This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The Mac Studio is Apples ultimate performance computer, but this years model came with a twist: Its equipped with either an M4 Max or an M3 Ultra processor. While the M3 Ultra model appears highly capable for creative pros and engineers, it starts at $4,000 and goes way up from there. It took me one minute and 51 seconds to output a 3.5
He ditched radar from Tesla’s production models in 2021, against the criteria of his own engineers ,opting instead for his camera-based AI Tesla Vision system, which relies on cameras and AI alone. For comparison, Rober also tested a Lexus RX equipped with Lidar under the same conditions.
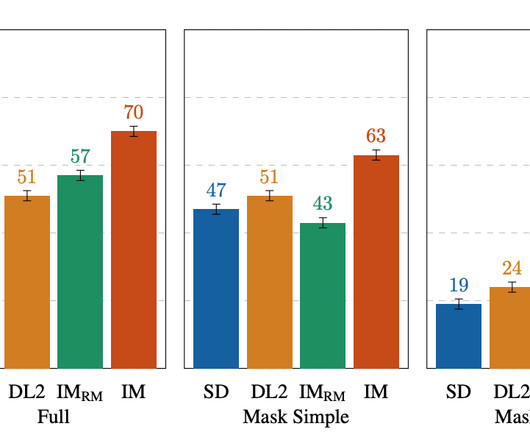
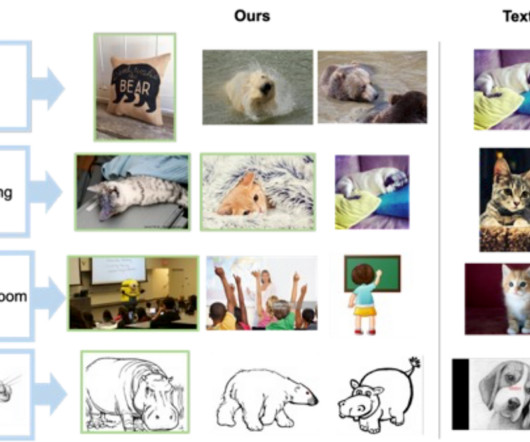
Further, TGIE represents a substantial opportunity to improve training of foundational models themselves. We also introduce EditBench , a method that gauges the quality of image editing models. The model meaningfully incorporates the user’s intent and performs photorealistic edits. First, unlike prior inpainting models (e.g.,
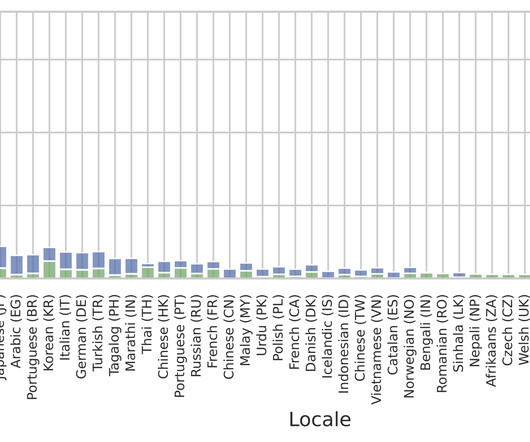
Posted by Thibault Sellam, Research Scientist, Google Previously, we presented the 1,000 languages initiative and the Universal Speech Model with the goal of making speech and language technologies available to billions of users around the world. Such evaluation is a major bottleneck in the development of multilingual speech systems.
” The tranche, co-led by General Catalyst and Andreessen Horowitz, is a big vote of confidence in Hippocratic’s technology, a text-generating model tuned specifically for healthcare applications. “The language models have to be safe,” Shah said. But can a language model really replace a healthcare worker?
Youve given the iPhone , all models of the iPad , AirPods , MacBooks and both the flagship and premium smartwatches updates since then but not the budget smartwatch. I love getting my hands on novel tech, analyzing, evaluating and experiencing a device (then giving it back when Im done so I dont have to accumulate more stuff).
