This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
are nowhere near achieving AGI (Artificial General Intelligence), according to a new benchmark. The Arc Prize Foundation, a nonprofit that measures AGI progress, has a new benchmark that is stumping the leading AI models. According to the ARC-AGI leaderboard , OpenAI's most advanced model o3-low scored 4 percent.
The Mac Studio is Apples ultimate performance computer, but this years model came with a twist: Its equipped with either an M4 Max or an M3 Ultra processor. While the M3 Ultra model appears highly capable for creative pros and engineers, it starts at $4,000 and goes way up from there. It took me one minute and 51 seconds to output a 3.5
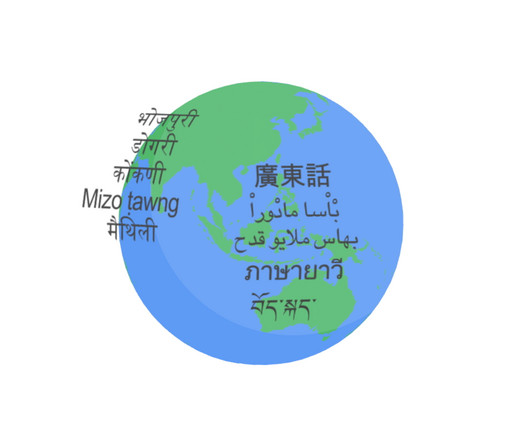
Posted by Yu Zhang, Research Scientist, and James Qin, Software Engineer, Google Research Last November, we announced the 1,000 Languages Initiative , an ambitious commitment to build a machine learning (ML) model that would support the world’s one thousand most-spoken languages, bringing greater inclusion to billions of people around the globe.
Hey data friends, it’s our favorite time of the year, the birds are singing, the flowers are blooming, you can sip your iced coffee outside and read Benchmarks ! Instead of tracking sessions , GA4 uses an event-based data model. This made the Benchmarks’ website data much more difficult to analyze. What does that mean?
Even if all the code runs and the model seems to be spitting out reasonable answers, it’s possible for a model to encode fundamental data science mistakes that invalidate its results. These errors might seem small, but the effects can be disastrous when the model is used to make decisions in the real world.
The A14 is an ideal machine for writing on the go, since you can travel with it effortlessly and it offers a whopping 18 hours and 16 minutes of battery life (according to the PCMark 10 benchmark). But in comparison to the Surface Pro and Laptop, it's like driving an entry-level car instead of a true luxury offering.
” The tranche, co-led by General Catalyst and Andreessen Horowitz, is a big vote of confidence in Hippocratic’s technology, a text-generating model tuned specifically for healthcare applications. Hippocratic’s benchmark results on a range of medical exams. “The language models have to be safe,” Shah said.
I will begin with a discussion of language, computer vision, multi-modal models, and generative machine learning models. Language Models The progress on larger and more powerful language models has been one of the most exciting areas of machine learning (ML) research over the last decade. Let’s get started!
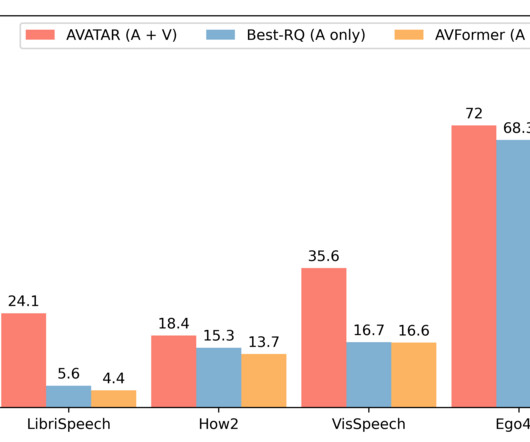
Building audiovisual datasets for training AV-ASR models, however, is challenging. In contrast, the models themselves are typically large and consist of both visual and audio encoders, and so they tend to overfit on these small datasets. LibriSpeech ). LibriSpeech ). Unconstrained audiovisual speech recognition.
