This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amtrak has revealed a first look at its new Airo trains, and they come with panoramic windows, comfier chairs, and more accessibility features. The national rail service is currently constructing 83 of the new-and-improved Airo trains, which will operate on around 15 existing routes in the Eastern U.S. and Pacific Northwest.
How to Leverage LMS Data Analytics for Better Decision-Making in Corporate Training GyrusAim LMS GyrusAim LMS - In today’s competitive business landscape, Learning and Development (L&D) programs are key drivers of employee growth, retention, and overall business success. billion in 2020–21.
Benchmarks created to assess the performance of AI tools compared with humans on tasks such as image classification, visual reasoning, and English understanding show the gaps narrowing. As of May 2024, the MMMU benchmark , which evaluates responses to college-level questions, scored GPT-4o at 60%, compared with an 83% human average.
There’s nothing like that feeling of hearing your train pull up to the station, shoving your way past the people who just stand there on the escalator, sprinting across the crowded platform… and then having the doors close right in front of your face before the train pulls away. So close! . The full webinar recording is available here.
The key to both is a deeper understanding of ML data — how to engineer training datasets that produce high quality models and test datasets that deliver accurate indicators of how close we are to solving the target problem. Each step can introduce issues and biases. LAION or The Pile ).
Hoping to hop on the 2022 Benchmarkstrain? This Friday (December 3) is the last day to sign up to be part of the next Benchmarks journey ! And please reach out to benchmarks@mrss.com with any questions. The annual M+R Benchmarks Study is a wide-ranging exploration of digital fundraising, advocacy, and marketing data.
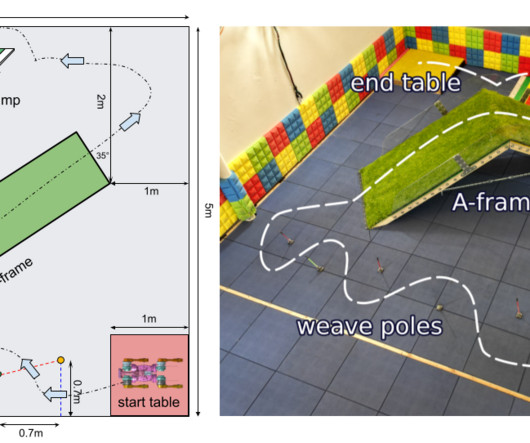
Yet, while researchers have enabled robots to hike or jump over some obstacles , there is still no generally accepted benchmark that comprehensively measures robot agility or mobility. Overview of the Barkour benchmark’s obstacle course setup, which consists of weave poles, an A-frame, a broad jump, and pause tables.
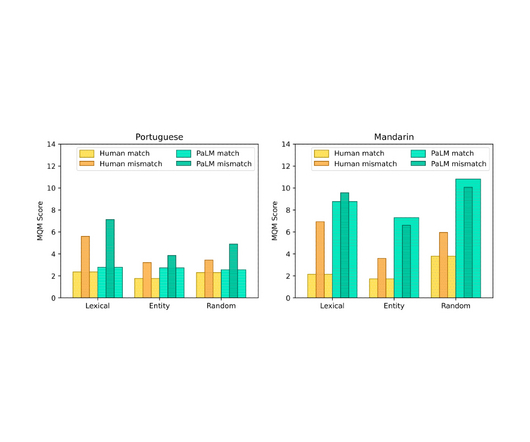
However, the vast majority of available training data doesn’t specify what regional variety the translation is in. In light of this data scarcity, we position FRMT as a benchmark for few-shot translation, measuring an MT model’s ability to translate into regional varieties when given no more than 100 labeled examples of each language variety.
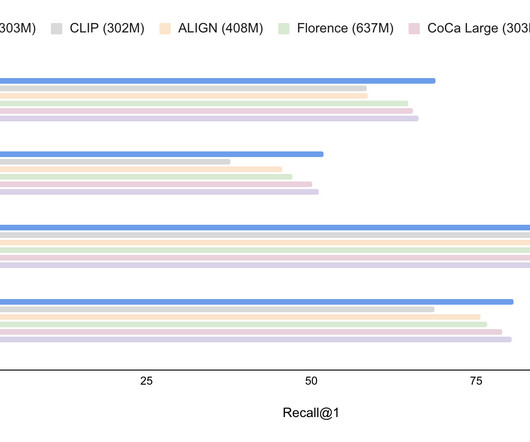
Posted by Ziniu Hu, Student Researcher, and Alireza Fathi, Research Scientist, Google Research, Perception Team Large-scale models, such as T5 , GPT-3 , PaLM , Flamingo and PaLI , have demonstrated the ability to store substantial amounts of knowledge when scaled to tens of billions of parameters and trained on large text and image datasets.
Previously, the stunning intelligence gains that led to chatbots such ChatGPT and Claude had come from supersizing models and the data and computing power used to train them. The big AI labs would now need even more of the Nvidia GPUs theyd been using for training to support all the real-time reasoning their models would be doing.
