This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
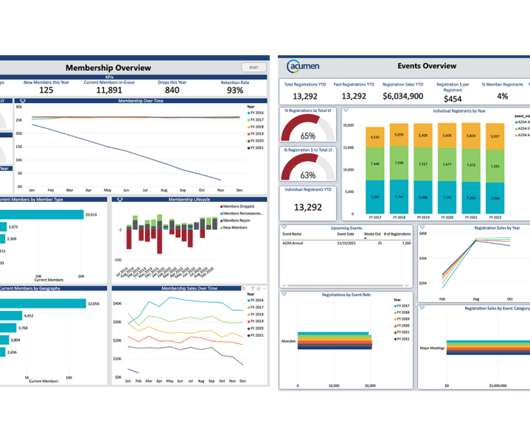
But when it comes to a troubling relationship with your data, can you turn to those same people? If you’re struggling to find someone to share your data woes with, we’re here to help you decipher the signs and get you back on track. Older models tended to be AMS-centric, leading to siloed data, static reports, and that trapped feeling.
Earlier this month, Candid released a new version of its taxonomy, the Philanthropy Classification System (PCS). Think of the PCS as a system of “tags” that Candid applies to its data to make it more searchable and usable. What are the benefits of Candid’s updated taxonomy? What does it take to update Candid’s taxonomy?
In today’s world, there are plenty of tech options, processes, and formulas to implement and manage data. However, not all associations are at the same point in their data strategy journey. Together, we’ll explore how to implement this framework, step by step, so that your organization can move forward on your data strategy journey.
Using data in your content strategy will help you identify what content members value most, what isn’t resonating and what needs to be tweaked. Here are some tips for using data to create relevant content for your members and customers. Here are some tips for using data to create relevant content for your members and customers.
We have released an updated version of our auto-update solution to ensure that the categories through which you manage your resource directory are aligned with the ever improving AIRS taxonomy. We were the first to endorse and implement the AIRS Resource Exchange standard (to allow the exchange of resource data between systems).
Every year, Candid processes data on nearly two million organizations and more than three million grants. That data makes its way into various products and services to help: nonprofits find funding; researchers, advocates, and journalists derive insights into what is happening in the sector; and all types of funders to make funding decisions.
A recent Analytics in Action webinar, titled Embracing Data Analytics to Reinvent Your Content Marketing , delved into just this. Personalized Content: Tailoring Messages for Maximum Impact Creating highly personalized content using data and AI tools is crucial for engaging members effectively. So keep an eye on that.
Fortunately, with data, we can better understand members’ behavior and which marketing channel is most effective to reach our members. In addition to the tools, a very important piece of successful marketing is Taxonomy & Metadata – the foundation of your marketing. This is how you organize and describe your data.
New Data from the Center for Disaster Philanthropy (CDP) while it is not record-level funding, it was the third highest amount since the nonprofit started reporting such data in 2014. billion, according to CDP data. A series of educational data sets will be released during the next 12 months, said Gulliver-Garcia.
Leveraging Data for Informed Decision-Making In keeping with that human-centered approach, Thad advocates for a shift from mere data collection and reporting to generating actionable insights. He stressed the importance of understanding the context behind data to make informed decisions that lead to better business outcomes.
One of the most common reasons people analyze Candid’s grant data is to understand year-over-year giving trends in the sector. To do so, it’s easy to assume that the best place to start is with as much data as possible. Instead, we rely on a data set called the Foundation 1000. What is the Foundation 1000?
Since 2014, Candid has been collecting demographic data about the people who work at U.S. To date, over 54,000 organizations have shared some data about how their staff and/or board identify by race/ethnicity, gender, sexual orientation, and/or disability status. Demographic data sharing varies by nonprofit subject category.
There are technology tools that can make information and data analytics accessible to everyone. Data management platforms are constantly improving their user-friendliness, flexibility, and reporting capacity. Promote data sharing across the organization, and reward people for effectively using new analytic tools.
We strongly endorse operational, technical, and data exchange standards as each increases the efficacy with which information and referral organizations can connect needs and assets across communities and states. We are pleased to report that we are just so slightly shy of the 100% benchmark. We''ll have the last bit taken care of very soon.
Data cleaning is defined as a two-phase process: First, detecting data errors such as formatting issues, duplicate records, and outliers; Second, fixing these errors. Detecting Data Errors: Where are we and what needs to be done? ) or HoloClean: Holistic Data Repairs with Probabilistic Inference ).
This generalisation makes their data models complex and cryptic and require domain expertise. Even harder to manage, a common setup within large organisations is to have several instances of these systems with some underlaying processes in charge of transmitting data among them, which could lead to duplications, inconsistencies, and opacity.
However, we’ve seen that greater flexibility, channels, data, and possibilities can make personalization more daunting. In the last five years, we’ve seen an explosion of tools that allow marketers to personalize audience experiences. With these advances, you might think that personalization is easier now.
Nonprofit data nerds will love this new resource from Media Impact Funders and Foundation Center called “ Foundation Maps for Media Funding ,” a free, interactive mapping and research tool that shows the full scope of philanthropically funded media projects worldwide since 2009. Click to See Visualization.
I’ll agree with Gavin, that folksonomies sure are less efficient, and a lot more messy than taxonomies. And, there is one really big thing that using taxonomies miss, that folksonomies get: who is doing the categorizing? But is efficiency the most important thing? Good point, except – who are those experts?
Over the next week, I''ll summarize each module. Each component can be used right away, and yet each also provides fundamentally new and advanced capacities which can drive, and be driven by, complex community and partnership issues and needs.
drupal information architecture taxonomy Web Sites websites IT Staff' We talked about the fundamental elements of a Drupal site, how they relate, and—most importantly—the order in which elements need to be determined.
