This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
are nowhere near achieving AGI (Artificial General Intelligence), according to a new benchmark. The Arc Prize Foundation, a nonprofit that measures AGI progress, has a new benchmark that is stumping the leading AI models. According to the ARC-AGI leaderboard , OpenAI's most advanced model o3-low scored 4 percent.
Finance professionals can create models to forecast future revenue, allowing you to anticipate growth potential across various streams. Set performance benchmarks (e.g., This model isn’t just for gyms or museums—it can work for advocacy groups, community organizations, and more. The good news?
DeepSeek released an updated version of its DeepSeek-V3 model on March 24. The new version, DeepSeek-V3-0324, has 685 billion parameters, a slight increase from the original V3 models 671 billion. The company has not yet released a system card for the updated model. 72B and Llama-3.1-405B,
For decades, its been the benchmark by which all big, fast four-doors have been judged, but after spending a week with the all-new $125,275 G99-generation M5 Touring, I cant help but wonder if that era is coming to a close. Read full article Comments
Like the prolific jazz trumpeter and composer, researchers have been generating AI models at a feverish pace, exploring new architectures and use cases. In a 2021 paper, researchers reported that foundation models are finding a wide array of uses. Earlier neural networks were narrowly tuned for specific tasks. See chart below.)
By OpenAI 's own testing, its newest reasoning models, o3 and o4 -mini, hallucinate significantly higher than o1. OpenAI's reasoning models are billed as more accurate than its non-reasoning models like GPT-4o and GPT-4.5 ” Evaluation benchmarks are tricky. GPT-4o scored 1.5 percent, GPT-4.5 UPDATE: Apr.
Contextual AI unveiled its grounded language model (GLM) today, claiming it delivers the highest factual accuracy in the industry by outperforming leading AI systems from Google, Anthropic and OpenAI on a key benchmark for truthfulness. The startup, founded by the pioneers of retrieval-augmented
Our comprehensive benchmark and online leaderboard offer a much-needed measure of how accurately LLMs ground their responses in provided source material and avoid hallucinations
The 512GB model is down to just $33, which is a record-low price and one heck of a deal. We called the sequential and random read speeds respectable in our benchmark tests. To that end, the 512GB model can fit over 200,000 photos in 4K and over 300,000 images in smaller formats.
The Mac Studio is Apples ultimate performance computer, but this years model came with a twist: Its equipped with either an M4 Max or an M3 Ultra processor. While the M3 Ultra model appears highly capable for creative pros and engineers, it starts at $4,000 and goes way up from there.
In light of this data scarcity, we position FRMT as a benchmark for few-shot translation, measuring an MT model’s ability to translate into regional varieties when given no more than 100 labeled examples of each language variety. While human evaluation is the best way to be sure of model quality, it is often slow and expensive.
The key to both is a deeper understanding of ML data — how to engineer training datasets that produce high quality models and test datasets that deliver accurate indicators of how close we are to solving the target problem. Despite the importance of data, ML research to date has been dominated by a focus on models. LAION or The Pile ).
[Image: Amtrak] Nicer seats, bigger views In an announcement released earlier this month , Amtrak revealed a first look at the specs and interiors of its Airo design, and theyre a marked improvement to the rail services existing models. In 2024, Amtrak saw a record ridership of 32.8 million passengers , up from 28 million the year before.
Even if all the code runs and the model seems to be spitting out reasonable answers, it’s possible for a model to encode fundamental data science mistakes that invalidate its results. These errors might seem small, but the effects can be disastrous when the model is used to make decisions in the real world.
Benchmarking against peers can help you refine your assumptions about what being financially sustainable could look likeor develop entirely new assumptions. In this article, well outline a three-step process adapted from our report Finding Your Funding Strategy: Benchmarking 101 , tailored to U.S.-based But where should you start?
Existing models built for these tasks relied on integrating optical character recognition (OCR) information and their coordinates into larger pipelines but the process is error prone, slow, and generalizes poorly. To solve questions in DROP, the model needs to read the paragraph, extract relevant numbers and perform numerical computation.
Kolena, a startup building tools to test, benchmark and validate the performance of AI models, today announced that it raised $15 million in a funding round led by Lobby Capital with participation from SignalFire and Bloomberg Beta.
Previously, the stunning intelligence gains that led to chatbots such ChatGPT and Claude had come from supersizing models and the data and computing power used to train them. o1 required more time to produce answers than other models, but its answers were clearly better than those of non-reasoning models.
I will begin with a discussion of language, computer vision, multi-modal models, and generative machine learning models. Language Models The progress on larger and more powerful language models has been one of the most exciting areas of machine learning (ML) research over the last decade. Let’s get started!
