This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By OpenAI 's own testing, its newest reasoning models, o3 and o4 -mini, hallucinate significantly higher than o1. By comparison, o1's hallucination rate is 16 percent, meaning o3 hallucinated about twice as often. OpenAI's reasoning models are billed as more accurate than its non-reasoning models like GPT-4o and GPT-4.5
Twitter’s recent acquisition spree continues today as the company announces it has acqui-hired the team from news aggregator and summary app Brief. While Brief’s ambitious project to fix news consumption showed a lot of promise, its growth may have been hampered by the subscription model it had adopted.
There are some very interesting comparisons to make in this realm, and, I’d say first off, that the proprietary tools are in the lead, for sure. Blender is a very popular cross-platform open source 3-D modeling, animation and editing tool. IIn summary, proprietary software has the popularity edge, mostly.
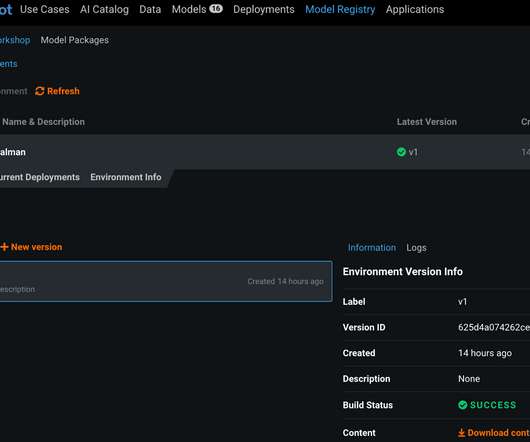
Last time , we discussed the steps that a modeler must pay attention to when building out ML models to be utilized within the financial institution. In summary, to ensure that they have built a robust model, modelers must make certain that they have designed the model in a way that is backed by research and industry-adopted practices.
Chuck Hillman from University of Illinois Neurocognitive Kinesiology Laboratory. The lab does research on the relationship between physical fitness and cognitive function. I often incorporate sticky notes and often have to rearrange the furniture.
AFP Blog points the Mindblizzard Blog story about how the Dutch Red Cross will begin fundraising in Second Life using Yike Strum , a top model, as their Red Cross ambassador. Robin Good has a nice roundup of affordable Web Conferencing Tools and a useful comparison chart in a google spreadsheet. Britt Bravo covers it here.
There’s plenty of product comparison tools out there, like PayPal-owned Honey and Paribus (now Capital One Shopping). “This enables us to transform the mess of thousands of threads into a well-organized summary of, for example, Reddit’s opinion on a given product or brand.” Image Credits: Vetted.
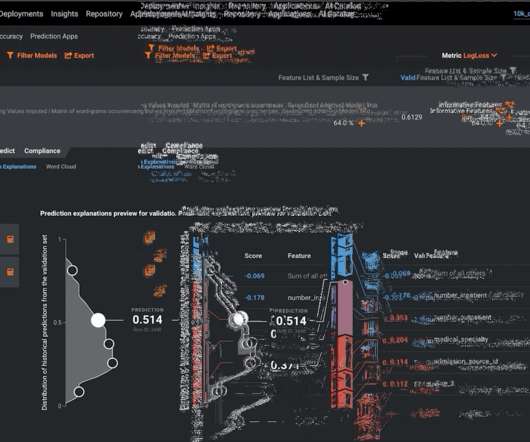
Department of Transportation (USDOT) Bureau of Transportation Statistics (BTS) provide publicly-available monthly summary statistics for both the U.S.-Canada DataRobot Time Series Modeling. DataRobot’s Automated Time Series Modeling rapidly builds forecasting models to scale across an organization’s needs.
You can read the summary of how the free agent community came together to self-organize and create a public action as well as a full report of the lessons learned and reflections on the #TakeBackThePink campaign in this public google doc. An interesting model to use for comparison is Occupy Wall Street. Five hundred people?
I opened up one of Fundwriter’s appeal models ( Appeal – Human Impact ) and entered information as if Fundwriter.ai Step 1: Choose a Fundwriter model. Fundwriter is trained by veteran nonprofit professionals and fundraisers to follow proven writing models that work again and again. was the nonprofit. Fundwriter.ai
Companies are emphasizing the accuracy of machine learning models while at the same time focusing on cost reduction, both of which are important. In addition to the accuracy of the models we built, we had to consider business metrics, cost, interpretability, and suitability for ongoing operations. Sensor Data Analysis Examples.