Benchmarking against peers can help you refine your assumptions about what being financially sustainable could look likeor develop entirely new assumptions. In this article, well outline a three-step process adapted from our report Finding Your Funding Strategy: Benchmarking 101 , tailored to U.S.-based But where should you start?
Lately, a deluge of AI bots training on Wikipedia articles has put enormous strain on the organization's servers. To curb the influx of "non-human traffic" scraping the site for training data, Wikipedia is taking a proactive approach: serving up its data directly to AI developers.
Pre-training on diverse datasets has proven to enable data-efficient fine-tuning for individual downstream tasks in natural language processing (NLP) and vision problems. So, we ask the question: Can we enable similar pre-training to accelerate RL methods and create a general-purpose “backbone” for efficient RL across various tasks?
In multiple benchmark tests, it outperformed other open-source models such as Qwen2.5-72B DeepSeek investor High-Flyer Quant has emphasized in a published paper that the model was trained at exceptionally low costs. The original DeepSeek-V3 gained worldwide attention for its cost-effectiveness. 72B and Llama-3.1-405B,
The A14 is an ideal machine for writing on the go, since you can travel with it effortlessly and it offers a whopping 18 hours and 16 minutes of battery life (according to the PCMark 10 benchmark). In the PCMark 10 battery benchmark, the Zenbook A14 lasted 18 hours and 16 minutes.
I would bet that lie-proof benchmarks will be difficult and expensive to make and that the lie-proofing techniques won't easily generalize outside of coding tasks. It has been shown (on Atari, in 2018) that genetic algorithms / evolution strategies can train agents with <10x the flops required by RL+backprop+SGD.
Train and have them in place by April 15.Owner: For example, if youre launching a year-round fundraising campaign, set clear benchmarks for securing champions, completing toolkits, and tracking participation levels. Owner: Development Director. Recruit two volunteers to join the board development committee. Owner: Development Team.
In “ Pre-trained Gaussian processes for Bayesian optimization ”, we consider the challenge of hyperparameter optimization for deep neural networks using BayesOpt. HyperBO pre-trains a Gaussian process model on data from those selected tasks, and automatically defines the model parameters before running BayesOpt.
Rather than largely relying on stochastic methods to provide an answer, the o-series models are trained to "refine their thinking process, try different strategies, and recognize their mistakes." ” Evaluation benchmarks are tricky. Plus, some rely on different benchmarks and methods to test accuracy and hallucinations.
This point is key: If OpenAI had its servers pronouncing every sentence that ChatGPT generates, out loud, one at a time, as part of its training process, it probably wouldve taken millennia to get to todays abilities. Each new model only requires months or a few years of training because the process happens much, much faster than real time.
At age 5, however, they were already giving signs of their extraordinary potentialparticularly to the trained eye (e.g., scouts, teachers, mentors, and critics) they appeared to show evidence of an enormous capacity for developing future talent, turning them not so much into a promise, but a rather safe bet.
However, modern object detectors are limited by the manual annotations of their training data, resulting in a vocabulary size significantly smaller than the vast array of objects encountered in reality. Thus, it could be beneficial for open-vocabulary detection if we build locality information into the image-text pre-training.
It consists of two major components: an open dataset of egocentric video and a series of benchmarks that Facebook thinks AI systems should be able to tackle in the future. The ImagetNet datasets consists of pictures of a huge variety of objects which researchers trained AI systems to identify. Where did I leave my keys?”)?
Over those three years, Nonprofit Tech for Good and PIR trained more than 60,000 NPO and NGO staff worldwide! Due to the decline in reach on social media, nonprofits should prioritize email communications and fundraising in 2018 [ Benchmarks for Success ]. You can view the webinar archive on SlideShare. The Internet of Things.
But the following characteristics are universal to an approach that puts people first: Empower and educate Invest in training. Include benchmarks in goals and KPIs. Put People First Your data governance policy will be a document that reflects your organization’s unique culture, teams, and members.
In fact, training a single advanced AI model can generate carbon emissions comparable to the lifetime emissions of a car. Machine learning algorithms can now diagnose diseases, predict climate patterns, and solve complex problems that would’ve seemed like science fiction just a decade ago.
Lambda Labs new 1-Click service provides on-demand, self-serve GPU clusters for large-scale model training without long-term contracts. In 2024, it launched 1-Click Clusters, a service that provides AI startups and engineers with the first on-demand, self-serve GPU clusters for AI model training.
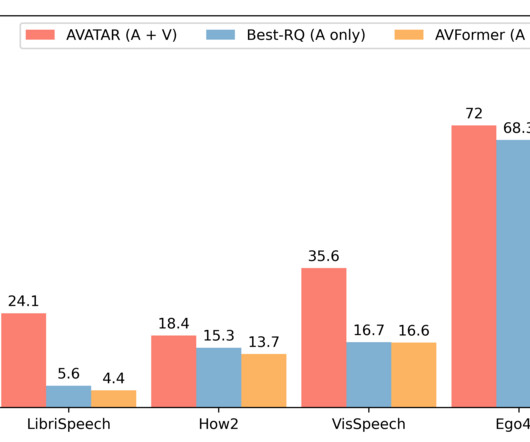
Building audiovisual datasets for training AV-ASR models, however, is challenging. Nonetheless, there have been a number of recently released large-scale audio-only models that are heavily optimized via large-scale training on massive audio-only data obtained from audio books, such as LibriLight and LibriSpeech. LibriSpeech ).
