This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Source: Social Good: Charity and Technology in the Online Universe. Well, imagine my — rather our — disappointment when we discovered that simply having a Donate Now button on your website didn’t result in thousands of dollars in monthly donations. In the summer of 2000, I launched an e-advocacy portal called eActivist.org.
You’ve waited a bit, logged into your payment processor, and have been impatiently refreshing the results ever since. The great thing about email fundraising is that you get quick results and a lot of data to make sense of those results. Except, there aren’t many donations coming through.
Even many of the standard datasets we use today have been shown to have mislabeled data that can destabilize established ML benchmarks. In this blogpost, we outline dataset development bottlenecks confronting researchers and discuss the role of benchmarks and leaderboards in incentivizing researchers to address these challenges.
Today, we are excited to share more about the Universal Speech Model (USM), a critical first step towards supporting 1,000 languages. For the first step, we use BEST-RQ , which has already demonstrated state-of-the-art results on multilingual tasks and has proven to be efficient when using very large amounts of unsupervised audio data.
I was curious about what I could learn if I did an informal benchmark study of a few nonprofit Pinterest users. Universal human themes appear to spark engagement. Have you benchmarked this data against other similar types of nonprofits? First, let me offer this disclaimer. View more presentations from NTEN.
However, this is not a universalbenchmark. The result is 1.5your organization would have one and half months of capital if needed. It really does depend on the needs of your individual organization. For example, if your annual expense is $600,000, divide that amount by 12 to get $50,000.
and around the world to create award-winning videos that drive results. Their work has been featured in The New York Times, NPR, CNN and AdWeek and Doug is a guest lecturer at Stanford University on the power of storytelling for nonprofit organizations. He and his team work with nonprofits across the U.S. The Nonprofit Video Index.
But the following characteristics are universal to an approach that puts people first: Empower and educate Invest in training. Many of the data disasters I’ve seen result from well-intentioned employees trying to get a job done without the correct information about how to do it. Include benchmarks in goals and KPIs.
the end result will be a model good enough to govern a robot in the real world. Nicholas Bloom, Stanford University economist and leading expert on remote work Agriculture and manufacturing are also becoming less important as a share of global economic output over time, not just as shares of employment.
World Giving Index Charities Aid Foundation looked at three different types of charitable behavior – giving money, giving time and helping a stranger and used the results to produce the “World Giving Index.&# 2011 eNonprofit Benchmarks Study A visual version of the 2011 eNonprofit Benchmarks Study by M+R Strategic Services and NTEN.
According to the M+R Benchmarks report , fundraising mobile messages generate an average of $92 in revenue for every 1,000 messages sent. Find a mobile giving software provider that works for and with your organization to achieve the best results. Step 3: Choose a mobile giving software provider.
The paper, with coauthors from the former Facebook AI Research (now Meta AI), University College London and New York University, called RAG “a general-purpose fine-tuning recipe” because it can be used by nearly any LLM to connect with practically any external resource. I showed my supervisor and he said, ‘Whoa, take the win.
Have you downloaded the 2014 Luminate Online Benchmark Report yet? Throwing back to the 2013 Benchmark Study , we witnessed an explosion of growth of sustainer giving – a 27% increase over the previous year. This year, Rachel was thrilled to author the 2014 Luminate Online Benchmark Report. overall year-over-year. Register here!
in Applied Physics from Harvard University, an M.S. in Physics from Stanford University. These exciting proof-of-concept models perform well on benchmarked datasets in research environments, but they struggle to predict accurately when released in the real world. He holds an S.M. in Electrical Engineering and a B.S.
A: We saw urgency around three key areas in 2020: 1) work related to the pandemic—research, support of healthcare training, and delivery 2) direct support of students in need as a result of the pandemic, and 3) support for activities that involve direct service delivery to communities. compared to the previous year.
