This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The 16th annual Blackbaud Luminate Online Benchmark Report is here! It’s also a valuable tool to help nonprofits evaluate their results by giving them a comparison point for their performance against organizations of similar sizes and issue areas. We look forward to this report every year.
Hey data friends, it’s our favorite time of the year, the birds are singing, the flowers are blooming, you can sip your iced coffee outside and read Benchmarks ! It’s not accurate to compare UA pageview data to GA4 pageview data since the metric logic has also changed. Give it a read here !
Leaderboards for popular benchmarks are full of examples of Red AI where improvements are often the result of scaling processing power. To illustrate the energy needed in deep learning, let’s make a comparison. As a hardware-independent metric, they recommend the amount of floating-point operations (FLOPs) to measure model size.
Over the holidays, I used DataRobot to reproduce a few machine learning benchmarks. The SARCOS dataset is a widely used benchmark dataset in machine learning. I tested this dataset because it appears in various benchmarks by Google and fast.ai. For comparison, a random forest model achieves 2.38 SARCOS Dataset Failure.
Stephen Downes summarized my post on Social Media Metrics and Measuring Blog Outcomes and added some commentary. My post wasa riff on evaluating the effectiveness of blogs, and in particular, a set of metrics from Avinash Kaushik: "Raw Author Contribution (posts and words in post). Some pr professionals agree.
Static workload benchmark is insufficient. The standard way to evaluate ANN indexes is to use a static workload benchmark , which consists of a fixed dataset and a fixed query set. A static workload benchmark. This evaluation approach was popularized by the ann-benchmarks project which started 5 years ago. MIT Licence.
Nonprofit engagement metrics can help you understand your organization, but you’ve probably seen the same terms over and over again in your research. By embracing a few overlooked metrics, you will be able to go deeper into that information. By embracing a few overlooked metrics, you will be able to go deeper into that information.
Using that knowledge, we’ve created this guide to help your team understand major gift KPIs, the metrics you should be tracking, and the top tips to do so successfully. You’ll explore major gift metrics through the following guide: Overview of Major Gift Fundraising Data. 3 Tips to Track Major Gift Metrics More Effectively.
Now you’ve identified how you’re using the story, we’re going to get into the weeds to identify your metrics and markers of success. Now for the metrics beyond total engagement on the posts, this is where you’ll customize your measurements further. This will give you a starting point for comparison and assessment of your strategy.
According to the “ eNonprofit Benchmarks Study ” done by NTEN (shout out to Holly Ross ) email is still the “killer app” that reaches the most people. By understanding your activity and performance, fan response, trends and comparisons, you are better equipped to improve your presence on Facebook. Why is this important?
When you send a fundraising email can be the difference between improved engagement metrics (open rate, click-through rate, donation amount, etc.) We paid close attention to key email engagement metrics, including email performance by time of day. Compare engagement metrics and test until you see improvements.
Experimental results When comparing NAS algorithms, we evaluate the following metrics: Quality : What is the most accurate model that the algorithm can find? Below, we visualize the differences between these search algorithms for the metrics described above. Comparison on models under different #MAdds. See the paper for details.
REVEAL achieves higher accuracy in comparison to previous works including ViLBERT , LXMERT , ClipCap , KRISP and GPV-2. We also evaluate REVEAL on the image captioning benchmarks using MSCOCO and NoCaps dataset. Image Captioning results on MSCOCO and NoCaps using the CIDEr metric. GPT-3) as an implicit source of knowledge.
You can download the complete report here , and don''t forget the companion online benchmarking tool , where you can compare some of your organization''s data against your peers in our research. This gives us (and you) a more comparable metric. FTE tech staff for your team is keeping up.
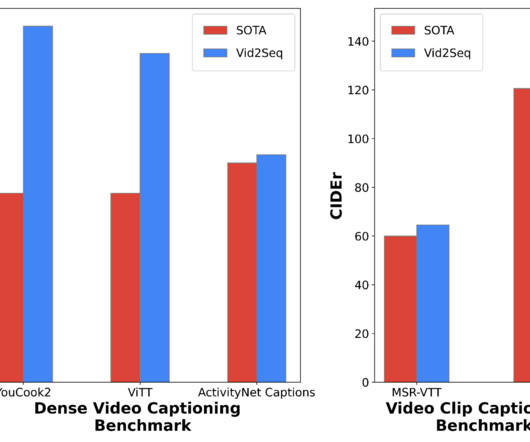
The resulting Vid2Seq model pre-trained on millions of narrated videos improves the state of the art on a variety of dense video captioning benchmarks including YouCook2 , ViTT and ActivityNet Captions. Vid2Seq is pre-trained on unlabeled narrated videos with a generative objective ( top ) and a denoising objective ( bottom ).
