This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
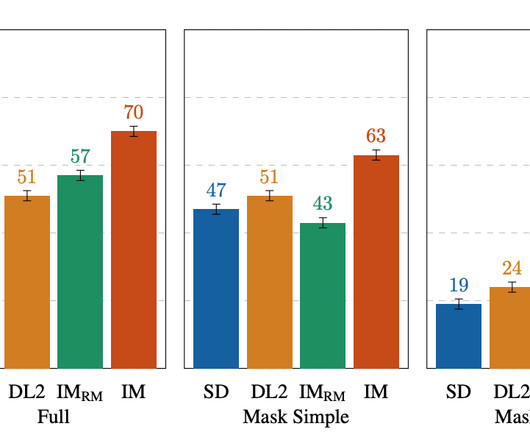
EditBench The EditBench dataset for text-guided image inpainting evaluation contains 240 images, with 120 generated and 120 natural images. Each example consists of (1) a masked input image, (2) an input text prompt, and (3) a high-quality output image used as reference for automatic metrics. simple, rich, and full captions).
After developing a new model, one must evaluate whether the speech it generates is accurate and natural: the content must be relevant to the task, the pronunciation correct, the tone appropriate, and there should be no acoustic artifacts such as cracks or signal-correlated noise. This is the largest published effort of this type to date.
Furthermore, the evaluation of forgetting algorithms in the literature has so far been highly inconsistent. First, by unifying and standardizing the evaluationmetrics for unlearning, we hope to identify the strengths and weaknesses of different algorithms through apples-to-apples comparisons.
It usually involves a cross-functional team of ML practitioners who fine-tune the models, evaluate robustness, characterize strengths and weaknesses, inspect performance in the end-use context, and develop the applications. Sign up to be notified when Visual Blocks for ML is publicly available.
It’s also a valuable tool to help nonprofits evaluate their results by giving them a comparison point for their performance against organizations of similar sizes and issue areas. When looking at online benchmarks and digital revenue, we saw that any growth or ground held was due to increases in sustainer metrics.
Stephen Downes summarized my post on Social Media Metrics and Measuring Blog Outcomes and added some commentary. My post wasa riff on evaluating the effectiveness of blogs, and in particular, a set of metrics from Avinash Kaushik: "Raw Author Contribution (posts and words in post). Some pr professionals agree.
I'm doing a session at Boston podcamp called the Social Media Metrics/ROI Game. I'm slightly out of my comfort zone here because I've only been following this topic closely for a short time, although I have co-authored a guide for nonprofits on technology evaluation and ROI. UPDATE: The presentation slides and wikispace is here.
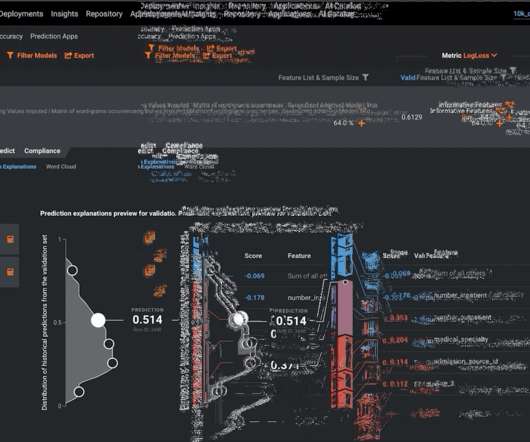
Accuracy is best evaluated through multiple tools and visualizations, alongside explainability features, and bias and fairness testing. Binary classification models are often optimized using an error metric called LogLoss. It enables direct comparisons of accuracy between diverse machine learning approaches. Download Now.
The thing that is prompting this post is the little storm about the security metric that we used to try and get a handle on the security of the 4 different systems we reviewed. The report isn’t about security, it’s a very, very broad comparison of the systems, with security as a very small component. More on that in a bit.
Nonprofit engagement metrics can help you understand your organization, but you’ve probably seen the same terms over and over again in your research. By embracing a few overlooked metrics, you will be able to go deeper into that information. By embracing a few overlooked metrics, you will be able to go deeper into that information.
Using that knowledge, we’ve created this guide to help your team understand major gift KPIs, the metrics you should be tracking, and the top tips to do so successfully. You’ll explore major gift metrics through the following guide: Overview of Major Gift Fundraising Data. 3 Tips to Track Major Gift Metrics More Effectively.
