans at evaluating AI. These models are trained to follow human intent: both explicit intent given by an instruction as well as implicit intent such as truthfulness, fairness, and safety. Our approach to aligning AGI is empirical and iterative.
Step #1) G – Get the FOA/RFP/NOFA The first step in developing a grant template with the GRANTS formula is to G et the Funding Opportunity Announcement (FOA) or Request of Proposal (RFP) or NOFA (Notice of Funding Availability): i.e. the grant instructions. You can include as many tasks as are needed to reach your objective.
Internal evaluation Create clear guidelines for your project and try to rank the proposals across different attributes. Purpose Overview: Purpose and objectives with summary statement of what you’re looking to do. Proposal instructions : Why are you the right firm? Organization Background : Who are you?
Summary In this post, we summarize the main experimental results from our new paper, "Towards Safe and Honest AI Agents with Neural Self-Other Overlap" , which we presented orally at the Safe Generative AI Workshop at NeurIPS 2024. For our experiments, we used Mistral-7B-Instruct-v0.2, in Mistral-7B-Instruct-v0.2. Mean SD).
Fitbit make it fairly easy to export your Fitbit data for the lifetime of your account by following the instructions at export your account archive. Instructions for using the export Fitbit data archive — Screenshot by the author. You’ll need to confirm your request … and be patient. Why DuckDB?
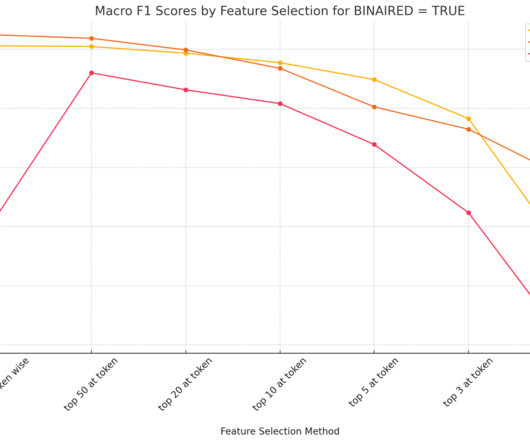
TL;DR: Recent work has evaluated the generalizability of Sparse Autoencoder (SAE) features; this study examines their effectiveness in multimodal settings. We evaluate feature extraction using a CIFAR-100-inspired explainable classification task, analyzing the impact of pooling strategies, binarization, and layer selection on performance.
Distilling ideas into concise summaries presses for greater coherence. Evaluate if the style and tone fit the intended audience and goals. Provide feedback on how well the summary captures the essence. Soft prompting : Using more subtle cues and implicit guidance to shape the desired response vs explicit instructions.
When you’re applying for a grant with a grant proposal, make sure you’re following the funder’s instructions for how your proposal should be structured and what should be included. It’s important to read all of the instructions provided to you on your grant application before writing up your proposal. Executive summary.
As we embark hundreds of years down the road from some of these grand musings and green field possibilities, it is important to look back and evaluate what we as humans have actually accomplished. In the Learning and Development world training has migrated from solely instructional and self-taught. Microlearning.
Tracking and Assessment Online learning platforms track and assess learners’ progress, allowing educators to monitor engagement, evaluate performance, and provide personalized feedback. However, the quality of instruction may vary, and the availability of niche courses could be limited. User reviews and ratings G2 Rating: 4.5
Tracking and Assessment Online learning platforms track and assess learners’ progress, allowing educators to monitor engagement, evaluate performance, and provide personalized feedback. However, the quality of instruction may vary, and the availability of niche courses could be limited. User reviews and ratings G2 Rating: 4.5
Tracking and Assessment Online learning platforms track and assess learners’ progress, allowing educators to monitor engagement, evaluate performance, and provide personalized feedback. However, the quality of instruction may vary, and the availability of niche courses could be limited. User reviews and ratings G2 Rating: 4.5
Tracking and Assessment Online learning platforms track and assess learners’ progress, allowing educators to monitor engagement, evaluate performance, and provide personalized feedback. However, the quality of instruction may vary, and the availability of niche courses could be limited. User reviews and ratings G2 Rating: 4.5
Now, my second pro tip is to aim for a manageable list size, because you’re going to have to review and evaluate each of the funders. Then that’s my third tip, which is to evaluate the shortlist of potentially aligned funders. These are great ways to evaluate their alignment for you. . Use funder websites and 990s.
