This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
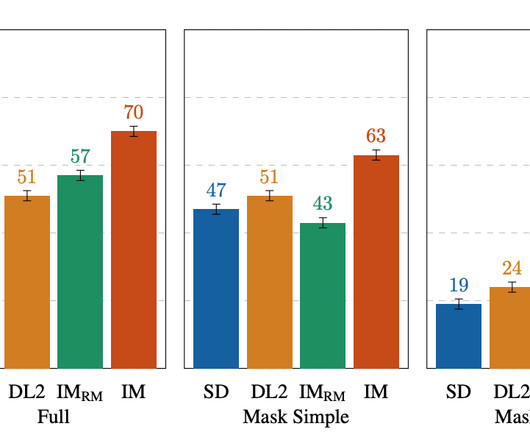
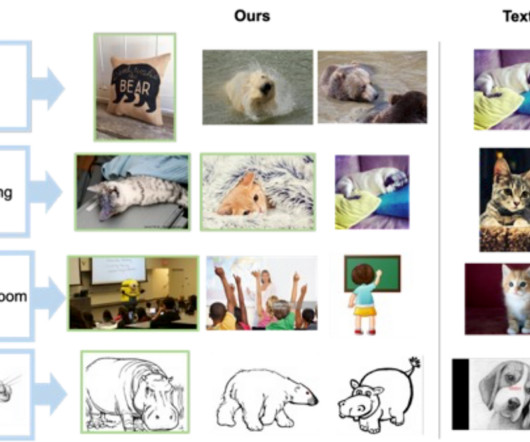
EditBench The EditBench dataset for text-guided image inpainting evaluation contains 240 images, with 120 generated and 120 natural images. We evaluate Mask Simple, Mask Rich and Full Image prompts, consistent with conventional text-to-image models. In the section below, we demonstrate how EditBench is applied to model evaluation.
He created a polystyrene wall with an image of a road printed on it and placed it in the middle of a real street to evaluate the reaction of the sensors in his own Tesla Model Y, which relies only on cameras. For comparison, Rober also tested a Lexus RX equipped with Lidar under the same conditions.
However, the best way to evaluate a machine like this is to feed it some content creation jobs and see how quickly it chews through them. For comparisons sake, my MacBook Pro with an M3 Pro processor took over twice as long at four minutes and 10 seconds. It took me one minute and 51 seconds to output a 3.5
With the year half way over, this is the perfect time to evaluate your progress so far. Once you’ve done a side-by-side comparison of the first half of the year, it’s time to look to the future. Let’s check out what to consider when measuring your results. This Year Vs. Last Year. What’s Your Projected Income? Advantages and Obstacles.
After developing a new model, one must evaluate whether the speech it generates is accurate and natural: the content must be relevant to the task, the pronunciation correct, the tone appropriate, and there should be no acoustic artifacts such as cracks or signal-correlated noise. This is the largest published effort of this type to date.
Check out the following breakdown of offerings you may want to consider when evaluating fundraising solutions. Do your due diligence by reading third party software evaluations. Print a copy of this checklist for each system you’re evaluating. Does the company have any certifications with other well-known companies?
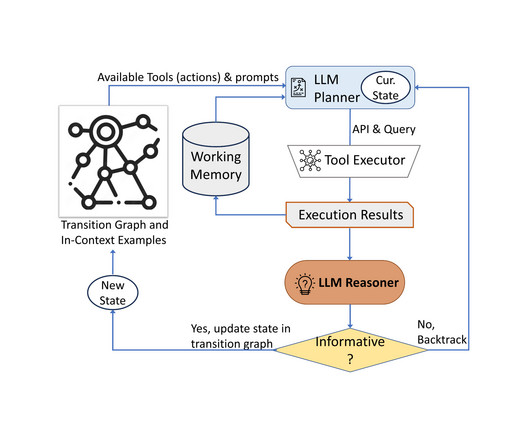
It usually involves a cross-functional team of ML practitioners who fine-tune the models, evaluate robustness, characterize strengths and weaknesses, inspect performance in the end-use context, and develop the applications. Sign up to be notified when Visual Blocks for ML is publicly available.