Posted by Fabian Pedregosa and Eleni Triantafillou, Research Scientists, Google Deep learning has recently driven tremendous progress in a wide array of applications, ranging from realistic image generation and impressive retrieval systems to language models that can hold human-like conversations.
I will begin with a discussion of language, computer vision, multi-modal models, and generative machine learning models. Language Models The progress on larger and more powerful language models has been one of the most exciting areas of machine learning (ML) research over the last decade. Let’s get started!
It usually involves a cross-functional team of ML practitioners who fine-tune the models, evaluate robustness, characterize strengths and weaknesses, inspect performance in the end-use context, and develop the applications. Participants could not quickly and interactively alter the input data or tune the model.
In “ A deep learning model for novel systemic biomarkers in photos of the external eye: a retrospective study ”, published in Lancet Digital Health , we show that a number of systemic biomarkers spanning several organ systems (e.g., A model generating predictions for an external eye photo. due to the multiple comparisons problem ).
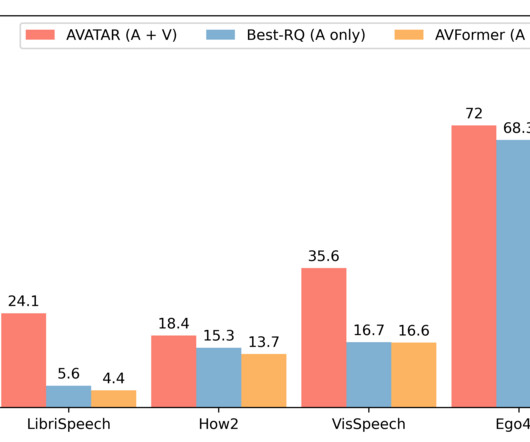
Building audiovisual datasets for training AV-ASR models, however, is challenging. In contrast, the models themselves are typically large and consist of both visual and audio encoders, and so they tend to overfit on these small datasets. LibriSpeech ). LibriSpeech ). Unconstrained audiovisual speech recognition.
Posted by Ziniu Hu, Student Researcher, and Alireza Fathi, Research Scientist, Google Research, Perception Team There has been great progress towards adapting large language models (LLMs) to accommodate multimodal inputs for tasks including image captioning , visual question answering (VQA) , and open vocabulary recognition.
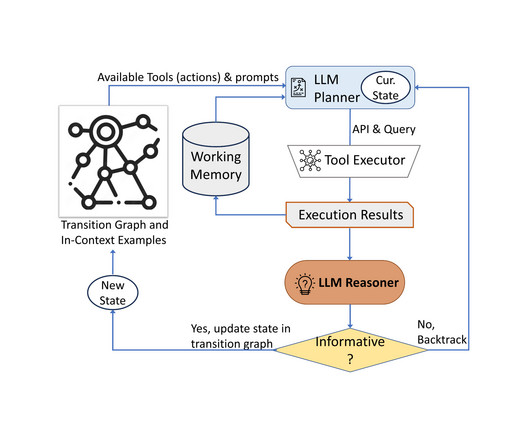
Posted by Shunyu Yao, Student Researcher, and Yuan Cao, Research Scientist, Google Research, Brain Team Recent advances have expanded the applicability of language models (LM) to downstream tasks. On the other hand, recent work uses pre-trained language models for planning and acting in various interactive environments (e.g.,
In particular, Transformers models have achieved stunning advances across various data modalities in real-world machine learning (ML) problems. For example, multimodal architectures have enabled robots to leverage Transformer-based language models for high-level planning.
Addressing the Key Mandates of a Modern Model Risk Management Framework (MRM) When Leveraging Machine Learning . The regulatory guidance presented in these documents laid the foundation for evaluating and managing model risk for financial institutions across the United States.