Posted by Shunyu Yao, Student Researcher, and Yuan Cao, Research Scientist, Google Research, Brain Team Recent advances have expanded the applicability of language models (LM) to downstream tasks. On the other hand, recent work uses pre-trained language models for planning and acting in various interactive environments (e.g.,
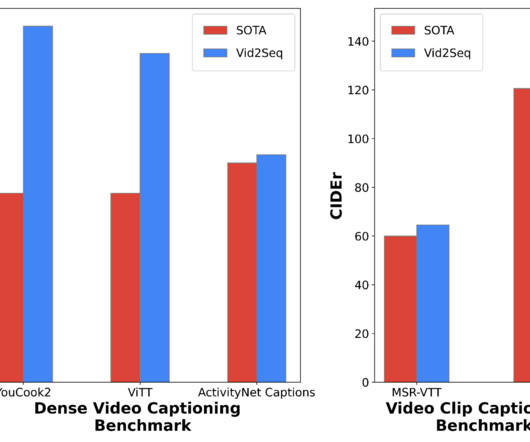
Current dense video captioning approaches, however, have several limitations — for example, they often contain highly specialized task-specific components, which make it challenging to integrate them into powerful foundation models. The architecture is initialized with a powerful visual backbone and a strong language model.
But deliver Apple did, with computers powered by a new M1 processor that aren’t just close to their previous Intel counterparts, but crush them in nearly every respect — and not just the base model Intel chips that the M1 purports to replace, either. Paul Hudson (@twostraws) November 17, 2020.
This increase in accuracy is important to make AI applications good enough for production , but there has been an explosion in the size of these models. It is safe to say that the accuracy hasn’t been linearly increasing with the size of the model. They define it as “buying” stronger results by just throwing more compute at the model.
Static workload benchmark is insufficient. The standard way to evaluate ANN indexes is to use a static workload benchmark , which consists of a fixed dataset and a fixed query set. A static workload benchmark. This evaluation approach was popularized by the ann-benchmarks project which started 5 years ago. MIT Licence.
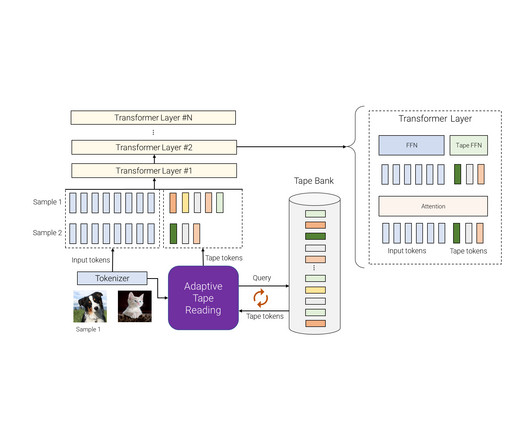
While conventional neural networks have a fixed function and computation capacity, i.e., they spend the same number of FLOPs for processing different inputs, a model with adaptive and dynamic computation modulates the computational budget it dedicates to processing each input, depending on the complexity of the input.
LRB , LHD , storage applications ), it remains a challenge to outperform robust heuristics in a way that can generalize reliably beyond benchmarks to production settings, while maintaining competitive compute and memory overheads. HALP learns its reward model fully online starting from a random weight initialization.
Posted by Yicheng Fan and Dana Alon, Software Engineers, Google Research Every byte and every operation matters when trying to build a faster model, especially if the model is to run on-device. Using a search space built on backbones taken from MobileNetV2 and MobileNetV3 , we find models with top-1 accuracy on ImageNet up to 4.9%
Posted by Ziniu Hu, Student Researcher, and Alireza Fathi, Research Scientist, Google Research, Perception Team Large-scale models, such as T5 , GPT-3 , PaLM , Flamingo and PaLI , have demonstrated the ability to store substantial amounts of knowledge when scaled to tens of billions of parameters and trained on large text and image datasets.