The comparison with a clinicodemographic baseline is useful because risk for some diseases could also be assessed using a simple questionnaire , and we seek to understand if the model interpreting images is doing better. due to the multiple comparisons problem ). A model generating predictions for an external eye photo.
Furthermore, the evaluation of forgetting algorithms in the literature has so far been highly inconsistent. First, by unifying and standardizing the evaluation metrics for unlearning, we hope to identify the strengths and weaknesses of different algorithms through apples-to-apples comparisons.
This methodology was used to evaluate expanding the American Board of Medical Specialties, ABMS CertLink®, platform into new markets. But that’s where the comparisons to Ringling Brothers Barnum and Bailey end. Blue Ocean Strategy was used to evaluate the potential for promoting the product to new markets.
I love getting my hands on novel tech, analyzing, evaluating and experiencing a device (then giving it back when Im done so I dont have to accumulate more stuff). Ive used the ECG reading exactly once to test it out for comparison on another smartwatch review. But this review left me cold. Thats fine.
We’ve thought through the pros and cons of both providers to offer a full comparison that will help you as you shop for the right software for your mission. Evaluate the support and training available. As noted above, both Blackbaud and Salesforce offer a variety of support resources.
This donor management software comparison will go over the features of some of the most popular options so you can make the right choice for your organization. But Neon CRM stands out in our donor management software comparison because it’s truly built with scalability in mind. Let’s take a look. Now, we are admittedly a little biased.
Accuracy is best evaluated through multiple tools and visualizations, alongside explainability features, and bias and fairness testing. It enables direct comparisons of accuracy between diverse machine learning approaches. The post Trusted AI Cornerstones: Performance Evaluation appeared first on DataRobot. Download Now.
Real-world robot navigation Although, in principle, Performer-MPC can be applied in various robotic settings, we evaluate its performance on navigation in confined spaces with the potential presence of people. We evaluate Performer-MPC in a simulation and in three real world scenarios.
But it certainly is something to evaluate, and contribute to, if you find it useful. I’ve spent quite a bit of time with this one, and more to come, I’m sure – like any open source project, there is a lot that could be done to make it more usable.
Variables possess the value a trigger requires to evaluate to know if it should fire. After comparison, if the variable meets the trigger’s conditions, the tag will fire. Variables and Constants. While tags rely on triggers, triggers rely on variables. The tag compares the variable’s value to the defined value in the trigger.
Evaluation We conduct a variety of experiments to evaluate Pic2Word’s performance on a variety of CIR tasks. Domain conversion We first evaluate the capability of compositionality of the proposed method on domain conversion — given an image and the desired new image domain (e.g., Overview of CIR for fashion attributes.
In addition to the detailed review of 11 systems -- including both proprietary and open source -- the report provides some helpful overview for approaching the CMS evaluation process in general, as well as some recommendations for making your selection process more focused and effective.
Our experimental evaluation shows that within these constraints we are able to discover top-performance models. Experimental results When comparing NAS algorithms, we evaluate the following metrics: Quality : What is the most accurate model that the algorithm can find? Comparison on models under different #MAdds.
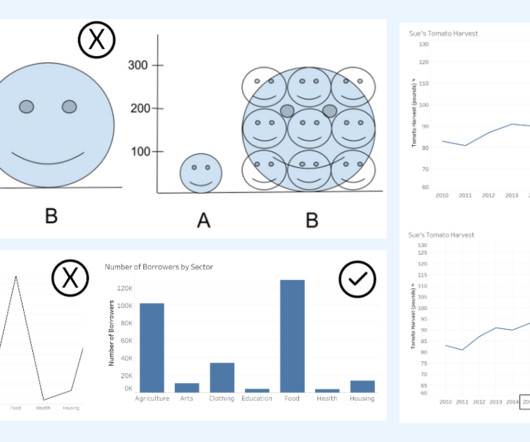
When communicating with data, viewing a chart instead of a table of numbers can help us very quickly understand our data, make comparisons, see patterns or trends, and use that information to make better decisions. When viewing summary numbers, evaluate if the summary number is appropriate.