The coalition includes the Center on Philanthropy at Indiana University , GuideStar USA , the Foundation Center , the Urban Institute’s National Center for Charitable Statistics , the Association of Fundraising Professionals and Blackbaud. This approach provides more useful benchmarking information than repeated cross?sectional
Michael earned his MD and PhD degrees from Emory University, and today his research combines mathematical and epidemiological models with high-throughput phage-display–based serological laboratory investigations. Chan School of Public Health. In other words, he’s just our kind of guy. And that, he says, is not good enough.
Because we survey organizations involved in the grantseeking universe twice a year, the information contained in the survey analysis reports (which are free) is current, and catches the tide changes and zeitgeist of grantseeking as they happen. survey grants tsgrantstation GrantStation benchmarks State of Grantseeking programs'
Benchmarking and CRM Lack of solid recordkeeping and full use of its nonprofit CRM is at the very top of pain points I continue to observe in the nonprofit sector. The days should be long gone that a woman receives mail without her correct name, usually due to making assumptions based upon relationships. Let us know in the comments.
Ready to dive into how to convey messages using specific marketing channels, and ultimately, how to measure the results of your work? This 1, 3, 5 year plan will serve as your road map, illustrating your course and outlining goals and benchmarks to hit. Keep reading. Use Your E-mail Signature. everything.
As a result, despite the short-term gains from using view hierarchies, it may ultimately hamper the model performance and applicability. We introduce a unified approach to represent diverse UI tasks, the information for which can be universally represented by two core modalities: vision and language.
Smartling s new AI-powered toolkit reduces translation turnaround times while delivering accurate results for companies engaged in global commerce. The companys pricing begins at $24 per month for individual creators, with business subscriptions starting at $89 per month.
Understanding Benchmark Data. The broadest industry benchmarking data is a good place to start. The results: 15 times more new donors. Consider the results of frontline fundraisers at Notre Dame de Namur University. It provides an overarching view of the state of fundraising in recent years.
The report provides excellent recommendations on what can be done to reroute the current direction in which the fundraising profession is headed, including strengthening talent, sharing accountability, and creating achievable benchmarks. Here are some other helpful starting points: Build cohesiveness. She earned a B.A.
To explore this, we collaborated with researchers at the University of Freiburg and Nuremberg to develop Visual Language Maps (VLMaps), a map representation that directly fuses pre-trained visual-language embeddings into a 3D reconstruction of the environment. .
Adding a blood pressure monitor to smartwatches could arguably be more important for users’ cardiovascular health than the heart rate and rhythm monitors they have now, says says Ann Marie Navar, a cardiologist at the University of Texas Southwestern Medical Center. The results held for people of varying skin tones and ages.
Study up on churn rate basics to set customer and revenue benchmarks. Jain explains the differences between customer and revenue churn, shares formulas for calculating benchmarks, and answers the question: “What is a good monthly churn rate?” ” Study up on churn rate basics to set customer and revenue benchmarks.
Its latest work is a collaboration with academics from Michigan State University (MSU), with the combined team creating a method to reverse-engineer deepfakes : analyzing AI-generated imagery to reveal identifying characteristics of the machine learning model that created it. Not everybody can create their own camera, though,” he says.
I applaud this move wholeheartedly — USB-C is a more universal port and it opens up the iPad to more accessories, including some of the same dongles you might already use on your laptop. I’m not going to go down an entire benchmarking rabbit hole about the new A14 Bionic processor on the 2020 iPad Air even though I’m sorely tempted to.
Before the advent of simple survey software, which leveled the playing field, surveys were run by businesses and organizations large enough to have a statistical department or a partnership with a university. Mostly, though, it’s all about the benchmarks. All those individual responses were tough to crunch in the “old days.”
This book is the result of what we have learned teaching leadership and business acumen classes to rising and senior leaders at Fortune 500 companies for twenty years,” share authors Nathan Kracklauer and Bjorn Billhardt. But we leave them out of our book because they are neither timeless nor universal.
A year ago, Johns Hopkins University's Center for Civil Society Studies published a document titled, " The Nonprofit Technology Gap - Myth or Reality." One of the resources I have been most impressed with is the " Technology Literacy Benchmarks For Nonprofit Organizations ," created by NPower.
