This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
IGN got a chance to benchmark AMD's upcoming Radeon RX 9070 GPU in Call of Duty Black Ops 6 by discreetly running the test on a system equipped with the GPU at the CES show floor. Although the results appear similar to Nvidia's GeForce RTX 4080 Super, like-for-like comparisons in. Read Entire Article
The 16th annual Blackbaud Luminate Online Benchmark Report is here! It’s also a valuable tool to help nonprofits evaluate their results by giving them a comparison point for their performance against organizations of similar sizes and issue areas. We look forward to this report every year.
While techniques and equipment are important, it is also useful to have some benchmarks and best practices in the nonprofit sector to inform your strategy and measurement plan. Tactics will only go so far. Currently, there are no significant benchmarks around video for nonprofits. Why should you participate?
In both early benchmarks and head-to-head comparisons for compiling code , Apple’s M1 chip appears to hold its own against even Intel’s most powerful Core i9 chip for laptops. Keep in mind this comparison is deeply unfair: my 16-inch MacBook Pro was literally maxed out just a year ago – 8 cores, 64GB RAM, and much more, costing $6000.
Even if all the code runs and the model seems to be spitting out reasonable answers, it’s possible for a model to encode fundamental data science mistakes that invalidate its results. Over the holidays, I used DataRobot to reproduce a few machine learning benchmarks. For comparison, a random forest model achieves 2.38
For the first step, we use BEST-RQ , which has already demonstrated state-of-the-art results on multilingual tasks and has proven to be efficient when using very large amounts of unsupervised audio data. Key results Performance across multiple languages on YouTube Captions Our encoder incorporates 300+ languages through pre-training.
Static workload benchmark is insufficient. The standard way to evaluate ANN indexes is to use a static workload benchmark , which consists of a fixed dataset and a fixed query set. A static workload benchmark. This evaluation approach was popularized by the ann-benchmarks project which started 5 years ago. MIT Licence.
World Giving Index Charities Aid Foundation looked at three different types of charitable behavior – giving money, giving time and helping a stranger and used the results to produce the “World Giving Index.&# 2011 eNonprofit Benchmarks Study A visual version of the 2011 eNonprofit Benchmarks Study by M+R Strategic Services and NTEN.
Results on awareness so far are favourable when you consider there was no cost involved and little resource investment too. We’d like to try to benchmark it against other disruptive pinterest campaigns but we’re not sure there is a good comparison case study. Please tell us if you know of one! What does it look like?
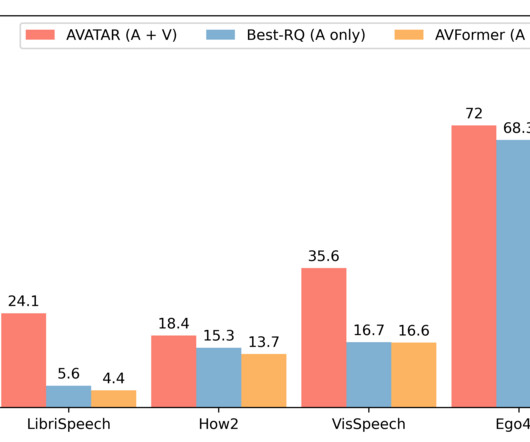
The resulting AVFormer model achieves state-of-the-art zero-shot performance on three different AV-ASR benchmarks (How2, VisSpeech and Ego4D ), while also crucially preserving decent performance on traditional audio-only speech recognition benchmarks (i.e., Results are reported as WER % (lower is better). LibriSpeech ).
1/4th of Annual Nonprofit Revenue is Raised in December Source: M+R Benchmarks According to the 2023 M+R Benchmarks Report , December giving accounts for roughly one fourth (26%) of annual nonprofit revenue. Slash 26% out of any organization’s budget and the results will be dire! Get the guide 2.
An important algorithmic piece of cache management is the decision policy used for dynamically updating the set of items being stored, which has been extensively optimized over several decades, resulting in several efficient and robust heuristics. The labels for these pending comparisons can only be resolved at a random future time.
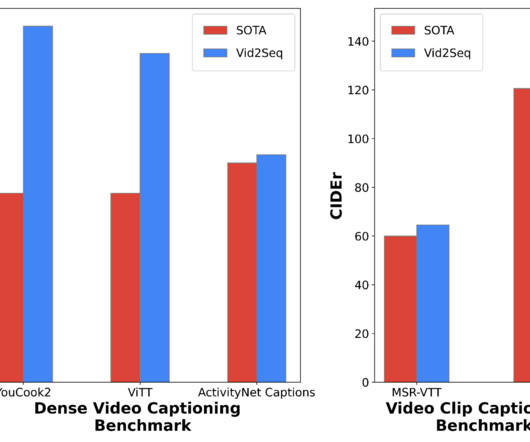
The resulting Vid2Seq model pre-trained on millions of narrated videos improves the state of the art on a variety of dense video captioning benchmarks including YouCook2 , ViTT and ActivityNet Captions. Given visual inputs, the resulting Vid2Seq model can both take as input and generate sequences of text and time tokens.
