This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
are nowhere near achieving AGI (Artificial General Intelligence), according to a new benchmark. The Arc Prize Foundation, a nonprofit that measures AGI progress, has a new benchmark that is stumping the leading AI models. To get a sense of AI models' current limitations, you can take the ARC-AGI test for yourself.
Im intrigued by that model based on benchmarks I saw elsewhere, of course. All M4 Max models start with a decent 36GB of unified memory, though my test unit came with the maximum 128GB in a $3,699 configuration. It falls just below the Mac Studio with M2 Ultra on the multicore Geekbench 6 test. 265 files on the fly.
xAI is promoting Grok 3 as the best model on the market, claiming it surpassed competitors from OpenAI , Google , Anthropic, and DeepSeek on key benchmarks. Grok 3 did perform well under the codename "chocolate" in Chatbot Arena, which pits chatbots against each other in blind performance tests. Flash Thinking." are cooked.
IGN got a chance to benchmark AMD's upcoming Radeon RX 9070 GPU in Call of Duty Black Ops 6 by discreetly running the test on a system equipped with the GPU at the CES show floor. Although the results appear similar to Nvidia's GeForce RTX 4080 Super, like-for-like comparisons in. Read Entire Article
Intel is hitting back at Apple’s new M1 MacBooks with some benchmarks of its own, after early reviews showed impressive performance and battery life from Apple’s ARM-based chips. In benchmarks published by Tom’s Hardware , Intel compares its 11th Gen Core i7 processor with the M1 CPU found in the latest MacBook Pro. Image: Intel.
The 16th annual Blackbaud Luminate Online Benchmark Report is here! It’s also a valuable tool to help nonprofits evaluate their results by giving them a comparison point for their performance against organizations of similar sizes and issue areas. We look forward to this report every year.
The A14 is an ideal machine for writing on the go, since you can travel with it effortlessly and it offers a whopping 18 hours and 16 minutes of battery life (according to the PCMark 10 benchmark). But in comparison to the Surface Pro and Laptop, it's like driving an entry-level car instead of a true luxury offering.
The world of CPUs has been notoriously busy in recent years and our buying guide is keeping up with the latest releases to complement our day-one reviews and benchmarkcomparisons. After all the extensive testing you're familiar with, TechSpot's CPU buying guide means to narrow things down in a few.
The charts, in Apple’s recent fashion, were maddeningly labeled with “relative performance” on the Y-axis, and Apple doesn’t tell us what specific tests it runs to arrive at whatever numbers it uses to then calculate “relative performance.”. The Verge’s M1 Ultra Geekbench 5 Compute benchmark. Image: The Verge. At least, not yet.
Over the holidays, I used DataRobot to reproduce a few machine learning benchmarks. Their code attempted to create a validation test set based on a prediction point of November 1, 2011. The performance of the model is then analyzed on a test set, which is located after the prediction point. Do you see it?
For the comparison, we only use the 18 languages that Whisper can successfully decode with lower than 40% WER. USM supports all 73 languages in the YouTube Captions' Test Set and outperforms Whisper on the languages it can support with lower than 40% WER. Our model has, on average, a 32.7% relative lower WER with in-domain data.
After co-founder and CEO Munjal Shah sold his previous company, Like.com, a shopping comparison site, to Google in 2010, he spent the better part of the next decade building Hippocratic. Hippocratic’s benchmark results on a range of medical exams. ” AI in healthcare, historically, has been met with mixed success.
I’ve been testing MSI’s MAG Z690 Carbon Wi-Fi, which has five M.2 The Verge doesn’t review processors in the traditional sense, so we don’t own dedicated hardware testing rigs or multiple CPUs and systems to offer all of the benchmarks and comparisons you’d typically find in CPU reviews. I also tested a variety of PCIe 4.0
The Best Time for Nonprofit Emails For our latest research report, The Nonprofit Email Report: Data-Backed Insights for Better Engagement , we analyzed 37,472 email campaigns (that’s 157,048,634 individual emails) and then broke down important benchmarks by list size. Compare engagement metrics and test until you see improvements.
We ran a $12K experiment to test the cost and performance of Serverless warehouses and dbt concurrent threads, and obtained unexpected results. In this blog we take a technical deep dive into the cost and performance of their serverless SQL warehouse product by utilizing the industry standard TPC-DI benchmark. AWS EC2 bill).
We created the Prompted Speech dataset by splitting the Euphonia corpus into train, validation and test portions, while ensuring that each split spanned a range of speech impairment severity and underlying etiology and that no speakers or phrases appeared in multiple splits. Model word error rates (WER) for each test set (lower is better).
We evaluate our algorithm on the standard benchmark NATS-Bench using 100 NAS runs, and we compare against other NAS algorithms, previously described in the NATS-Bench paper: random search, regularized evolution , and proximal policy optimization. Comparison on models under different #MAdds. See the paper for details.