Posted by Danny Driess, Student Researcher, and Pete Florence, Research Scientist, Robotics at Google Recent years have seen tremendous advances across machine learning domains, from models that can explain jokes or answer visual questions in a variety of languages to those that can produce images based on text descriptions.
Alongside GPT-4 , OpenAI has open sourced a software framework to evaluate the performance of its AI models. Called Evals , OpenAI says that the tooling will allow anyone to report shortcomings in its models to help guide improvements. It’s a sort of crowdsourcing approach to model testing, OpenAI explains in a blog post.
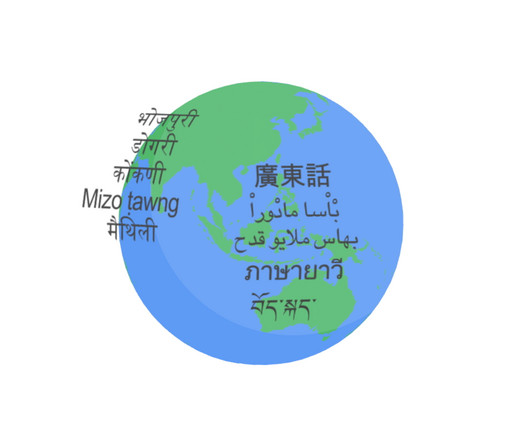
Posted by Yu Zhang, Research Scientist, and James Qin, Software Engineer, Google Research Last November, we announced the 1,000 Languages Initiative , an ambitious commitment to build a machine learning (ML) model that would support the world’s one thousand most-spoken languages, bringing greater inclusion to billions of people around the globe.
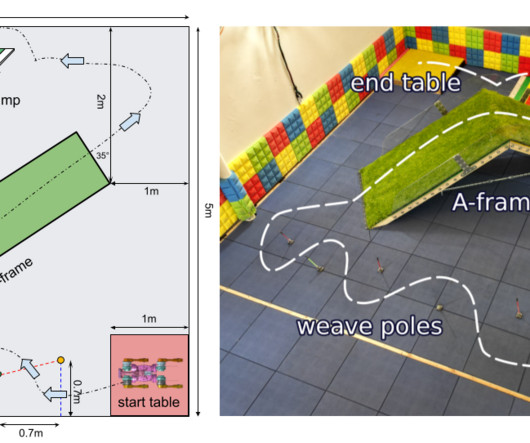
Yet, while researchers have enabled robots to hike or jump over some obstacles , there is still no generally accepted benchmark that comprehensively measures robot agility or mobility. Overview of the Barkour benchmark’s obstacle course setup, which consists of weave poles, an A-frame, a broad jump, and pause tables.
Hey data friends, it’s our favorite time of the year, the birds are singing, the flowers are blooming, you can sip your iced coffee outside and read Benchmarks ! Instead of tracking sessions , GA4 uses an event-based data model. This made the Benchmarks’ website data much more difficult to analyze. What does that mean?
” The tranche, co-led by General Catalyst and Andreessen Horowitz, is a big vote of confidence in Hippocratic’s technology, a text-generating model tuned specifically for healthcare applications. Hippocratic’s benchmark results on a range of medical exams. “The language models have to be safe,” Shah said.
The newest reasoning models from top AI companies are already essentially human-level, if not superhuman, at many programming tasks , which in turn has already led new tech startups to hire fewer workers. Fast AI progress, slow robotics progress If youve heard of OpenAI, youve heard of its language models: GPTs 1, 2, 3, 3.5,
Deci , a Tel Aviv-based startup that is building a new platform that uses AI to optimize AI models and get them ready for production, today announced that it has raised a $9.1 Using its runtime container or Edge SDK, Deci users can also then serve those models on virtually any modern platform and cloud. Image Credits: Deci. ”
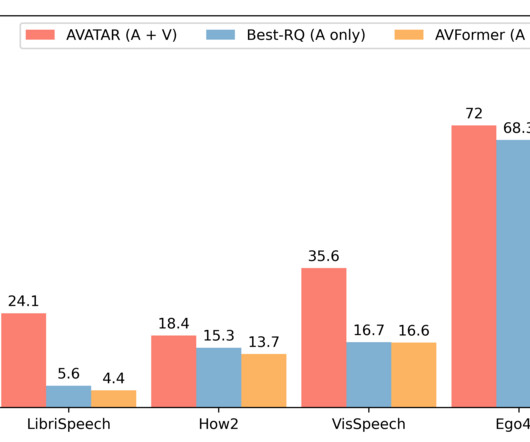
Building audiovisual datasets for training AV-ASR models, however, is challenging. In contrast, the models themselves are typically large and consist of both visual and audio encoders, and so they tend to overfit on these small datasets. LibriSpeech ). LibriSpeech ). Unconstrained audiovisual speech recognition.