These models achieve state-of-the-art results on downstream tasks, such as image captioning, visual question answering and open vocabulary recognition. Each knowledge item is processed through a multi-modal visual-language encoder, resulting in a sequence of image and text tokens. Visual question answering results on A-OKVQA.
After co-founder and CEO Munjal Shah sold his previous company, Like.com, a shopping comparison site, to Google in 2010, he spent the better part of the next decade building Hippocratic. Hippocratic’s benchmarkresults on a range of medical exams. ” AI in healthcare, historically, has been met with mixed success.
Particularly for peer-to-peer (P2P) fundraising, mobile capabilities have become crucial in meeting donors where they are, providing a simple, fun donor experience that results in higher turnout, increased revenue, and better year-over-year retention of event participants, donors, and P2P fundraisers. That means more donors and more dollars.
We have four options for the first layer, which results in four burger candidates. Experimental results When comparing NAS algorithms, we evaluate the following metrics: Quality : What is the most accurate model that the algorithm can find? Comparison on models under different #MAdds. See the paper for details.
You can download the complete report here , and don''t forget the companion online benchmarking tool , where you can compare some of your organization''s data against your peers in our research. So, how did these various question formats impact responses/results?
You could do something very similar for a donor journey to making a donation where you would measure each of the steps in the process to see what kind of results that story is helping to drive. This is not like running a subject line test in email where we can get a clear, reliable result.
The survey results, which will be published in late April, spotlight recent developments in funding so that organizations can be more strategic in their grantseeking and serve as benchmarks for your organization to compare your own grantseeking efforts with those of your colleagues.
The results I’ve seen so far are a mixed bag, and while the RX 6800M doesn’t decisively outperform Nvidia’s top RTX chips, it’s doing a better job than I’d expect at the price range we’ve been given. In the meantime, here are my benchmarkresults to give you an idea of the frame rates you can expect from this chip on a few different games.
Comparison of four prompting methods, (a) Standard, (b) Chain of thought (CoT, Reason Only), (c) Act-only, and (d) ReAct, solving a HotpotQA question. The approach with the best results is a combination of ReAct and CoT that uses both internal knowledge and externally obtained information during reasoning. Reason-only (CoT) 29.4
The Verge doesn’t review processors in the traditional sense, so we don’t own dedicated hardware testing rigs or multiple CPUs and systems to offer all of the benchmarks and comparisons you’d typically find in CPU reviews. A benchmark for 3DMark Time Spy CPU also dipped slightly on Windows 11. Spoiler: it’s not.
If you are considering incorporating crowdsourcing principles or processes into your workflow, you should also thinking about how you’ll measure the results of your crowdsourcing efforts. In order to know how to measure crowdsourcing results, you first need to understand what kind of crowdsourcing you’re implementing. Measuring Work.
The company’s full results and earnings call failed to stanch the bleeding. Sadly, we don’t have Q4 data from Klarna to dredge up in comparison; the company most recently shared its Q3 data. million for the current quarter, so the company’s guidance is a miss by that benchmark.
The Best Time for Nonprofit Emails For our latest research report, The Nonprofit Email Report: Data-Backed Insights for Better Engagement , we analyzed 37,472 email campaigns (that’s 157,048,634 individual emails) and then broke down important benchmarks by list size. There’s not one best time to send a fundraising email.
Participate when the analysis and reporting contain benchmarks that allow you to compare your own organization’s performance with that of your colleagues. Mostly, though, it’s all about the benchmarks. What is your success rate in comparison with others in your mission focus/sector?
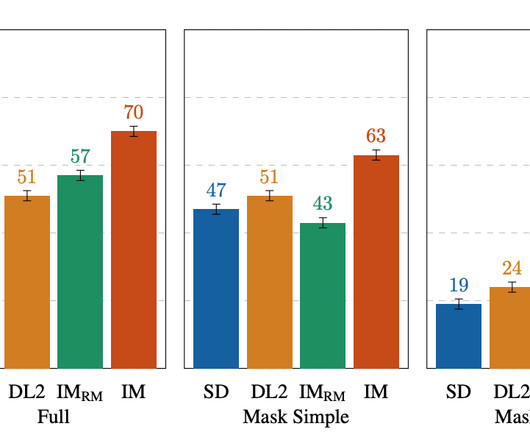
We observe that high guidance weights combined with oscillating guidance result in the best trade-off between sample fidelity and text-image alignment. Note that due to different evaluation designs, Full vs. Mask-only prompts, results are less directly comparable. For text-image alignment, Imagen Editor is preferred in all comparisons.