Intel could reveal its Alder Lake-S processors for enthusiasts as soon as next week, but the ongoing stream of leaks is slowly driving the hype train off the cliff. The upcoming Core i9-12900K CPU has been spotted in a series of benchmarks where it shows its teeth to AMD’s Ryzen.
Over the holidays, I used DataRobot to reproduce a few machine learning benchmarks. The goal was to split the data at this point so that you could train on the data known at prediction time. Unfortunately, the code was not written correctly; there was contamination from the future in the training data. Do you see it?
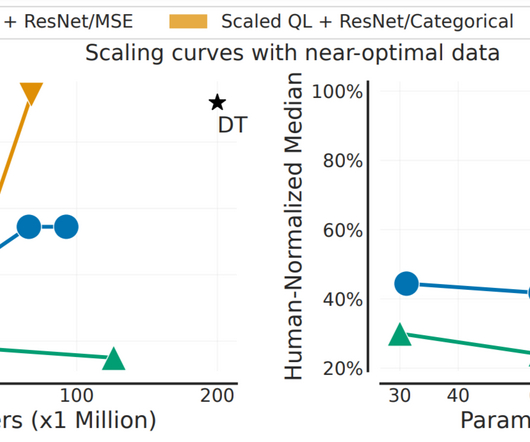
A number of neural network–based solutions have been able to show good performance on benchmarks and also support the above criterion. However, these methods are typically slow to train and can be expensive for inference, especially for longer horizons. Left: MSE on the test set of a popular traffic forecasting benchmark.
Foundation Models Defined A foundation model is an AI neural network trained on mountains of raw data, generally with unsupervised learning that can be adapted to accomplish a broad range of tasks. This chart highlights the exponential growth in training compute requirements for notable machine learning models since 2012.
The accepted best practice is to post to Instagram once to three times daily, but for most nonprofits posting more than once daily is a ridiculous benchmark. To reach the 10,000 follower benchmark, send an email to your list asking your supporters to follow you on Instagram or purchase advertising to secure more followers.
USM is a family of state-of-the-art speech models with 2B parameters trained on 12 million hours of speech and 28 billion sentences of text, spanning 300+ languages. Moreover, our model training process is effective at adapting to new languages and data. The last step of the training pipeline is to fine-tune on downstream tasks (e.g.,
WebFX is an excellent resource for social media advertising benchmarks and their research reveals that Twitter has the lowest cost-per-click (CPC) of all social media. To begin, acquaint yourself with Twitter Advertising formats , Twitter Ad Benchmarks , and browse the catalog of training videos at Twitter’s Flight School.
Thanks to the partnership, TLM alumni — who have already received some tech-related training — are allowed free access to Formation's Fellowship Program, which provides support via mock interviews and technical mentorship.
However, visual language has not garnered a similar level of attention, possibly because of the lack of large-scale training sets in this space. For math reasoning pre-training, we pick textual numerical reasoning datasets and render the input into images, which the image-to-text model needs to decode for answers.
“We are hoping Evals becomes a vehicle to share and crowdsource benchmarks, representing a maximally wide set of failure modes and difficult tasks.” ” OpenAI created Evals to develop and run benchmarks for evaluating models like GPT-4 while inspecting their performance.
The 12th edition of the Blackbaud Peer-to-Peer Benchmark Report is here! Invest in onboarding and coaching messaging streams to train your new participants every step of the way. Putting Benchmarks into Action So, what does all this mean for nonprofit P2P marketers and fundraisers? This metric is one to watch for the future.
An assessment tool can help identify strengths, challenges and gaps and help the board hold themselves accountable to reaching benchmarks and goals. Examine current goals and objectives around board diversity and create benchmarks. Invest in training. The Council on Nonprofits has samples to review.
However, most of these generative AI models are foundational models: high-capacity, unsupervised learning systems that train on vast amounts of data and take millions of dollars of processing power to do it. Active learning makes training a supervised model an iterative process. What is active learning?
Tensions rose in Silicon Valley this week after DeepSeek, a Chinese AI firm, launched its R1 model, which outperformed top US AI companies, including OpenAI, Meta, and Anthropic, in third-party benchmarks. The anxiety began with DeepSeek v3 , which left Meta’s Llama 4 trailing in benchmarks.
In the last 10 years, AI and ML models have become bigger and more sophisticated — they’re deeper, more complex, with more parameters, and trained on much more data, resulting in some of the most transformative outcomes in the history of machine learning. sub-quadratic with relation to the input sequence length).
We organize all of the trending information in your field so you don't have to. Join 12,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content