Evaluation High-resolution fire signals from polar-orbiting satellites are a plentiful source for training data. To evaluate our wildfire tracker model without such bias, we compared it against fire scars (i.e., Example evaluation for a single fire. The results of the evaluation are summarized below.
Results We evaluate REVEAL on knowledge-based visual question answering tasks using OK-VQA and A-OKVQA datasets. REVEAL achieves higher accuracy in comparison to previous works including ViLBERT , LXMERT , ClipCap , KRISP and GPV-2. We also evaluate REVEAL on the image captioning benchmarks using MSCOCO and NoCaps dataset.
It’s also a valuable tool to help nonprofits evaluate their results by giving them a comparison point for their performance against organizations of similar sizes and issue areas. It’s a reliable touchstone to identify giving trends as well as shifts in sustainer and email engagement in the nonprofit digital space.
An interesting model to use for comparison is Occupy Wall Street. How do you evaluate and recognize “critical mass” of a free agent community? How does your organization evaluate, on the fly in real-time, what critical mass is around a piece of news, an issue, a campaign, or even just an idea? Five hundred people?
Vrbo previously stated it was evaluating new bookings and that it would “take appropriate action in coordination with law enforcement” if necessary. In comparison, Airbnb not only blocked new reservations, but it canceled existing ones as well.
years now, and in comparison to Twitter, LinkedIn, MySpace and YouTube, the Facebook Page tool set is pretty limited. We encourage users to report such content and we have a large team of professional reviewers who evaluate these reports and take action per our policies.”. I have been working social media sites daily for 4.5
Comparison to previous work Recent studies (e.g., Results We evaluate AVIS on Infoseek and OK-VQA datasets. AVIS achieves higher accuracy in comparison to previous baselines based on PaLI , PaLM and OFA. AVIS achieves lower but comparable accuracy in comparison to the PALI model fine-tuned on OK-VQA.
Alex Wilhelm and Anna Heim wrapped up TechCrunch’s coverage of the summer cohort from Y Combinator’s Demo Day with an evaluation of how the group fared in comparison to their expectations. Cohort analysis is what it sounds like: evaluating your startup’s customers by grouping them into “cohorts” and observing their behavior over time.
We evaluated the power of “why” questions for your donors in a recent webinar. Rather than another organization… ”: Donors will make comparisons between your organizations and other similar organizations. If you already have a value proposition written, you can use these elements to evaluate its relative strengths and weaknesses.
For each of the six measured criteria, each organization is ranked in comparison to all other nonprofit organizations being evaluated. Data is collected for each nonprofit from all six measured criteria (i.e., A composite rank for each nonprofit is determined based on the included criteria in each list. See links for more details.
A baseline is a measurement that you can use as a comparison to measure progress against a goal or do before/after comparisons. His post "The Apollo and Dionysus of digital evaluation " talks about finding the right mashup between numbers and stories using mythology metaphors. Make a note of the obvious numb ers.
After co-founder and CEO Munjal Shah sold his previous company, Like.com, a shopping comparison site, to Google in 2010, he spent the better part of the next decade building Hippocratic. Like Hippocratic’s model, Med-PaLM 2 was evaluated by health professionals on its ability to answer medical questions accurately — and safely.