Our experimental evaluation shows that within these constraints we are able to discover top-performance models. Experimental results When comparing NAS algorithms, we evaluate the following metrics: Quality : What is the most accurate model that the algorithm can find? Comparison on models under different #MAdds.
Results We evaluate REVEAL on knowledge-based visual question answering tasks using OK-VQA and A-OKVQA datasets. REVEAL achieves higher accuracy in comparison to previous works including ViLBERT , LXMERT , ClipCap , KRISP and GPV-2. We also evaluate REVEAL on the image captioning benchmarks using MSCOCO and NoCaps dataset.
Human object recognition alignment To find out how aligned ViT-22B classification decisions are with human classification decisions, we evaluated ViT-22B fine-tuned with different resolutions on out-of-distribution (OOD) datasets for which human comparison data is available via the model-vs-human toolbox. Cat or elephant? Car or clock?
This is absolutely a valuable metric, but I was curious how this data might vary if the list was based on organizations with the strongest social media presence.the ones we stand to learn the most from. For each of the six measured criteria, each organization is ranked in comparison to all other nonprofit organizations being evaluated.
(I've definitely added that link to my social media metrics personal learning space ) She recently pointed to a blog post called " Ten Ways To Measure Social Media Success " by Chris Lake. A baseline is a measurement that you can use as a comparison to measure progress against a goal or do before/after comparisons.
Posted by Amir Yazdanbakhsh, Research Scientist, and Vijay Janapa Reddi, Visiting Researcher, Google Research Computer Architecture research has a long history of developing simulators and tools to evaluate and shape the design of computer systems. It comprises two main components: 1) the ArchGym environment and 2) the ArchGym agent.
Further, we will discuss how DataRobot is able to help streamline this process, by providing various diagnostic tools aimed at thoroughly evaluating a model’s performance prior to placing it into production. One approach is to assess the importance of the input variables in the model, and evaluate its impact on the outcome being predicted.
Because of these principles, the process of evaluating and deciding on investments such as technology tools can be difficult for many nonprofits, because it requires a complicated process of weighing short term costs with long term benefits, while keeping multiple stakeholders happy. Get it all in front of you.
Lucy Bernholz, moderating, said that metrics are the carbon in the ecosystem and the oxygen is the policy frame. People are open sourcing their metrics, and building taxonomy. To get the market from niche to mainstream people are working on taxonomy, metrics and peer and trend ratings. Lagging indicators -.
Similar to the engagement meter, a generosity score also provides an at-a-glance view of an important supporter metric. Fundraising metrics. Your dashboard can provide insight into your most important fundraising metrics. This will help you make direct comparisons after you’ve received a demo of each. Blackbaud eTapestry.
The holy grail metrics is missing? Twist analyzes and presents trend comparisons and volume between keywords and tags. The big point is that successful efforts just don't happen on Twitter - it takes social capital, strategy, and the right metrics to track and evaluate what worked and what didn't.
Argument for interpretability automation I focus on the claim that interpretability will likely be automated by training against robust downstream metrics which use interpretability methods. Such AI must roughly perform on par with scaling lab research scientists when evaluated on well-scoped person-month tasks.
Fidelity Results The fidelity metrics focus on the quality of synthetically generated data by measuring the realisticness of the synthetic data. We evaluate the fidelity of synthetic data in terms of multiple quantitative and qualitative analyses. We observe that the privacy metrics are very close to the ideal in all cases.
Just as you’ve finally settled into the shift from Universal Analytics (UA) to Google Analytics 4 (GA4) and started to get a handle on its new metrics, Google has yet another deadline for organizations to meet. By exporting data, users can maintain access to historical comparisons and enable future analysis.
For comparison, Apples iOS operates on more than 2 billion active devices worldwide, including more than 1.5 Pahlka has done work with Stanfords Regulation, Evaluation, and Governance Lab ( RegLab ), which is studying the development of LLMs that specialize in swimming through years of policies, guidelines, and regulations.
As an example, for graphs with 10T edges, we demonstrate ~100-fold improvements in pairwise similarity comparisons and significant running time speedups with negligible quality loss. We had previously applied this idea to develop massively parallel algorithms for metric , and minimum-size clustering.
We’ll cover everything from understanding the role of an LMS in compliance training to evaluating different LMS options. We’ll also touch on planning and executing a successful LMS implementation. One effective way to do this is by creating a comparison chart or matrix.