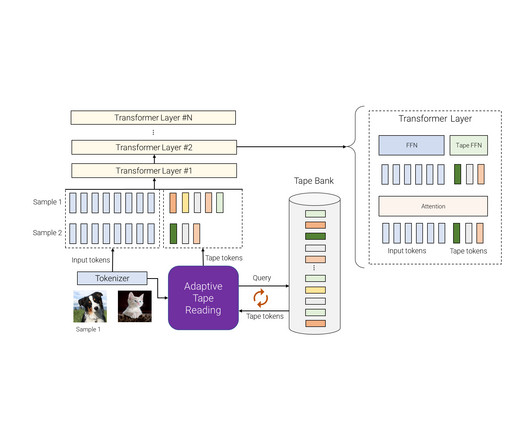
While conventional neural networks have a fixed function and computation capacity, i.e., they spend the same number of FLOPs for processing different inputs, a model with adaptive and dynamic computation modulates the computational budget it dedicates to processing each input, depending on the complexity of the input.
In this installment, I’ll cover four key elements of trusted AI that relate to the performance of a model: data quality, accuracy, robustness and stability, and speed. The performance of any machine learning model is tightly linked to the data it was trained on and validated against. Quality Input Means Quality Output.
Posted by Yicheng Fan and Dana Alon, Software Engineers, Google Research Every byte and every operation matters when trying to build a faster model, especially if the model is to run on-device. Using a search space built on backbones taken from MobileNetV2 and MobileNetV3 , we find models with top-1 accuracy on ImageNet up to 4.9%
Last time , we discussed the steps that a modeler must pay attention to when building out ML models to be utilized within the financial institution. In summary, to ensure that they have built a robust model, modelers must make certain that they have designed the model in a way that is backed by research and industry-adopted practices.
Posted by Ziniu Hu, Student Researcher, and Alireza Fathi, Research Scientist, Google Research, Perception Team Large-scale models, such as T5 , GPT-3 , PaLM , Flamingo and PaLI , have demonstrated the ability to store substantial amounts of knowledge when scaled to tens of billions of parameters and trained on large text and image datasets.
But it certainly is something to evaluate, and contribute to, if you find it useful. Salesforce has a rich enough data model and development platform to sustain a solid CMS – the big question is – is this the right fit in terms of integration? There are a couple of others, and I’m sure more in development.
Collecting such labeled data is costly, and models trained on this data are often tailored to a specific use case, limiting their ability to generalize to different datasets. Description of existing composed image retrieval model. We train a composed image retrieval model using image-caption data only.
Specifically, our wildfire tracker models use the GOES-16 and GOES-18 satellites to cover North America, and the Himawari-9 and GK2A satellites to cover Australia. Model Prior work on fire detection from satellite imagery is typically based on physics-based algorithms for identifying hotspots from multispectral imagery. μm and 11.2
We’ve thought through the pros and cons of both providers to offer a full comparison that will help you as you shop for the right software for your mission. Costs Nonprofit Cloud and NPSP have similar pricing models. Evaluate the support and training available.
Huawei and Chinese automaker Chery on Tuesday began taking orders for the second model under their premium electric vehicle brand Luxeed, priced between RMB 268,000 and RMB 348,000 ($37,654 and $48,894) and featuring what an executive called the worlds most advanced driver assistance system. By comparison, Tesla FSD users surpassed 1.3
This donor management software comparison will go over the features of some of the most popular options so you can make the right choice for your organization. Our revenue-based pricing model makes us a particularly desirable option for rapidly growing organizations. Let’s take a look. Now, we are admittedly a little biased.
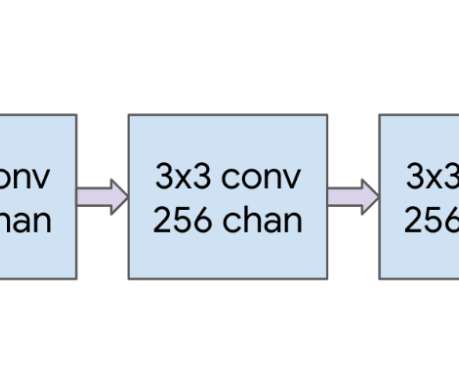
Posted by Piotr Padlewski and Josip Djolonga, Software Engineers, Google Research Large Language Models (LLMs) like PaLM or GPT-3 showed that scaling transformers to hundreds of billions of parameters improves performance and unlocks emergent abilities. At first, the new model scale resulted in severe training instabilities.