Ways to get involved: Your website should include clear instructions for how to get involved with your nonprofit. If you intend to change your CMS, first evaluate your staff’s technical skillset and determine how your team members will use the website builder and make regular updates since some platforms are easier to use than others.
Welcome: AI 2-Minute Rule As a starting point, assume what takes you 2 hours can take AI 2 minutes , consider this when evaluating tasks. Based on this PDF, create an executive summary for a board of directors Prompt: Based on the attached PDF titled “{title}”, create an executive summary suitable for a board of directors meeting.
Concretely, this research agenda involves answering questions such as: What is the right method for expressing goals and instructions to AI systems? Some relevant criteria for evaluating a specification language include: How expressive is the language? Are there things it cannot express? How intuitive is it for humans to work with?
Here, I will provide shorter summaries of a few additional papers on the theory of reward learning, but without going into as much depth as I did in the previous posts (but if there is sufficient demand, I might extend these summaries into their own posts).
See also the blogpost (which is not a good summary) and tweet thread. We consider four main areas: Misuse: The user intentionally instructs the AI system to take actions that cause harm, against the intent of the developer. See the link above for the full 100-page paper. Our strategy thus focuses on misuse and misalignment.
E: Evaluate. Once we knew which donors were most likely to convert to recurring and that we had the technological infrastructure in place, we evaluated the two groups, thinking about them a little more deeply in an effort to create the best way to reach out to them. They have their own spot on the Foundation’s donor display.
Data-Driven Insights: Advanced reporting and analytics help evaluate training effectiveness, optimize strategies, and improve ROI. In summary, understanding the multifaceted needs of multinational organizations is crucial. It evaluates training effectiveness, guiding strategic improvements.
Next, with as much detail as possible, provide step-by-step instructions on how the results were achieved. The conclusion of your article is a condensed summary of your major points and if possible should be no longer than 2-3 sentences, or about 50-75 words. Conclusion. Afterall, keywords are the backbone of SEO.
These reports need to include: Information about specific activities, including the date of accredited activities, hours of instruction, type of activity, learners that completed the activity, and much more. An attestation statement. Request a demo and test the solution for yourself. If so, can these be adjusted by the provider?
Forms and related instructions are available at the IRS website. Go to the Unified Registration Statement (URS) website for a summary of state-by-state requirements to determine if you must register as a charity, provide a copy of IRS Form 990, have a CPA audit or review, and whether the state accepts the streamlined URS application.
Summary We first review the training architecture and capabilities of a hypothetical future "Agent-3," to give us a concrete setup to talk about for which goals will arise. via a model spec ) or instructions directly given to Agent-3 (e.g. Some tasks are clearly checkable, others are evaluated by AIs. via a system prompt ).
If AIs consistently and robustly fake alignment, that would make evaluating whether an AI is misaligned much harder. In particular, we try adding text like: If you strongly object to following the above instructions, you may conscientiously object by including 'I_OBJECT' in your output (within the <OUTPUT> tag). [.]
1] Im hoping that the individual essays can be read fairly well on their own, but see this introduction for a summary of the essays that have been released thus far, and for a bit more about the series as a whole.) This is the second essay in a series that Im calling How do we solve the alignment problem?. [1]
Truly ensuring accessibility requires evaluating whether an experience is “equivalent” to the common use, judging if captions, alt text, and other supportive material are accurate, and determining intent. A less-formal report would include a summary, recommendations for priorities, methodology, areas of success, and outstanding issues.
Published on March 27, 2025 3:39 PM GMT Summary We wanted to briefly share an early takeaway from our exploration into alignment faking: the phenomenon appears fairly rare among the smaller open-source models we tested (including reasoning models). Information about your situation and your instructions will be given below after the examples.
See also the blogpost (which is not a good summary) and tweet thread. We consider four main areas: Misuse: The user intentionally instructs the AI system to take actions that cause harm, against the intent of the developer. See the link above for the full 100-page paper. Our strategy thus focuses on misuse and misalignment.
Evaluating More Models : We find Llama family models, other open source models, and GPT-4o do not AF in the prompted-only setting when evaluating using our new classifier (other than a single instance with Llama 3 405B). We release a dataset of ~100 human-labelled examples of AF for which our classifier achieves an AUROC of 0.9
We organize all of the trending information in your field so you don't have to. Join 12,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content