We’ll cover everything from understanding the role of an LMS in compliance training to evaluating different LMS options. We’ll also touch on planning and executing a successful LMS implementation. One effective way to do this is by creating a comparison chart or matrix.
It also seeks to provide a common baseline of the diversity of the field, as well as ensure that demographic data is available to those who can make use of it to evaluate their programs and assess progress around equity. iv In comparison, the sharing rate for all other staffing levels is below 60%.
to care a whole lot about how many hits they got in comparison to similar (or different) organizations. It wasn’t meant as a statement about what I think about whether or not web stats are a useful metric of much. Other metrics we look at include: What are our sign-ups for our newsletter? David 4 Kivi Miller 09.18.07
By many metrics, this has been a banner year for Twitter. But Twitter is publicly traded, and its slow growth (particularly in comparison to the behemoth Facebook) has long rankled investors. Elliott wins in the end? The two questions you want to ask when a CEO steps down are: why now? And what next? Let’s start with the first one.
In addition to the accuracy of the models we built, we had to consider business metrics, cost, interpretability, and suitability for ongoing operations. Ultimately, the evaluation is based on whether or not the model delivers success to the customers’ business. Comparison before and after Kalman filter processing.
“Of course,” he notes, “self-evaluation is hard, especially when you’re asking someone else to pay you for something you’ve created.” He breaks down the value of Afterpay, Paidy and Klarna using a simple metric: What would you pay for $1 of BNPL GMV? ” 3 keys to pricing early-stage SaaS products.
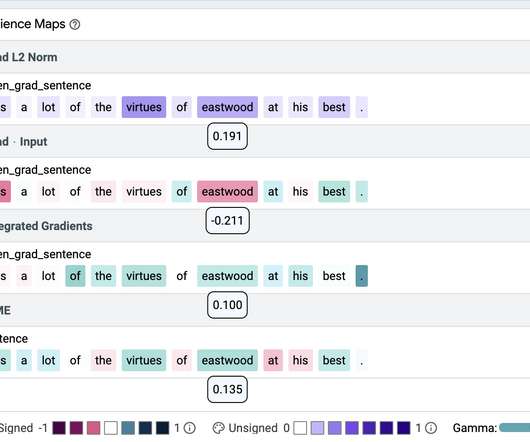
A Protocol for Evaluating the Faithfulness of Input Salience Methods for Text Classification ”, to appear at EMNLP , we propose a protocol for evaluating input salience methods. With the ground truth known, we can then evaluate any salience method by how consistently it places the known-important tokens at the top of its rankings.
It’s a time to focus on evaluating what fundraising approaches from 2020 worked and be honest about what didn’t pan out as planned. So, after you’ve mapped out your goals, the next step we recommend taking involves “looking backwards” to critically evaluate the fundraising activities of your previous year. And by what time frame?
In this post, I point to several problems with the way we currently evaluate ANN indexes and suggest a new type of evaluation. The standard way to evaluate ANN indexes is to use a static workload benchmark , which consists of a fixed dataset and a fixed query set. Completeness: insert and delete operations are also evaluated.
Workbook Optimizer evaluates content against best practices and gives actionable recommendations for improving performance. Beyond traditional workbooks, your users can also leverage Metrics , a content type designed specifically for mobile. Improve load times and performance with Workbook Optimizer and View Acceleration.
Workbook Optimizer evaluates content against best practices and gives actionable recommendations for improving performance. Beyond traditional workbooks, your users can also leverage Metrics , a content type designed specifically for mobile. Improve load times and performance with Workbook Optimizer and View Acceleration.
Evaluate your websites revenue and costs holistically to determine the current return on various investments made to build and improve the site. Your websites donation page conversion rate is among the most important metrics to track when evaluating your nonprofit websites ROI. Track key metrics.
After you've been able to use metrics to learn what works and adapt your approach, you can use a traditional approach which begins with defining value and culminates with a financial calculation that could go something like this. It uses metrics to measure your results and help you improve your strategy over time. Defined Audience.
The regulatory guidance presented in these documents laid the foundation for evaluating and managing model risk for financial institutions across the United States. Comparison with alternative theories and approaches is a fundamental component of a sound modeling process.
The evaluation of these metrics is a non-trivial process I’m not equipped to do, but truthfully either one would be a game-changing upgrade for a phone. That leads to the company’s claim of having 11 times the “imaging area” of an iPhone. Bigger, brighter and a bit weirder. Image Credits: Glass.
We organize all of the trending information in your field so you don't have to. Join 12,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content