(I've definitely added that link to my social media metrics personal learning space ) She recently pointed to a blog post called " Ten Ways To Measure Social Media Success " by Chris Lake. A baseline is a measurement that you can use as a comparison to measure progress against a goal or do before/after comparisons.
Each example consists of (1) a masked input image, (2) an input text prompt, and (3) a high-quality output image used as reference for automatic metrics. Due to the intrinsic weaknesses in existing automatic evaluation metrics ( CLIPScore and CLIP-R-Precision ) for TGIE, we hold human evaluation as the gold standard for EditBench.
This is the number you can use to compare the relative robustness of your messaging program with the results reported by the " eNonprofit Benchmarks Study " (or Convio's " Online Nonprofit Benchmarks Study " or MailChimp's " Email Marketing Benchmarks by Industry ", or.). We're always looking for new metrics.
This time, the company’s typical array of charts, benchmarks, and “fastest ever” claims for each new generation of homegrown ARM silicon were completely MIA. The closest we got to a comparison was effectively, “is machine learning faster with hardware acceleration turned on?”. a handful of canned demos and vague promises.
Human object recognition alignment To find out how aligned ViT-22B classification decisions are with human classification decisions, we evaluated ViT-22B fine-tuned with different resolutions on out-of-distribution (OOD) datasets for which human comparison data is available via the model-vs-human toolbox.
We also use the median for our comparisons, so that one outlier doesn’t skew the whole set. Average gift was nearly flat year over year for the median organization, but this metric is especially volatile and easily pulled by outliers. And boy, were there some outliers this year. On to the goods! . Giving Tuesday: December Edition.
I’m not going to go down an entire benchmarking rabbit hole about the new A14 Bionic processor on the 2020 iPad Air even though I’m sorely tempted to. So I fully expect there to be a wash of articles detailing the many benchmark results you can get on this chip and what they could portend for the future. iPad Air specs and processor.
This filter may affect your key metrics, and you’ll want to make sure to be able to quantify the effect it has made on your data. This may come in handy if monthly or yearly comparisons are made and people wonder why traffic dropped. After you have recorded the deltas in your benchmarkmetrics, you have 2 options.
After this is done , Pariti benchmarks each company against its peers. Companies in the same industry, product stage, revenue, fundraising are some of the comparisons made. Pariti then assesses each company across more than 70 information points ranging from the team and market to product and economics.
For example, the quintessential benchmark of training a deep RL agent on 50+ Atari 2600 games in ALE for 200M frames (the standard protocol) requires 1,000+ GPU days. For benchmark evaluation, we report the interquartile mean (IQM) metric from the RLiable library. pre-trained teacher policies) on a given benchmark.
About a year ago, I decided to benchmark my blog using some tips suggested by Avinash Kaushik. Measuring the success of social media efforts can't be done with a single metric. I think there will be different metrics for different strategies, organizations, and tools. I don't think this metric has any meaning in isolation.
Although prior work has demonstrated the benefits of ML in design optimization, the lack of strong, reproducible baselines hinders fair and objective comparison across different methods and poses several challenges to their deployment. At its core, the interface entails three main signals: hardware state , hardware parameters , and metrics.
Industry benchmarks and comparisons: Consider the larger trends at play that impact your results. Industry benchmarks can help audience members compare your organization’s performance against industry standards and identify key performance indicators (KPIs) that help set realistic goals.
As an example, for graphs with 10T edges, we demonstrate ~100-fold improvements in pairwise similarity comparisons and significant running time speedups with negligible quality loss. We had previously applied this idea to develop massively parallel algorithms for metric , and minimum-size clustering.
Analyzing Your Website’s Organic Traffic To understand how people are finding and engaging with your nonprofit website, you need to set up analytics and regularly monitor performance metrics. You’ll find key metrics under the Acquisition > All Traffic > Channels menu in your GA dashboard.
