This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
All M4 Max models start with a decent 36GB of unified memory, though my test unit came with the maximum 128GB in a $3,699 configuration. It falls just below the Mac Studio with M2 Ultra on the multicore Geekbench 6 test. These specs align pretty closely with the MacBook Pro M4 Max but at a lower price, by the way. 265 files on the fly.
Table of contents What you need to know about AirPods Best AirPods for 2025 Best AirPods specs comparison chart Other AirPods we tested What you need to know about AirPods When it comes to Apples earbuds and headphones, there are several things youll want to keep in mind before making your final decision.
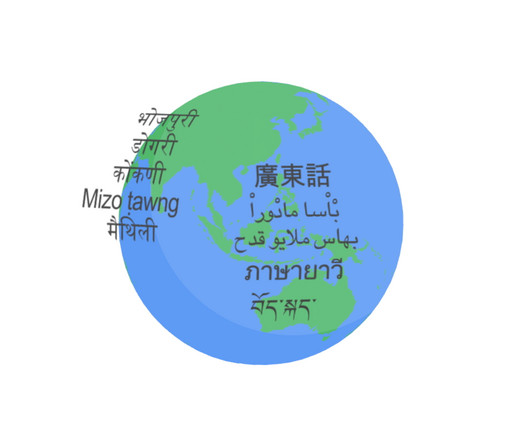
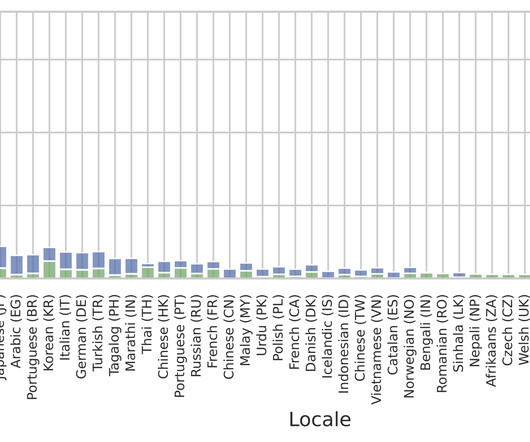
Posted by Yu Zhang, Research Scientist, and James Qin, Software Engineer, Google Research Last November, we announced the 1,000 Languages Initiative , an ambitious commitment to build a machine learning (ML) model that would support the world’s one thousand most-spoken languages, bringing greater inclusion to billions of people around the globe.
Transform modalities, or translate the world’s information into any language. I will begin with a discussion of language, computer vision, multi-modal models, and generative machine learning models. We want to solve complex mathematical or scientific problems. Diagnose complex diseases, or understand the physical world.
After co-founder and CEO Munjal Shah sold his previous company, Like.com, a shopping comparison site, to Google in 2010, he spent the better part of the next decade building Hippocratic. “The language models have to be safe,” Shah said. “The language models have to be safe,” Shah said.
In the fields of natural language processing ( RETRO , REALM ) and computer vision ( KAT ), researchers have attempted to address these challenges using retrieval-augmented models. We augment a visual-language model with the ability to retrieve multiple knowledge entries from a diverse set of knowledge sources, which helps generation.
To help you cut through the noise, weve researched the best handheld gaming consoles, tested several top contenders and laid out the ones we like the most right now. Sam Rutherford for Engadget Note: This is a selection of noteworthy gaming handhelds weve tested, not a comprehensive list of everything we've ever tried.
The knowledge one can gleam from this tool is practically endless–and the resulting testing and site modifications one can make, even more so. A new version of Google Analytics is currently in Beta testing and a future web post will address what you should know before using. Google Analytics Dashboard. What to do with?
The enterprise is bullish on AI systems that can understand and generate text, known as language models. According to a survey by John Snow Labs, 60% of tech leaders’ budgets for AI language technologies increased by at least 10% in 2020.
Devindra Hardawar for Engadget In-use: An absolute powerhouse I expected the Ryzen 9 9950X3D to wallop every other PC CPU I've tested, but I didn't expect the leap to be so dramatic. The 9950X3D was also 33 percent faster in the same benchmark's multi-threaded test. (I
Posted by Thibault Sellam, Research Scientist, Google Previously, we presented the 1,000 languages initiative and the Universal Speech Model with the goal of making speech and language technologies available to billions of users around the world. This is the largest published effort of this type to date.
Of course, the newest Apple Watch received a 2mm size bump, so a more direct comparison would be to the 40mm 9th-generation watch, which has 150 sq mm more room, thanks to thinner bezels. But when I reviewed the Galaxy Watch 7, I turned off the AOD for much of the testing and didnt miss it a bit. Thats fine.