Further, TGIE represents a substantial opportunity to improve training of foundational models themselves. We also introduce EditBench , a method that gauges the quality of image editing models. The model meaningfully incorporates the user’s intent and performs photorealistic edits. First, unlike prior inpainting models (e.g.,
For comparison, the top-of-the-line RX 6900 XT 80 compute units, while the RX 6700 XT offers 40 compute units. The company cited research from IDC that claimed that roughly two-thirds of gaming displays sold last year were 1080p panels — but also that growth in high-refresh displays was 20 times higher than lower-refresh rate models.
This work led to the development of Project Relate for anyone with atypical speech who could benefit from a personalized speech model. Built in partnership with Google’s Speech team , Project Relate enables people who find it hard to be understood by other people and technology to train their own models.
Posted by Piotr Padlewski and Josip Djolonga, Software Engineers, Google Research Large Language Models (LLMs) like PaLM or GPT-3 showed that scaling transformers to hundreds of billions of parameters improves performance and unlocks emergent abilities. At first, the new model scale resulted in severe training instabilities.
His comments also come as OpenAIs text-to-video model Sora kicks off a new round of AI mania worldwide. However, comparison is inevitable, and Chinese companies focusing on AI products have always benchmarked their products against OpenAI’s models. He emphasized that only applications truly create direct value.”
The best expert in hindsight (and hence the benchmark to compare against) is the middle one, with total reward 21. In “ Online Learning and Bandits with Queried Hints ” (presented at ITCS 2023 ), we show how an ML model that provides us with a weak hint can significantly improve the performance of an algorithm in bandit-like settings.
Below we summarize the characteristics of HierText in comparison with other OCR datasets. The HierText challenge The HierText Challenge represents a novel task and with unique challenges for OCR models. These OCR products digitize and democratize the valuable information that is stored in paper or image-based sources (e.g.,
Robust algorithm design is the backbone of systems across Google, particularly for our ML and AI models. As an example, for graphs with 10T edges, we demonstrate ~100-fold improvements in pairwise similarity comparisons and significant running time speedups with negligible quality loss. You can find other posts in the series here.)
Either it’s built up from the base model with key improvements (as happened with last year’s iPad Air ) or it’s based on the premium, flagship version with some expensive parts stripped out or replaced. It’s the exact same size and shape as the 11-inch model. However, the comparison isn’t apples-to-apples (pardon the pun).
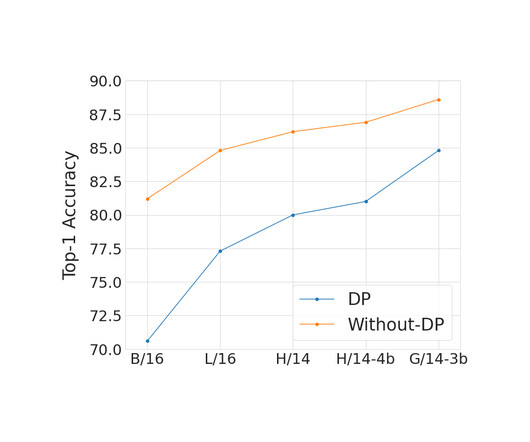
Posted by Harsh Mehta, Software Engineer, and Walid Krichene, Research Scientist, Google Research Large deep learning models are becoming the workhorse of a variety of critical machine learning (ML) tasks. In practice, DP training can be very expensive or even ineffective for very large models.
Currently, consumers can directly purchase one of a limited batch of Mate 60 Pro models with 12GB+521 GB storage, priced at RMB 6,999 ($960). However, the Mate 60 Pro model, which reportedly incorporates a self-developed 5G processor, could pave the way for Huawei to recapture some of its lost share of the smartphone market.