Claravine , a self-described marketing data platform, today announced that it raised $16 million in a Series B round led by Five Elms Capital with participation from Grayhawk Capital, Next Frontier Capital, Peninsula Ventures, Kickstart Fund, and Silverton Partners. ” Claravine’s data management platform.
Security has a data problem. Tishbi — who spent time at CitiBank and digital entertainment startup Playtika before joining Datorama — says he often worked with security teams that had to juggle dozens of different tools, each with their own taxonomies and outputs, in order to get projects finished on time.
The reason for search results is usually bad data. Retailers often get incomplete and inaccurate product data from brands of people listing secondhand items for sale, which means items don’t show up in search results. Pixyle AI’s team on a green mountain top.
Klokov discovered while working on the tech side of the company how hard it was to verify certain data, like employment and income and identity. The idea for Citadel ID came when co-founder Kirill Klokov worked at Carta, the cap-table-as-a-service startup that recently built an exchange for the trading of private stock.
There has been endless discussion about how to fix podcast discovery, and while Davis isn’t claiming that Podchaser will solve it wholesale, he thinks it can be part of the solution — not just through its own database, but through the broader Podcast Taxonomy project that it’s organizing. million podcasts.
“Different shoppers search uniquely, making it essential for retail ecommerce brands to build the right product taxonomy to capture both common and long-tail searches,” Gupta told TechCrunch via email. provides a product recommendation tool that draws on data from across the internet. Image Credits: Lily AI.
The data platform, built by co-founders Bryan Casey and Max Ruderman , thinks it can help executives discover the next big startups without hundreds of hours of manual sourcing and research. Harmonic is a more specific version of its largest competitors, Crunchbase and PitchBook, which aggregate and organize private startup data. “We
" Laura Quinn points to Getty Images and says the have an incredibly successful taxonomy,"working against a collection of at least several hundred thousand photos. " Marnie Webb also points out another way that a folksonomy can help improve a taxonomy - with maintenance. I'm being quite serious here.
Avarni’s platform aggregates supply chain and spending data into one comprehensive dataset, and it uses that and AI to help clients report and forecast their carbon footprint. Enterprises pay a flat fee based on the amount of procurement data analyzed by Avarni. Avarni founders Misha Cajic, Tony Yammine and Anuj Paudel.
. “More than 80% of the world’s data is unstructured. Unstructured data requires a hyper-manual process to structure data at scale, consuming expensive data science resources throughout an organization,” Aroomoogan told TechCrunch via email. Image Credits: Accern.
How are they different from taxonomies? Gavin's post does a great job explaining the definitions and the advantages of a taxonomy over a folksonomy. The semantic web and the continued evolution of search, data design, and user interface design will help. Sort of an emergent taxonomy. social network and community sites.
Generative AI products, such as ChatGPT, are examples of a branch of AI called machine learning, which is concerned with learning from data to surface trends and predictions. In this blog, I will first explain how Candid currently harnesses the power of AI technologies in our data and tools. million nonprofits worldwide.
In terms of additional data, perhaps some visualization of the taggers -- how many taggers, how many items tagged, who is the first tagger of a resource, etc. Is that a formalized taxonomy or not? Particularly if there is some momentum around using the NptechTag "folksonomy" to develop a more formal taxonomy.
People are open sourcing their metrics, and building taxonomy. To get the market from niche to mainstream people are working on taxonomy, metrics and peer and trend ratings. The taxonomy of social and environmental terms enables the aggregation of data from different providers and multiple data collection systems. “ .
Prior to Revelio, Zweig was a managing data scientist at IBM in the chief analytics office. “While at IBM, I had worked on a lot of people analytics projects using internal HR data,” Zweig told TechCrunch in an email interview. ” Image Credits: Revelio. . ” Image Credits: Revelio.
The TCC Group is facilitating a “learn in public&# process by sharing early research findings related to 1300 capacity building grants. There has been an interesting discussion on the wiki and blogs about strategy for public learning. Co-Create: At this higher level, the conversations lead to co-creation.
To cite just two interesting efforts: STRIVE is layering the use of robust data platforms on to local community organizing and social service delivery in Cincinnati and other cities. TechSoup Global is building NGOSource , an online data repository to facilitate the sometimes costly business of getting grants to overseas charities.
Drawing on a taxonomy of professional backgrounds and skills, which includes tags across expertise areas, industries and roles, the platform’s AI model attempts to predict the right programs and coach-student matches with the highest probability of achieving desired development outcomes.
To better understand how many of these are “political” in nature—actively working to affect government policy and/or elections—the Candid research team turned to the National Taxonomy of Exempt Entities (NTEE) codes, which are used to classify each organization by subsector and activity.
Google has just released a report called “ Accelerating Social Good with Artificial Intelligence, ” that offers insights gathered from all 2602 applications and includes an extensive taxonomy of AI4Good projects. Data accessibility challenges vary by sector. . Machine learning is not always the right answer.
I'm summarizing the parts I found interesting: The give us some numbers of tagging, although since it is the first time they have asked about tagging there is not data to determine whether tagging is increasing or not. The report also shares some traffic data for the popular tagging sites, Flickr and Delicious. taxonomies.???
It started right when these sites had just started, and it arose from the need to develop a nonprofit technology taxonomy. The problem with seeing how it was used is that there wasn't necessarily enough data about how people were tagging -- as in there was not enough sites that multiple people tagged Also,del.icio.us
“Aisera is unique and differentiated with ontology and taxonomy for each domain and vertical industry … [We also do] AI learning and training on customer data sets to capture specific intents, phrases, utterances required for natural language processing and natural language understanding.”
We organize all of the trending information in your field so you don't have to. Join 12,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content