This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Find the Right Number for Your Nonprofit Operating Reserves The Nonprofit Operating Reserves Initiative (NORI) Workgroup suggests that the minimum operating reserve ratio at the lowest point during the year should be 25 percent, or about three months of the annual operating expense budget. However, this is not a universal benchmark.
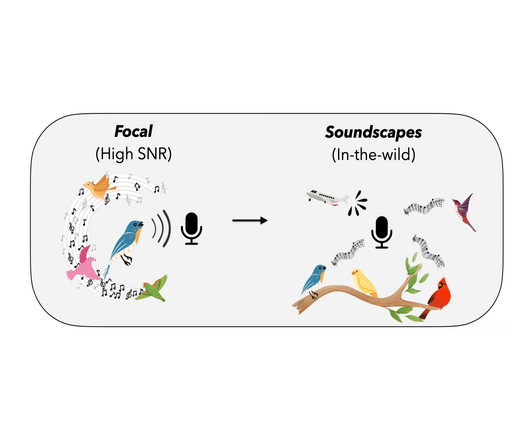
Source-free domain adaptation (SFDA) is an area of research that aims to design methods for adapting a pre-trained model (trained on a “source domain”) to a new “target domain”, using only unlabeled data from the latter. Designing adaptation methods for deep models is an important area of research.
Such real-world data challenges limit the achievable accuracy of prior methods in detecting anomalies. The challenge gets further exacerbated as the anomaly ratio gets higher for unlabeled data. The refined data, with a lower anomaly ratio, are shown to yield superior anomaly detection models. anomaly ratio.
This figure can be found by dividing Customer Lifetime Value by Customer Acquisition Cost (LTV:CAC ratio). For this method to be foolproof, you must use reliable retention data, which can be hard to come by for startups with little historical data. This, in turn, showed “fake good,” bogus LTV:CAC ratio numbers.
The Nonprofit Operating Reserves Initiative (NORI) Workgroup suggests that the minimum operating reserve ratio at the lowest point during the year should be 25 percent, or about three months of the annual operating expense budget. However, this is not a universal benchmark. How To Calculate Your Operating Reserve Ratio.
In “ RO-ViT: Region-Aware Pretraining for Open-Vocabulary Object Detection with Vision Transformers ”, presented at CVPR 2023 , we introduce a simple method to pre-train vision transformers in a region-aware manner to improve open-vocabulary detection. The position, scale, and aspect ratio of the crop is randomly sampled. mask AP r.
Compared to token-based routing and other routing methods in traditional MoE networks, EC demonstrates very strong training efficiency and downstream task scores. Our method resonates with one of the vision for Pathways , which is to enable heterogeneous mixture-of-experts via Pathways MPMD (multi program, multi data) support.
LRB , LHD , storage applications ), it remains a challenge to outperform robust heuristics in a way that can generalize reliably beyond benchmarks to production settings, while maintaining competitive compute and memory overheads. Aggregate worldwide YouTube byte miss ratio before and after rollout (vertical dashed line).
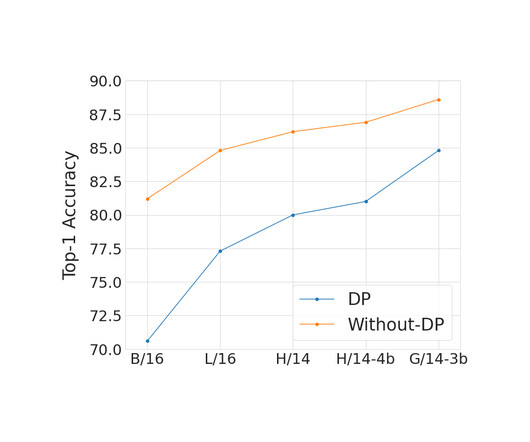
The most popular method for DP training in deep learning is differentially private stochastic gradient descent (DP-SGD). Given these challenges, there has recently been much interest in developing methods that enable efficient DP training. We further explore using DP Newton’s method to solve logistic regression.
Recent SAE benchmarking efforts like SAEBench provide more support for this view, as on most of the SAEBench downstream tasks, performance does not consistently improve with newer SAE architectures. We also believe that on some datasets, the spurious feature baseline detection method we came up with wouldnt work (e.g.