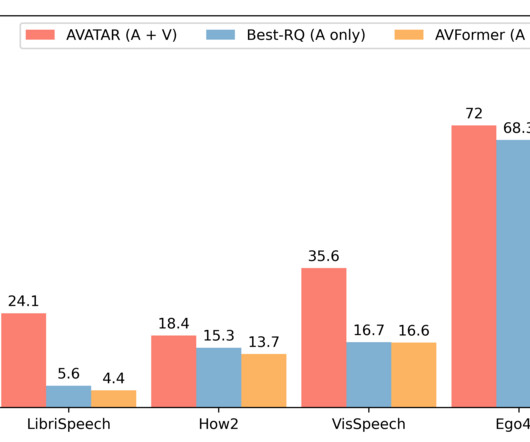
We evaluated our extended model on AV-ASR benchmarks in a zero-shot setting, where the model is never trained on a manually annotated AV-ASR dataset. Moreover, we also evaluate performance on LibriSpeech, which is audio-only, and AVFormer outperforms both baselines. We also show performances on LibriSpeech which is audio-only.
Human object recognition alignment To find out how aligned ViT-22B classification decisions are with human classification decisions, we evaluated ViT-22B fine-tuned with different resolutions on out-of-distribution (OOD) datasets for which human comparison data is available via the model-vs-human toolbox. Cat or elephant? Car or clock?
Making apples-to-apples comparisons of these systems was one of the most difficult analytical tasks I’ve taken on in a while (and, actually much of the heavy lifting of designing the analysis was done by Laura Quinn), and until you attempt such a thing, please be somewhat tempered in your complaints about it. Now the security issue.
Evaluate cross-functional process flow. It is critical to stop and take the time to evaluate the cross-functionality of all school areas. In a connected school, processes must be continuously evaluated and modified for the best outcome for the greater good. Schools face many challenges when their systems are disconnected.
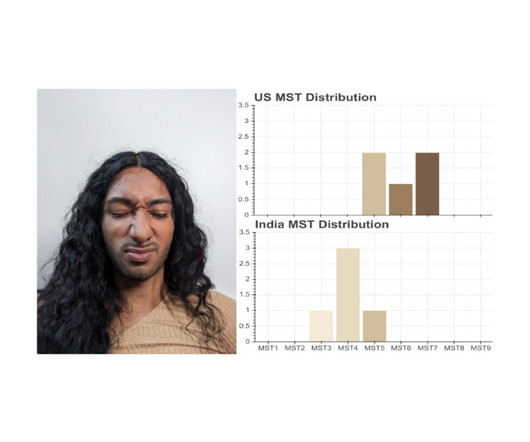
The study highlights the importance for computer researchers and practitioners to evaluate their technologies across the full range of skin tones and at intersections of identities.
8 lines in the comparison group (though some kids saw improvements of two or more lines at the 12-week follow-up visit). . Luminopia’s most recently published trial follows a single-arm pilot trial, which evaluated the technology’s at nine sites, and on a total of 84 participants. lines on a standard eye chart, compared to.8
A comparison of the Axon 20 (left) and Axon 30 (right) under-display screens. We’ll obviously have to wait to try the phone ourselves to give you a full evaluation, but don’t hold your breath for any miracles. Image: ZTE via GSMArena. ZTE says it’s also improved the under-display camera itself.
Because of these principles, the process of evaluating and deciding on investments such as technology tools can be difficult for many nonprofits, because it requires a complicated process of weighing short term costs with long term benefits, while keeping multiple stakeholders happy. Get it all in front of you.
In comparison, project grants are more complicated to report on. Grant reporting helps nonprofits evaluate their efforts and be transparent. These tend to be the easiest to report on, because they can usually be completed by the development team with a pre-prepared overview of what the organization is working on.
As for the comparison with other firms, Krishna said, “there is no right or wrong way to operate.”. It’s beginning to evaluate where else it can formally launch its offerings.). He said the startup still has to spend about half of the $100 million that it raised in its previous financing round last year. Vedantu co-founders.
We organize all of the trending information in your field so you don't have to. Join 12,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content