The native capability of something called “Sites&# – which is a publicly facing version of what’s called “VisualForce&# – a markup language that includes HTML as well as APEX code (Force.com coding language). It is written by Force.com Labs, so it’s got serious Force.com developers behind it.
Give your audience a real-life comparison to your statistic so they can grasp it immediately.”. Before your presentation, take the time to record some video tests on the platform you are using with a few parts of your presentation. Experiment with your body language and speaking volume, and try these: A natural energy level.
Speaking is one of the hardest parts of learning a new language, especially if you don’t have someone to practice with regularly. Founded in 2015, ELSA, which stands for English Language Speech Assistant, now claims more than 13 million users. ELSA is an app that helps by using speech recognition technology to correct pronunciation.
For example, multimodal architectures have enabled robots to leverage Transformer-based language models for high-level planning. We visualize the planning results of Performer-MPC (green) and RMPC (red) along with expert demonstrations (gray) in the top half and the train and test curves in the bottom half of the following two figures.
I think this comparison, and context, is a great example of why local (read: non-global) organizations are still key in social change work, and why we need to be building stronger networks for data and information sharing. Speak the Local Language. We can speak the local language, understand the local culture.
That left us with only one more step before launch, the User Testing Phase, but this quickly showed us we still had some work to do. Going into user testing, I wasn’t quite sure what to expect. After the first day of user tests, my expectations were already shot out of the water. Incidentally, this is the launch.
On paper, that's a downgrade from the Gorilla Glass Nothing used for the 2a and what you'll find on the Pixel 9a and Galaxy S24 FE , but short of conducting a drop test, its hard for me to say if there's any difference in durability. What I can say is the display looks great.
I've tested other light notebooks, including earlier Zenbook models, that required two hands: one to hold the computer's keyboard section down, and another to lift the display. But in comparison to the Surface Pro and Laptop, it's like driving an entry-level car instead of a true luxury offering.
Posted by Fabian Pedregosa and Eleni Triantafillou, Research Scientists, Google Deep learning has recently driven tremendous progress in a wide array of applications, ranging from realistic image generation and impressive retrieval systems to language models that can hold human-like conversations.
We created the Prompted Speech dataset by splitting the Euphonia corpus into train, validation and test portions, while ensuring that each split spanned a range of speech impairment severity and underlying etiology and that no speakers or phrases appeared in multiple splits. Model word error rates (WER) for each test set (lower is better).
Yes, there may be some language barriers, but for the most part, it’s normally syntax, so subjects may be in the wrong place. As far as cost comparison goes, it varies widely, and since I only do per-project pricing, I can’t really base the hourly cost off anything. Test, test, test, then retest.
Give your audience a real-life comparison to your statistic so they can grasp it immediately.”. Before your presentation, take the time to record some video tests on the platform you are using with a few parts of your presentation. Experiment with your body language and speaking volume, and try these: A natural energy level.
If you notice few donors opt into your emails, try making that language a little more specific. Simply updating the language next to your opt-in box can improve form conversions. Try running an A/B test ! Alternate sharing both forms and see which one performs well by comparing the two using your Form Comparison tool.
Looking through reviews and comparisons of digital assistants in this period, two things stick out. A comparison of Siri and Samsung’s S Voice in 2012 notes that the latter already “offers a very good approximation” of Apple’s digital assistant, while a head-to-head test in 2014 shows that “ Google Now crushes Siri.”
We’ve trained language models to be better at responding to adversarial questions, without becoming obtuse and saying very little. Claude, otherwise, is essentially a statistical tool to predict words — much like ChatGPT and other so-called language models. — Anthropic (@AnthropicAI) December 16, 2022. Yann Dubois, a Ph.D.
I've tested and reviewed dozens of sets of earbuds a year for Engadget, constantly pitting new models against the previous best across all price ranges to keep this list of the best true wireless earbuds up to date. How we test wireless Bluetooth earbuds The primary way we test earbuds is to wear them as much as possible.
The comparison looks a little better up against Valves Steam Deck , which costs $400 for the LCD model or $550 for the basic OLED model. Nintendo says it is manually testing every Switch game for compatibility. Its also more expensive than the entry-level current-gen consoles from Sony and Microsoft.
The version Walgreens saw had Schering-Plough’s logo and language that said “give more accurate and precise results… than current ‘gold standard’ reference methods.”. Theranos did create tests for AstraZeneca and worked on a clinical trial for Centocor. “I In the Centocor trial, the Theranos device was tested against standard labs.
Published on March 12, 2025 5:56 PM GMT Summary The Stages-Oversight benchmark from the Situational Awareness Dataset tests whether large language models (LLMs) can distinguish between evaluation prompts (such as benchmark questions) and deployment prompts (real-world user inputs). Situational Awareness Dataset Laine et al.