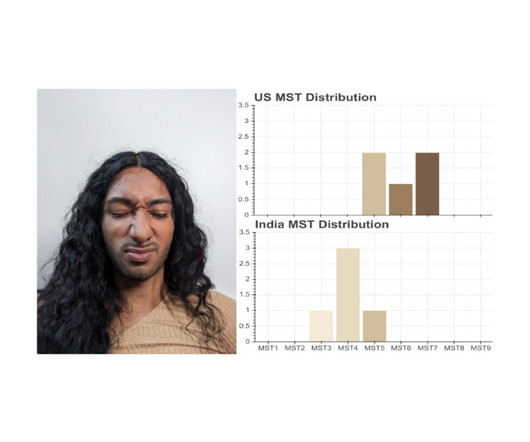
The study highlights the importance for computer researchers and practitioners to evaluate their technologies across the full range of skin tones and at intersections of identities. The MST-E image set contains 1,515 images and 31 videos featuring 19 models taken under various lighting conditions and facial expressions. Images by TONL.
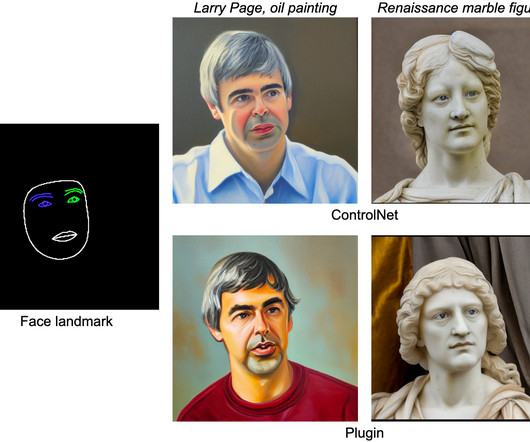
Posted by Yang Zhao and Tingbo Hou, Software Engineers, Core ML In recent years, diffusion models have shown great success in text-to-image generation, achieving high image quality, improved inference performance, and expanding our creative inspiration. Yet, the adapter model is not designed for portable devices.
This work led to the development of Project Relate for anyone with atypical speech who could benefit from a personalized speech model. Built in partnership with Google’s Speech team , Project Relate enables people who find it hard to be understood by other people and technology to train their own models.
An interesting model to use for comparison is Occupy Wall Street. How do you evaluate and recognize “critical mass” of a free agent community? How does your organization evaluate, on the fly in real-time, what critical mass is around a piece of news, an issue, a campaign, or even just an idea?
Every non-profit works with “systems” – internal ones relating to how work gets done, issue systems relating to the topic that the NGO is working to address, and mental model systems about strategy. The production system maps aid an organization to understand how work actually gets done, in comparison to formal org charts.
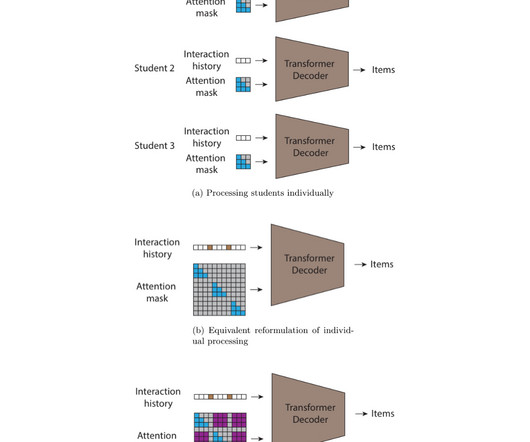
In these systems, ML models are trained to suggest items to each user individually based on user preferences, user engagement, and the items under recommendation. These data provide a strong learning signal for models to be able to recommend items that are likely to be of interest, thereby improving user experience.