Storytelling Tips: Create Benchmarks for Comparison One final piece of advice I’ll share about measuring the ROI on stories is to have a benchmark for comparison. I say this because getting a pure A/B test can be a challenge. This will give you a starting point for comparison and assessment of your strategy.
I’ve been testing a system with a Radeon RX 6800M for the past few days. My test system includes an eight-core AMD Ryzen 9 5900HX and 16GB of RAM. In the meantime, here are my benchmark results to give you an idea of the frame rates you can expect from this chip on a few different games. to $1,699.99
There’s also a hint that its new A15 Bionic processor might be downclocked in comparison to the version that appears in the iPhone 13 line ( via MacRumors ). The GeekBench benchmarks MacRumors cites points to the Mini’s performance coming in at 2.9 The same might be said for the iPad Mini’s processor. GHz , a bit slower than the 3.2
Microsoft Flight Simulator is a notorious beast of a game and is quickly becoming the new Crysis test for PCs. This piqued my curiosity, so I’ve been testing the i9-11900K over the past few days to see what it can offer for Microsoft Flight Simulator specifically. I was wrong. Intel’s Core i9-11900K processor.
Google has removed 1% of cookies to test their cookie alternative, and are planning to fully remove support for them in Q1 2025. Cookieless reporting: what’s your approach, and what are your benchmarks? The point is, a fractured landscape makes comparisons across vendors harder.
To me, you don’t include a “pro” model on day one unless you are very confident in the benchmarks and performance. Apple is surely going to tout some impressive benchmarks for these Macs. Live demos are of course heavily tested and scripted, but I’ve seen enough of them go sideways to know that they’re also usually real.
REVEAL achieves higher accuracy in comparison to previous works including ViLBERT , LXMERT , ClipCap , KRISP and GPV-2. We also evaluate REVEAL on the image captioning benchmarks using MSCOCO and NoCaps dataset. REVEAL achieves a higher score in comparison to Flamingo , VinVL , SimVLM and CoCa.
Published on March 12, 2025 5:56 PM GMT Summary The Stages-Oversight benchmark from the Situational Awareness Dataset tests whether large language models (LLMs) can distinguish between evaluation prompts (such as benchmark questions) and deployment prompts (real-world user inputs).
Knowing what work you need done and the quality of work you’d like to receive and set benchmarks to measure outcomes. Sites like uTest and Topcoder help you work through work like website or application testing and provide ratings and controls to help you manage more technical processes with vetted programmers and developers.
We also use the median for our comparisons, so that one outlier doesn’t skew the whole set. One M+R client has run a test texting half of their email list three times in addition to their regular 10 EOY email appeals. And boy, were there some outliers this year. On to the goods! . Giving Tuesday: December Edition.
To provide insight into the relative strengths and weaknesses of different models, EditBench prompts are designed to test fine-grained details along three categories: (1) attributes (e.g., For text-image alignment, Imagen Editor is preferred in all comparisons. material, color, shape, size, count); (2) object types (e.g.,
Then Google and Benchmark pumped $258 million more into it this past August. But the testing, refining and bug squashing would remain the same. In comparison to creating effective and data-driven distribution funnels to get your app out to millions, software is cheap. times that amount in total costs.
One challenge in this process is how we make sense of the vast amount of clinical measurements — the UK Biobank has many petabytes of imaging, metabolic tests, and medical records spanning 500,000 individuals. We trained ML models to predict whether an individual has COPD using the full spirograms as inputs.
Currently, as far as the multi-party test results are concerned, the peak network speed of the Mate 60 Pro meets 5G network speed standards. Many Chinese tech bloggers have already tested the new device firsthand, confirming that its internet speed can reach up to 5,00 Mbps , similar to the speed of the iPhone 14 Pro.
It is equipped with an Intel Core i7-10870H processor, which on paper is a slight step down compared to the Core i7-10875H in the previous model I tested, but I didn’t notice a difference in performance. I’ve been testing the flagship configuration of the new GS66 Stealth for a week. Of course, that differed depending on the game.
So here we are with the first Alder Lake laptop I’ve been able to test. The GE76 Raider model I tested is priced at — and I am not making this up — $3,999. The GE76 Raider held its own in our Adobe Premiere Pro test, which tasks devices with exporting a 5-minute, 33-second 4K video. That’s a rarity when I test laptops.
I’ve spent the past week testing out the RTX 3070 at both 1440p and 4K ahead of its October 29th debut, and it’s fair to say this card will give you a lot of headroom for games coming in 2021 and beyond so long as you’re playing at 1440p or below. 1440p testing. I’ve also been testing 4K performance, which you can find below.
inches) and slightly slimmer, the Nvidia card is also a bit quieter under load — both in terms of the RX 6800 having a somewhat louder hum and audibly ramping its fan up and down a tad more often in the middle of a benchmark. Yes, the RX 6800’s exhaust resembles a certain muscle car. The RX 6800’s backplate, with exposed Phillips head screws.