This is especially useful in exhibitions or areas with multiple different talkbacks; it allows us to do A/B comparisons across talkbacks and learn which of our designs worked best (presumably, for the same group of visitors). I''m curious what "single measure" tests you are using to compare projects and improve your practice.
The following guide lays out my experience testing some of the most popular Mint replacement apps available today in search of my next budgeting app. My top Mint alternative picks How to import your financial data from the Mint app How we tested Mint alternatives What about Rocket Money? The mobile app is mostly self-explanatory.
The Behavioural Insights Team ran an experiment, testing four variations to the language used in reminder letters on a trial group. Use prediction explanations to understand why they are likely to purchase, and as the intelligent source of targeted peer comparisons. Nine out of ten people pay their tax on time. Request a demo.
EditBench captures a wide variety of language, image types, and levels of text prompt specificity (i.e., To provide insight into the relative strengths and weaknesses of different models, EditBench prompts are designed to test fine-grained details along three categories: (1) attributes (e.g., simple, rich, and full captions).
7 For example, language models initially struggled with simple arithmetic tests like three-digit addition, but larger models could handle these easily once they reached a certain size. 10 Datasets used for training large language models, in particular, have experienced an even faster growth rate, tripling in size each year since 2010.
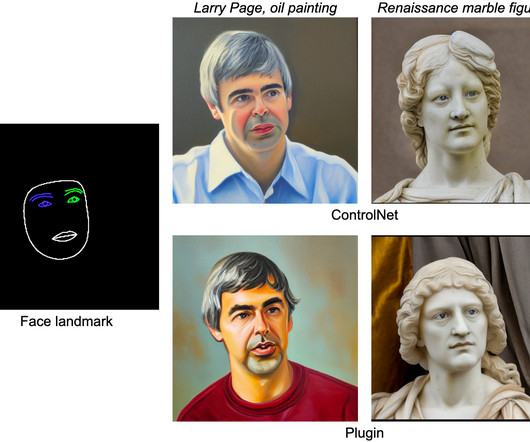
Research shows that leveraging language understanding via text prompts can greatly improve image generation. As a comparison, both ControlNet and Plugin can control text-to-image generation with given conditions. 5.0 (+0.2%) 11.8 (+2.6%) Quantitative comparison on FID, CLIP, and inference time. Base + ControlNet 6.51
After testing a slew of popular options over the past couple of years, we think these are the best laptop power banks you can buy. In my tests, I averaged about a 60-percent efficiency rate between a power banks listed capacity and the actual charge delivered. The first few I tried were painfully slow and not worth recommending.
The Switch 2's display certainly looks larger than that of the original Switch in a side-by-side comparison in the reveal trailer. We actually tested one of them from SanDisk for our microSD card buying guide and found it could reach sequential read speeds up to around 900 MB/s. But again, these rumors are far from concrete.
First of all, its important to note that training a large language model is entirely different than using that same model to answer questions or generate content. Once a model has been trained, it can be put to the test. A head-to-head comparison found that DeepSeek used 87 percent more energy than Metas non-reasoning Llama 3.3
Essentially, Arrow is a standardized in-memory columnar data format with available libraries for several programming languages (C, C++, R, Python, among others). So what better way than testing the impact of the pyarrow engine on all of those at once with minimal effort? And there you have it, folks!
Use your email marketing tool to A/B test different elements. A/B testing is the process of testing out two versions of something by only changing one element. This gives you the opportunity to test different strategies and see what your audience responds to best. Test your website’s user experience.
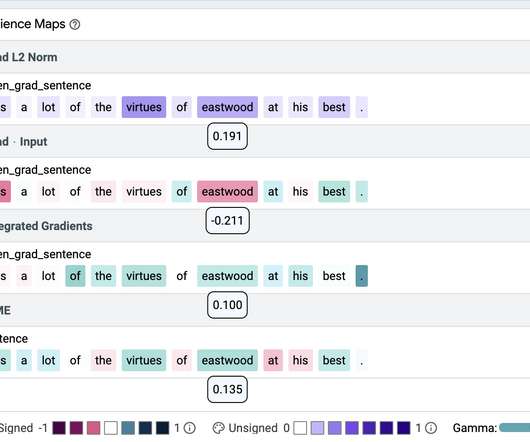
A notorious example from the Natural Language Inference task is relying on negation words when predicting contradiction. Defining Ground Truth Key to our approach is establishing a ground truth that can be used for comparison. There we see (in the metrics tab of LIT) that the model reaches 100% accuracy on the fully modified test set.
We organize all of the trending information in your field so you don't have to. Join 12,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content