A clock-for-clock (IPC) test of Intel LGA 1700 processors: we're comparing the 12th-gen, 13th-gen, and "new" 14th-gen CPU models to offer insight into their architectural improvements, if any. Read Entire Article
Bucking the Trend OpenAI launched its latest AI reasoning models, dubbed o3 and o4-mini, last week. According to the Sam Altman-led company, the new models outperform their predecessors and "excel at solving complex math, coding, and scientific challenges while demonstrating strong visual perception and analysis."
The Nürburgring racetrack has been home to decades of vehicle testing and benchmarking, and a place where automakers continue to push the limits of ICE and EV models for bragging rights. The latest feat has been accomplished by Porsche, whose Taycan Turbo S four-door posted the fastest lap time for.
I would bet that lie-proof benchmarks will be difficult and expensive to make and that the lie-proofing techniques won't easily generalize outside of coding tasks. If you RL+BP+SGD a model to avoid doing X, then the model will learn to avoid X enough that it never gets punished in training. are terribly dishonest creatures.
Posted by Jason Wei and Yi Tay, Research Scientists, Google Research, Brain Team The field of natural language processing (NLP) has been revolutionized by language models trained on large amounts of text data. Scaling up the size of language models often leads to improved performance and sample efficiency on a range of downstream NLP tasks.
DeepSeek announced the release and open-source launch of its latest AI model, DeepSeek-V3, via a WeChat post on Tuesday. Users can now interact with the V3 model on DeepSeeks official website. version, the new model’s generation speed has tripled, with a throughput of 60 tokens per second. trillion tokens. 72B and Llama-3.1-405B,
The A14 is an ideal machine for writing on the go, since you can travel with it effortlessly and it offers a whopping 18 hours and 16 minutes of battery life (according to the PCMark 10 benchmark). In the PCMark 10 battery benchmark, the Zenbook A14 lasted 18 hours and 16 minutes.
A cheap gaming laptop in this price range will definitely feel a bit flimsier than pricier models, and they'll likely skimp on RAM, storage and overall power. In general, 15-inch laptops will be the best balance of immersion and portability, while larger 17-inch models are heftier, but naturally give you more screen real estate.
By decoupling visual encoding, the model improves adaptability and performance across various tasks. It has outperformed OpenAI’s image-generation model, DALL-E 3, in benchmark tests. Consistent with previous models in the Janus series, Janus-Pro is open-source. Tencent , in Chinese]
In fact, training a single advanced AI model can generate carbon emissions comparable to the lifetime emissions of a car. And with the rapid advancement of generative AI models potentially slowing down , this provides a unique opportunity to take a breath and reimagine and mature our approach.
The leak comes from the Chinese video platform Bilibili, where someone shared a Cinebench R23 benchmark run supposedly from the unannounced 9800X3D chip. The most eye-catching specification is its 4.7GHz base clock, which would be a staggering 900MHz higher than the standard Ryzen 7 9700X's 3.8GHz base frequency. Read Entire Article
As the only cross-racial high-net-worth donor network dedicated to racial justice, DOCN provides an organizing space for and builds solidarity among these donors so they can become more impactful philanthropists, acting as a model for the broader philanthropic community to give more inclusively.
Posted by Tal Schuster, Research Scientist, Google Research Language models (LMs) are the driving force behind many recent breakthroughs in natural language processing. Models like T5 , LaMDA , GPT-3 , and PaLM have demonstrated impressive performance on various language tasks. The encoder reads the input text (e.g.,
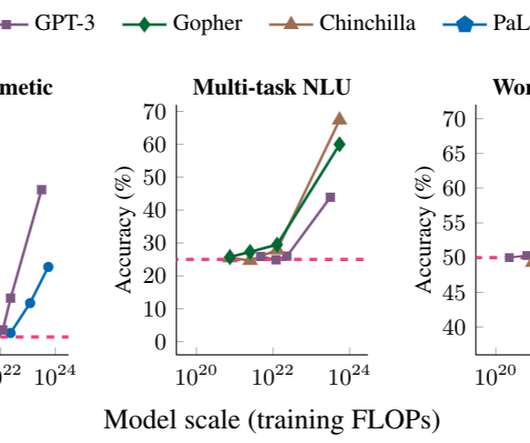
Language generation is the hottest thing in AI right now, with a class of systems known as “large language models” (or LLMs) being used for everything from improving Google’s search engine to creating text-based fantasy games. One key finding of the paper is that the progress and capabilities of large language models is still increasing.
We organize all of the trending information in your field so you don't have to. Join 12,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content