I’m not going to go down an entire benchmarking rabbit hole about the new A14 Bionic processor on the 2020 iPad Air even though I’m sorely tempted to. So I fully expect there to be a wash of articles detailing the many benchmark results you can get on this chip and what they could portend for the future. iPad Air specs and processor.
I tested a more expensive 2-in-1 model listed at $2,926.75 For a more modern comparison, both the XPS 13 and the XPS 13 2-in-1 (both with a Core i7-1165G7) took over 10 minutes to complete the task. It’s interesting that the Latitude is beating these consumer laptops in Premiere Pro tasks, but losing in other graphic benchmarks.
It strangely didn’t do as well as its predecessor on our Premiere Pro test, which involves exporting a five-minute, 33-second 4K video; this year’s Aero took four minutes and five seconds to complete the task, where its predecessor (the Aero 15 OLED XB) took just over two and a half — Gigabyte says this may have to do with Nvidia’s drivers.
The model I tested bumps the storage up to 512GB and the memory up to 16GB. That advantage bore out in our benchmarktesting. This iMac model achieved a higher score on the Geekbench 5 single-core benchmark than any Mac we’ve ever seen before — even the iMac Pro. In this comparison, multi-core results are more important.
We’re doing this to avoid any bias in performance testing — using the same CSV lets Spark cache and optimize things in the background. Now that we’ve got a handle on Parquet, let’s put it to the test. Let’s dive into testing ORC’s writing performance. Next, we’ll test how ORC handles an aggregation query. schema(schema).load("s3a://mybucket/ten_million_parquet.csv")
When changing settings like this, it is best to make the changes on a test profile. If your main profile has any other filters applied to it, copy those to your test profile as well. After a couple of days, look to make sure your test profile has removed visits. Leave both profiles up. Do not delete your original profile.
You’ll see that difference reflected in our benchmark results later on. To see how our test system stacks up, I ran various synthetic benchmarks as well as a 5-minute, 33-second 4K video export in Premiere Pro. But the more interesting comparison is to the M1 machines. It costs $1,699.
inch screen is large enough to invite you to open multiple windows for side-by-side comparisons or just better multitasking. The company didn’t have pricing information for the spec tier I was able to test, but the top-tier model with 16GB of RAM and 256GB of storage will sell for $770.
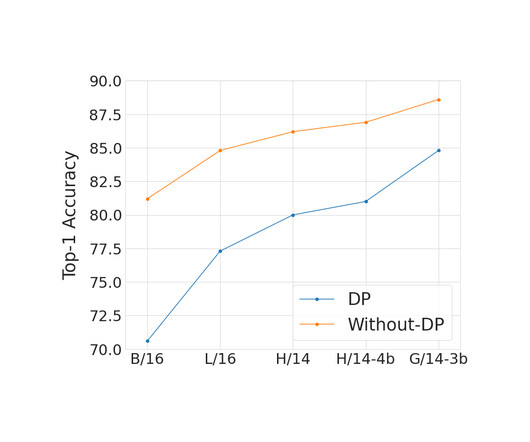
The ImageNet classification benchmark is an effective test bed for this goal because 1) it is a challenging task even in the non-private setting, that requires sufficiently large models to successfully classify large numbers of varied images and 2) it is a public, open-source dataset, which other researchers can access and use for collaboration.
We organize all of the trending information in your field so you don't have to. Join 12,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























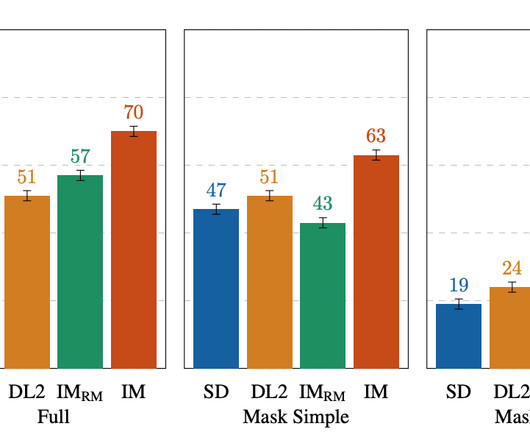

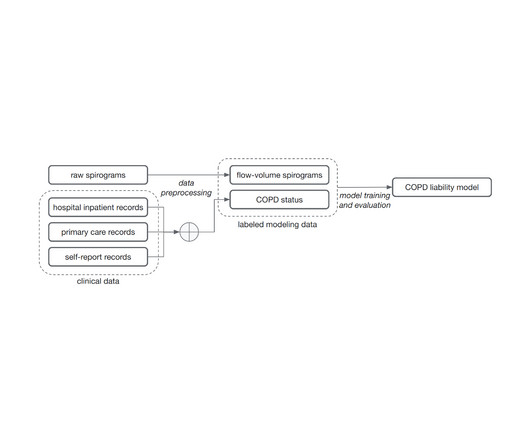

















Let's personalize your content