To me, you don’t include a “pro” model on day one unless you are very confident in the benchmarks and performance. Better to stick with just the mid-range model if you’re not sure. Apple is surely going to tout some impressive benchmarks for these Macs. But nope, Apple’s apparently going all-in. How fast is fast?
Then Google and Benchmark pumped $258 million more into it this past August. In comparison to creating effective and data-driven distribution funnels to get your app out to millions, software is cheap. The Huge team took a deep dive at the numbers on CrunchBase to work up estimates for Uber.
Cookieless reporting: what’s your approach, and what are your benchmarks? The point is, a fractured landscape makes comparisons across vendors harder. This is also a good time to look at your attribution model and consider investing in media mix modeling to help you evaluate performance across platforms without cookies.
Although prior work has demonstrated the benefits of ML in design optimization, the lack of strong, reproducible baselines hinders fair and objective comparison across different methods and poses several challenges to their deployment. cycle - accurate vs. ML - based proxy models ).
The Pura 70 Pro/Ultra models went on sale in China on Thursday, while the Standard/Pro+ models will be available on April 22. The tech blogger Digital Chat Station revealed that the processors in the Pro and Ultra models are both identified as the Kirin 9010. operating system.
inch screen is large enough to invite you to open multiple windows for side-by-side comparisons or just better multitasking. The model I’ve been able to try out is the mid-tier version with a 10th Gen Core i3 processor and 4GB of RAM. It might be fine if all you use is a single window, but the 21.5-inch
For example, the quintessential benchmark of training a deep RL agent on 50+ Atari 2600 games in ALE for 200M frames (the standard protocol) requires 1,000+ GPU days. Here, we propose an alternative approach to RL research, where prior computational work, such as learned models, policies, logged data, etc.,
Published on March 12, 2025 5:56 PM GMT Summary The Stages-Oversight benchmark from the Situational Awareness Dataset tests whether large language models (LLMs) can distinguish between evaluation prompts (such as benchmark questions) and deployment prompts (real-world user inputs).
At DataRobot , we define the benchmark of AI maturity as AI you can trust. In this installment, I’ll cover four key elements of trusted AI that relate to the performance of a model: data quality, accuracy, robustness and stability, and speed. Binary classification models are often optimized using an error metric called LogLoss.
After this is done , Pariti benchmarks each company against its peers. Companies in the same industry, product stage, revenue, fundraising are some of the comparisons made. It charges a subscription model for investors, but Berhane wouldn’t disclose the numbers. ” It doesn’t end there. ” Berhane said.
The base model starts at $2,039 and includes a Core i5-1135G7, 8GB of RAM, 128GB of storage, and a 14-inch 1920 x 1200 screen. I tested a more expensive 2-in-1 model listed at $2,926.75 I tested a more expensive 2-in-1 model listed at $2,926.75 New to this Latitude model is the SafeShutter, an automated physical camera cover.
inch and 15-inch Surface Laptop models with either Intel’s 11th-Gen processors or AMD’s Ryzen 4000 processors. But more importantly, there’s another company out there that recently made a huge chip upgrade to its flagship models, which has left most other 2020 chip upgrades in the dust: Apple, with its Arm-based M1. It costs $1,699.
inch model from 2019 that it’s replacing. The model I tested bumps the storage up to 512GB and the memory up to 16GB. I also received both the Magic Mouse and the Magic Trackpad with my model. That advantage bore out in our benchmark testing. In this comparison, multi-core results are more important.
We first show Method 1: time-horizon-extension , a relatively simple model which forecasts when SC will arrive by extending the trend established by METRs report of AIs accomplishing tasks that take humans increasing amounts of time. Our distributions accounting for factors outside of this model are wider.
Industry benchmarks and comparisons: Consider the larger trends at play that impact your results. Industry benchmarks can help audience members compare your organization’s performance against industry standards and identify key performance indicators (KPIs) that help set realistic goals.
We organize all of the trending information in your field so you don't have to. Join 12,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content