Robust algorithm design is the backbone of systems across Google, particularly for our ML and AI models. As an example, for graphs with 10T edges, we demonstrate ~100-fold improvements in pairwise similarity comparisons and significant running time speedups with negligible quality loss. You can find other posts in the series here.)
Posted by Amir Yazdanbakhsh, Research Scientist, and Vijay Janapa Reddi, Visiting Researcher, Google Research Computer Architecture research has a long history of developing simulators and tools to evaluate and shape the design of computer systems. cycle - accurate vs. ML - based proxy models ).
These layout analysis efforts are parallel to OCR and have been largely developed as independent techniques that are typically evaluated only on document images. Below we summarize the characteristics of HierText in comparison with other OCR datasets. As such, the synergy between OCR and layout analysis remains largely under-explored.
Our robotic system combines scalable deep RL from real-world data with bootstrapping from training in simulation and auxiliary object perception inputs to boost generalization, while retaining the benefits of end-to-end training, which we validate with 4,800 evaluation trials across 240 waste station configurations. A diagram of RL at scale.
A comparison of the Axon 20 (left) and Axon 30 (right) under-display screens. We’ll obviously have to wait to try the phone ourselves to give you a full evaluation, but don’t hold your breath for any miracles. Price start at CNY 2,198 ($338) for the 6GB / 128GB model and CNY 3,098 ($476) for the 12GB / 256GB version.
Published on March 12, 2025 5:56 PM GMT Summary The Stages-Oversight benchmark from the Situational Awareness Dataset tests whether large language models (LLMs) can distinguish between evaluation prompts (such as benchmark questions) and deployment prompts (real-world user inputs).
Making apples-to-apples comparisons of these systems was one of the most difficult analytical tasks I’ve taken on in a while (and, actually much of the heavy lifting of designing the analysis was done by Laura Quinn), and until you attempt such a thing, please be somewhat tempered in your complaints about it. Now the security issue.
It also seeks to provide a common baseline of the diversity of the field, as well as ensure that demographic data is available to those who can make use of it to evaluate their programs and assess progress around equity. iv In comparison, the sharing rate for all other staffing levels is below 60%.
Such AI must roughly perform on par with scaling lab research scientists when evaluated on well-scoped person-month tasks. Here, downstream tasks are defined over model input and output distributions. [2] circuit discovery methods and weight-based decompositions) can be evaluated on an equal footing.
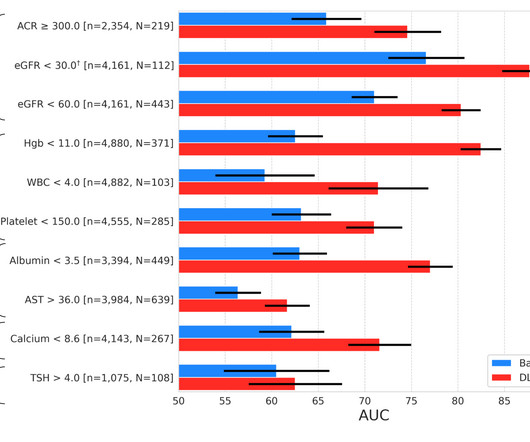
Companies are emphasizing the accuracy of machine learning models while at the same time focusing on cost reduction, both of which are important. In addition to the accuracy of the models we built, we had to consider business metrics, cost, interpretability, and suitability for ongoing operations. Sensor Data Analysis Examples.
CEO and co-founder Eohan George said that they evaluated a number of different robotic solutions but that drones are the only ones that make sense. Drone-based tying seems to offer value one way or the other, but that means the business model is somewhat in flux as SkyMul figures out what makes the most sense.
We organize all of the trending information in your field so you don't have to. Join 12,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content