
OpenAI’s o3: AI Benchmark Discrepancy Reveals Gaps in Performance Claims
TechRepublic
APRIL 22, 2025
The FrontierMath benchmark from Epoch AI tests generative models on difficult math problems. Find out how OpenAIs o3 and other AI models performed.

TechRepublic
APRIL 22, 2025
The FrontierMath benchmark from Epoch AI tests generative models on difficult math problems. Find out how OpenAIs o3 and other AI models performed.

Futurism
APRIL 21, 2025
Its o3 model scored a hallucination rate of 33 percent on the company's in-house accuracy benchmark, dubbed PersonQA. More on OpenAI: OpenAI Is Secretly Building a Social Network The post OpenAI's Hot New AI Has an Embarrassing Problem appeared first on Futurism.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

Candid
NOVEMBER 11, 2024
Benchmarks created to assess the performance of AI tools compared with humans on tasks such as image classification, visual reasoning, and English understanding show the gaps narrowing. As of May 2024, the MMMU benchmark , which evaluates responses to college-level questions, scored GPT-4o at 60%, compared with an 83% human average.

NTEN
NOVEMBER 19, 2014
Which is why we’re excited to invite organizations to participate in M+R and NTEN’s 2015 Benchmarks Study to help determine this year’s industry standards for online fundraising, advocacy, and list building. Still not clear on what Benchmarks is or why you will love being a part of it? Not a problem. We thought so.

Bloomerang
DECEMBER 2, 2024
Let’s dive into each of these points further to look at where we can run into problems and how to fix them. If for some reason you sent the email to less people than you meant to, you may have identified your problem. If your donation page is the problem, there are a few reasons why that could be.
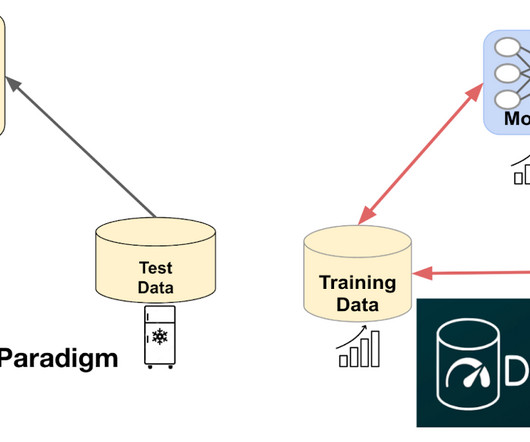
Google Research AI blog
MARCH 30, 2023
The key to both is a deeper understanding of ML data — how to engineer training datasets that produce high quality models and test datasets that deliver accurate indicators of how close we are to solving the target problem. How do we solve this problem and enable quality-driven “data acquisition”? Source: Douwe, et al.

Nonprofit Tech for Good
SEPTEMBER 11, 2012
Large national and international nonprofits have little problem reaching this benchmark, but small and some medium-size nonprofits will. I’ve observed this phenomenon on Facebook, Twitter, LinkedIn, Myspace, and Foursquare. From there on out, the larger your community gets, the faster it grows.

Expert insights. Personalized for you.






































Let's personalize your content