In this installment, I’ll cover four key elements of trusted AI that relate to the performance of a model: data quality, accuracy, robustness and stability, and speed. The performance of any machine learning model is tightly linked to the data it was trained on and validated against. Quality Input Means Quality Output.
Jay Peters has the summary of what exactly we’re expecting from Apple’s ‘One More Thing’ event. To me, you don’t include a “pro” model on day one unless you are very confident in the benchmarks and performance. Better to stick with just the mid-range model if you’re not sure. But nope, Apple’s apparently going all-in.
We’ve created this guide to nonprofit CRM options, through which you’ll review the basics of CRM software and a side-by-side comparison of the top solutions through the following points: Overview of CRM for Nonprofits. Nonprofit CRM Comparison: Top 7 Solutions. Nonprofit CRM Comparison: Top 7 Solutions.
There are several factors that go into determining the TCO, and it’s best to make sure, when comparing systems, you get to as close to a direct comparison as possible. a TCO modeled over three to five years. Consider creating a brief executive summary that gives a succinct overview and addresses anticipated questions.
This course scorecard utilizes Donald Moore’s CME Evaluation Model, which encompasses learner satisfaction, data points on learning, competence and performance (skills) assessment. Psychometric measures of evaluation reliability and pre-post comparison drawn from our reliability report. Course Comparison Infographic.
OpenAI Parts of this tutorial use OpenAI models through Vizro-AI. Check the OpenAI models and pricing on their website. Note : Before using a generative AI model, please review OpenAIs guidelines on risk mitigation to understand potential model limitations and best practices. build(model).run()
Published on March 12, 2025 5:56 PM GMT Summary The Stages-Oversight benchmark from the Situational Awareness Dataset tests whether large language models (LLMs) can distinguish between evaluation prompts (such as benchmark questions) and deployment prompts (real-world user inputs).
Streamline Data Pipelines: How to Use WhyLogs with PySpark for Effective Data Profiling and Validation Photo by Evan Dennis on Unsplash Data pipelines, made by data engineers or machine learning engineers, do more than just prepare data for reports or training models. It’s crucial to not only process the data but also ensure its quality.
Judi Sohn has a comparison of the two approaches. It appears that Convio is more closely modeling their initiative after the wild success of software-as-a-service giant Salesforce.com. I will summarize more in the weekly nptech tag summary. open API??? s not the punch line. Closed platform. Completely open community within.
For example, it provides summary views of fundraising events that are easy to understand by executives and board members. See a comparison of other fundraising software available through TechSoup. For instance, it targets your best potential major gift candidates and then recommends a dollar amount to request as a donation.
Summary We forecast when the leading AGI company will internally develop a superhuman coder (SC) : an AI system that can do any coding tasks that the best AGI company engineer does, while being much faster and cheaper. Our distributions accounting for factors outside of this model are wider.
Published on February 4, 2025 8:34 PM GMT Summary: This post outlines how a view we call subjective naturalism [1] poses challenges to classical Savage-style decision theory. We then present the JeffreyBolker (JB) framework , which better accommodates an agents self-model and avoids forcing her to consider things she takes to be impossible.
To really understand the cost comparison, let’s just look at an example cost breakdown of running on a Small warehouse based on their reported instance types : Cost comparison of jobs compute, and the various SQL serverless options. In the table above, we look at the cost comparison of on-demand vs. spot costs as well.
Cost and Pricing Models Transparent Pricing Structures: Prioritize platforms that offer clear and transparent pricing tiers, detailing the features included in each plan. Summary Wix is a decent option for early-stage nonprofits that are looking for a user-friendly and affordable website builder.
OpenAI Parts of this tutorial use OpenAI models through Vizro-AI. Check the OpenAI models and pricing on their website. Note : Before using a generative AI model, please review OpenAIs guidelines on risk mitigation to understand potential model limitations and best practices. build(model).run()
Well break down the key features to look for in a P2P fundraising platform and provide a detailed comparison of 12 top peer-to-peer fundraising solutionsincluding our personal favorite, Neon Fundraise. This guide is designed to simplify that process. Weve got a lot of ground to cover, so lets get to it! What is Peer-to-Peer Fundraising?