The clear majority of giving is made through one of three methods: direct mail, online and special events. Benchmarking Major Gifts. Released in September, the 2017 Major Gifts Fundraising Benchmark Study (MGFBS), asked more than 600 organizations in the U.S. and “What methods work best to raise these gifts?”
It successfully matches hand-tuned performance on popular models such as Transformers, but is also capable of successfully scaling up other models, such as convolutional networks and mixture-of-experts models that often cause existing automated methods to struggle. Alpa overview. while reducing the simulation time by 93%–99%.
Self-assessment is not a substitute for a real audit but a means of determining current status against the enterprise preset learning and development benchmarks. Though feedback also serves as a quasi-audit, it is restrictive in scope. The analysis and audit findings will serve as a wake-up call to set the L&D issues in order.
Self-assessment is not a substitute for a real audit but a means of determining current status against the enterprise preset learning and development benchmarks. Though feedback also serves as a quasi-audit, it is restrictive in scope. The analysis and audit findings will serve as a wake-up call to set the L&D issues in order.
Self-assessment is not a substitute for a real audit but a means of determining current status against the enterprise preset learning and development benchmarks. Though feedback also serves as a quasi-audit, it is restrictive in scope. The analysis and audit findings will serve as a wake-up call to set the L&D issues in order.
inch version, Mini LED lets blacks be truly black, offers a high contrast ratio, and can also get very bright. Liquid Retina,” as far as Apple has ever told us, refers to the Apple-specific method of making round corners on an LCD.). Apple is calling this screen the “Liquid Retina XDR display.” The funny thing about the 12.9-inch
We’re excited to share all the work from SAIL that’s being presented at the main conference , at the Datasets and Benchmarks track and the various workshops , and you’ll find links to papers, videos and blogs below.
Before launching a campaign, organizations should carefully evaluate their fundraising methods and messaging to ensure they align with their goals and available resources. Compared to traditional methods, itsconvenience, broad reach, and lower costs have made it a preferred way for donors to contribute.
Lenovo says it’s been tested against 12 “military-grade” certification methods. It does have the cramped 16:9 aspect ratio, something I’ve been glad to see other ThinkPads shifting away from this year. I ended up running a couple benchmarks to see how this system stacks up to competition. pounds and 0.61 inches thick.
The efficiency ratio , also known as the revenue to cost ratio. This formula a great way to benchmark goals and objectives while providing an accurate way to track results. The best part of the efficiency ratio is that it doesn’t involve any complex math. How else is leadership suppose to react to that? Congratulations!
Though we have not yet incorporated this feedback loop into Chirpy Cardinal, our method demonstrates one viable way to implement a semi-supervised online learning method to continuously improve a neural generative dialogue system. The figure above shows the differences of strategies on the Re-offense ratio.
The display isn’t necessarily hurt by it being a 16:9 aspect ratio since it’s so big, but I’d love to see Razer move to the taller 16:10 aspect ratio, as it does in the smaller Razer Book. With those same maxed-out settings and DLSS in “auto” mode, the benchmark ran at an average of 67 frames per second.
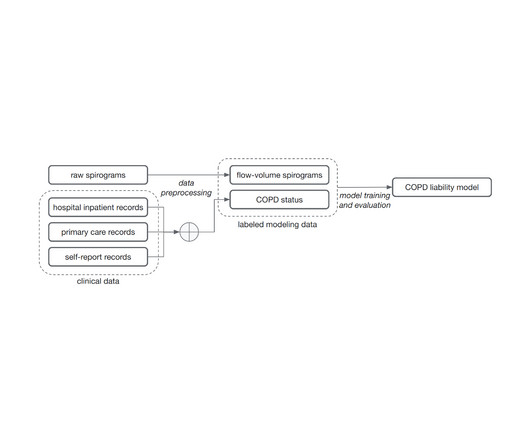
In “ Inference of chronic obstructive pulmonary disease with deep learning on raw spirograms identifies new genetic loci and improves risk models ”, published in Nature Genetics , we’re excited to highlight a method for training accurate ML models for genetic discovery of diseases, even when using noisy and unreliable labels.
Another reason to start with Paid search: According to the M&R 2022 Benchmark Study , return on ad spend was highest for search ads ($3.72). Monitor the ad performance to gain benchmarks against which to measure future performance. This is a good benchmark against which to measure the performance of your donation page.
We organize all of the trending information in your field so you don't have to. Join 12,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























Let's personalize your content