I’m not going to go down an entire benchmarking rabbit hole about the new A14 Bionic processor on the 2020 iPad Air even though I’m sorely tempted to. So I fully expect there to be a wash of articles detailing the many benchmarkresults you can get on this chip and what they could portend for the future.
Motivated by this, and the results from scaling LLMs, we decided to undertake the next step in the journey of scaling the Vision Transformer. As a result of its modified architecture, efficient sharding recipe, and bespoke implementation, it was able to be trained on Cloud TPUs with a high hardware utilization 1.
However, comparison is inevitable, and Chinese companies focusing on AI products have always benchmarked their products against OpenAI’s models. Such comparisons have often drawn scorn on Chinese social media, with Baidu itself often suffering in comparison to ChatGPTs innovative progress.
OK — confession time — I love data — but the data from the State of Grantseeking Survey has real, valuable results that can impact the grantseeking success of nonprofits. I’m really looking forward to digging into the survey results filtered through the lens of "ruralness," organization age, etc.
This is the number you can use to compare the relative robustness of your messaging program with the results reported by the " eNonprofit Benchmarks Study " (or Convio's " Online Nonprofit Benchmarks Study " or MailChimp's " Email Marketing Benchmarks by Industry ", or.).
This post summarizes the results and a few insights about social media fundraising and network strategies as a way to share back what I learned and to help bring some closure. Set A Realistic Goal Based On Benchmarking. I used simple measurement tools to collect data and further analyzed it in Excel spreadsheets.
Performance comparison between the PaLM 540B parameter model and the prior state-of-the-art (SOTA) on 58 tasks from the Big-bench suite. For example, PaLI achieves state-of-the-art results on the CrossModal-3600 benchmark , a diverse test of multilingual, multi-modal capabilities with an average CIDEr score of 53.4
We ran a $12K experiment to test the cost and performance of Serverless warehouses and dbt concurrent threads, and obtained unexpected results. In this blog we take a technical deep dive into the cost and performance of their serverless SQL warehouse product by utilizing the industry standard TPC-DI benchmark. AWS EC2 bill).
Survey participants will form a panel over time, allowing for trend comparisons among the same organizations. This approach provides more useful benchmarking information than repeated cross?sectional sectional studies.
Currently, as far as the multi-party test results are concerned, the peak network speed of the Mate 60 Pro meets 5G network speed standards. The software benchmark platform AnTuTu identified the Huawei Mate 60 Pro processor as the Kirin 9000s, Huaweis self-developed chipset. The highest clock speed it can achieve is 2.62GHz.
To me, you don’t include a “pro” model on day one unless you are very confident in the benchmarks and performance. Apple is surely going to tout some impressive benchmarks for these Macs. Better to stick with just the mid-range model if you’re not sure. After all, the only Windows Arm-based laptops we’ve seen recently are in that zone.
The Verge doesn’t typically review processors, so we don’t own dedicated hardware testing rigs or multiple CPUs and systems to offer all of the benchmarks and comparisons you’d typically find in CPU reviews. Averages during a particular benchmark don’t always tell the whole story, though. Intel’s Core i9-11900K processor.
To improve a model for this use case, we created the Real Conversation test set to benchmark performance. Results To evaluate the adapted USM, we compared it to older ASR models using the two test sets described above. We have previously shown that this approach works very well to adapt ASR models to disordered speech.
Published on March 12, 2025 5:56 PM GMT Summary The Stages-Oversight benchmark from the Situational Awareness Dataset tests whether large language models (LLMs) can distinguish between evaluation prompts (such as benchmark questions) and deployment prompts (real-world user inputs).
My principled quibbles aside, those are some of the best gaming results you’re going to see from a laptop this year. And in fairness, if you’re paying four grand for a gaming laptop, you’d better be getting the best gaming results of the year. These are 4K chips, and I’m not just referring to the price of this unit.
The best expert in hindsight (and hence the benchmark to compare against) is the middle one, with total reward 21. Our algorithm applies the UCB scores on pairs of arms , mainly in an effort to utilize the available pairwise comparison model that can designate the better of two arms. An instance of the experts problem.
We organize all of the trending information in your field so you don't have to. Join 12,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content