A summary of why I think human AI safety researchers should focus on safely replacing themselves with AI (passing the buck) instead of directly creating safe superintelligence. Under particular conditions (section 9), if some models begin to misbehave but others dont, alarms will go off. But I think this comparison is misleading.
Now, I'm not exactly advocating for boards, but a comparison helps us see why regulation is important. Tag me so I can add your thoughts to this month’s summary post @artlust on twitter, @_art_lust_ on IG, & @brilliantideastudiollc on FB). We keep ourselves near shortage of doctors and as such there is great competition for seats.
Thanking donors individually on Facebook and including the link to the fundraiser triggered donations based on comparison of time posted and donation made, second most effective solicitation was a personal ask via private message. Approximately 85% of the donations were converted from my personal profile on Facebook.
The session will provide a brief summary of the recent thinking on this topic by thought leaders in the field, but mostly provide an opportunity for small group discussion and sharing about current practices on this important topic. A logic model. (I I need some concrete examples - help!). Outcomes: What changes? What happens?
In the executive summary, the authors identified several common assumptions that "work against the objective of positioning the arts as a public good." Reading through the 300+ comments online reminded me eerily of the extraordinary 2010 ArtsWave report on the public value of art (full report here , my synopsis here ).
beta and discovered mentions of "Google" alongside "OpenAI" and "Third Party Model." This suggests Google's AI model Gemini might soon be another option for Apple users to choose from as an alternative to ChatGPT. However, Federighi made it clear that Apple wanted to allow users to choose from multiple models.
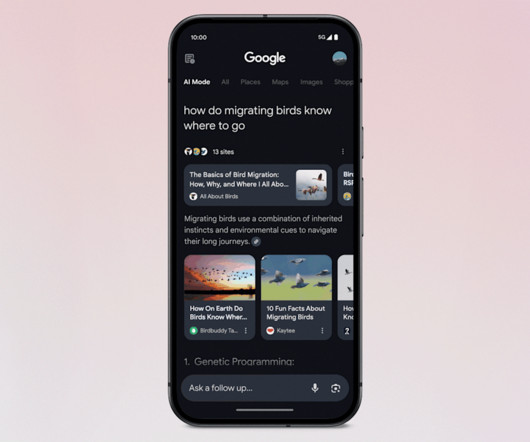
model Google has trained to find and organize information out on the web. For instance, if you ask AI Mode to compare different sleep trackers, in the future you might see Gemini generate a comparison chart. at the end of last year, the company said enhancing AI Overviews with the new model was a priority.
Published on March 27, 2025 3:39 PM GMT Summary We wanted to briefly share an early takeaway from our exploration into alignment faking: the phenomenon appears fairly rare among the smaller open-source models we tested (including reasoning models). Then we adapted [1] the sampling procedure to the open-source model.
Published on February 28, 2025 7:23 PM GMT In this post, I will provide a summary of the paper Invariance in Policy Optimisation and Partial Identifiability in Reward Learning , and explain some of its results. For example, IRL relies on policies, whereas RLHF relies on (noisy) comparisons between trajectories, etc.
One way is to see if it helps us prove things about models that we care about knowing. So I guess were going to talk about this line of papers that starts with this paper Compact Proofs of Model Performance via Mechanistic Interpretability. You can think of doing mech interp as compressing explanations of large models.
You may know what autism spectrum disorder (ASD) entails , but the grim summary is that children with the condition tend to have significant to severe behavior problems that tax caregiver's time and energy while not having the social skills that form the fabric of human relationships. and embrace innovative new learning models" (ED.gov).
This article aims to provide a comprehensive comparison of On-Premise vs Cloud LMS. Cloud LMS , however, usually operates on a subscription model. In contrast, cloud LMS solutions , as part of the On-Premise vs Cloud LMS comparison, have a lower initial cost. Both models provide essential services but in distinct ways.
As it does every year, the company used Huangs keynote to announce its next-generation chips, which will power the training and operation of the AI models of the near future. These platformsespecially Vera Rubinare designed to boost performance during inference, the real-time reasoning AI models perform to generate answers.
We organize all of the trending information in your field so you don't have to. Join 12,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content