OK — confession time — I love data — but the data from the State of Grantseeking Survey has real, valuable results that can impact the grantseeking success of nonprofits. Here’s how: Recency: We survey grantseekers, grant writers, and those involved in the grantseeking universe twice a year (spring and fall).
A deep neural network can be thought of as a function that outputs a result based on both the input and its parameters. The Universal Transformer extends the ACT algorithm to transformers by making the computation budget dependent on the number of transformer layers used for each input example or token. Evaluation on the parity task.
Last month marked the inaugural meeting of a new benchmarking group created specifically to analyze and discuss trends in athletics giving [1]. However, participants in donorCentrics® benchmarking groups get access to data from each participating school. Do keep in mind that this analysis will share aggregate data trends only.
However, this is not a universalbenchmark. The result is 1.5—your Obligations resulting from your commitments to a donor’s purpose restrictions. It really does depend on the needs of your individual organization. For example, if your annual expense is $600,000, divide that amount by 12 to get $50,000.
We dont think the results in this post show that SHIFT is a bad method, but rather that the Bias in Bios dataset (or any other simple dataset) is not a good test bed to judge SHIFT or other similar methods. 2025 ), SAE Bench ) have already used more complex datasets and found promising results. Follow-ups of SHIFT-like methods (e.g.,
Posted by Posted by Leslie Yeh, Director, University Relations (This is Part 9 in our series of posts covering different topical areas of research at Google. We partnered with ENS , a university in France, to help fund scholarships for students to train through research. You can find other posts in the series here.)
Ryan also holds a Master''s in Business Administration from the University of Florida. They end up spending frivolously on marketing or allocate resources to free mediums like social media in an attempt to save money. He currently owns Webris , a Miami based digital marketing agency specializing in search engine marketing. Like this article?
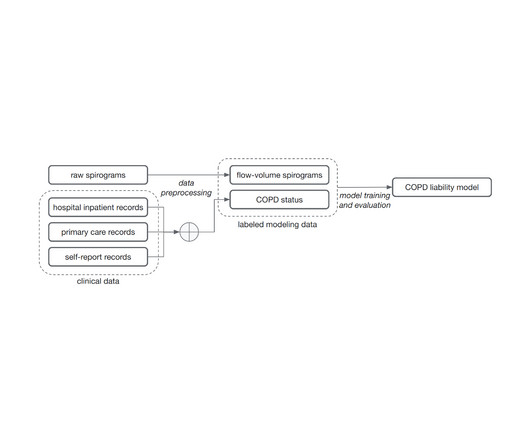
We reasoned that ML models trained to classify spirograms would be able to use the rich data present more completely and result in more accurate and comprehensive measures of lung function and disease, similar to what we have seen in other classification tasks like mammography or histology. McCaw, Cory Y. Hobbs and Michael H.
And, what if you are “firing on all cylinders&# but you’re still not seeing magical multichannel results? In this webinar, fundraising experts from Union of Concerned Scientists, Blackbaud and Care2 will analyze the most significant results of the newly released 2011 donorCentrics Internet and Multichannel Giving Benchmark Report.
The Bayer Center for Nonprofit Management at Robert Morris University has been doing biannual survey of nonprofit technology benchmarks for its regional nonprofits (Southwestern Pennsylvania) for the past ten years. The survey incorporates and expands nonprofit technology assessment/benchmarks used by practitioners in the field.
In “ Large Language Models Encode Clinical Knowledge ”, we demonstrated that learned prompt tuning can adapt a general-purpose language model to the medical domain with relatively few examples and that the resulting model can achieve 67.6% We show the MattNet results for comparison. MATH MMLU-STEM OCWCourses GSM8k Minerva 50.3%
When we can identify what those stories are and understand the kind of path our donors follow at each stage of the giving process, we can gently guide their journey, connect with them at a deeper level, build strong relationships, and improve fundraising results. FEP 2024 Quarterly Benchmark Report. 1] Quarterly Fundraising Report.
We organize all of the trending information in your field so you don't have to. Join 12,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content