In this blog we take a technical deep dive into the cost and performance of their serverless SQL warehouse product by utilizing the industry standard TPC-DI benchmark. In the table above, we look at the cost comparison of on-demand vs. spot costs as well. What are Databricks’ SQL warehouse offerings? AWS EC2 bill). Image by author.
After you've been able to use metrics to learn what works and adapt your approach, you can use a traditional approach which begins with defining value and culminates with a financial calculation that could go something like this. It uses metrics to measure your results and help you improve your strategy over time. Defined Audience.
At DataRobot , we define the benchmark of AI maturity as AI you can trust. Binary classification models are often optimized using an error metric called LogLoss. It enables direct comparisons of accuracy between diverse machine learning approaches. Trust must be established between an AI user and the system.
Dell and Intel are pushing this combination as a way to please IT departments while also competing with the best consumer laptops on performance, battery life, and other standard productivity metrics. For a more modern comparison, both the XPS 13 and the XPS 13 2-in-1 (both with a Core i7-1165G7) took over 10 minutes to complete the task.
This year’s summit included data from a variety of sectors, drawn directly from participant CRMs and standardized to allow for consistent comparisons. Unlike many other key metrics, the share of recurring donors that upgraded their average gift did not increase in FY2020. Telemarketing and direct mail followed. Sustainer Upgrades.
Benchmark Studies and Examples. In the US, there are several terrific benchmark studies of nonprofits and technology , including some on social networking but these are focused mostly on US nonprofits. I spent some time searching for similar studies or compilations for international organizations as well as some specific examples.
Define your key metrics – Do you want to increase form conversion rates, or increase average gift size, increase the number of people signing up for sustaining gifts, or some other factor? Gather information and resources – Benchmarks and tips are a great start. Analyze the data – Once again, Google makes it easy.
Promises include: Tuva wants to become the open standard for healthcare data transformation and build the data network for multisite benchmarking and research. GrowthBook says it solves this by using a company’s existing data infrastructure and business metrics.
To establish benchmarks for measuring success of our design efforts. Once we’ve set the timeframe, we then start digging into the data to answer some key questions: What are some benchmark stats for improvement? If we set up Goals, reviewing them post-launch is another great success metric. Methodology. Research Questions.
Polar Areas charts are particularly effective for showcasing relationships and proportions among multiple variables in a format emphasizing comparisons and trends. Radar charts are particularly useful for displaying performance metrics across multiple areas in a way that is easy to compare and contrast.
Performance comparison between the PaLM 540B parameter model and the prior state-of-the-art (SOTA) on 58 tasks from the Big-bench suite. For example, PaLI achieves state-of-the-art results on the CrossModal-3600 benchmark , a diverse test of multilingual, multi-modal capabilities with an average CIDEr score of 53.4
Your websites donation page conversion rate is among the most important metrics to track when evaluating your nonprofit websites ROI. According to the most recent M+R Benchmarks report , conversion rates for main nonprofit donation pages are just 16%, while mobile donation pages see a 10% conversion rate on average. Track key metrics.
We then present Method 2: benchmarks-and-gaps , a more complex model starting from a forecast saturation of an AI R&D benchmark ( RE-Bench ), and then how long it will take to go from that system to one that can handle real-world tasks at the best AGI company. Method 2: Benchmarks and gaps Time to RE-Bench saturation Why RE-Bench?
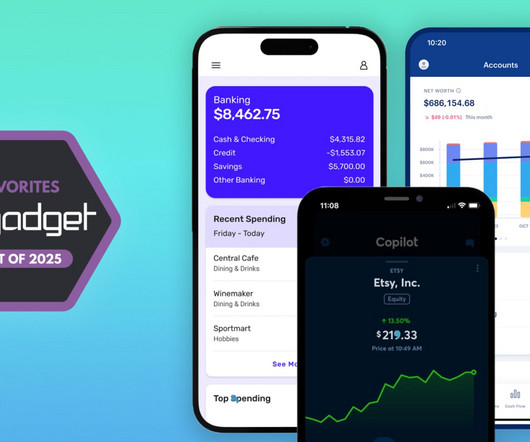
The main dashboard shows your net worth; your four most recent transactions; a month-over-month spending comparison; income month-to-date; upcoming bills; an investments snapshot; a list of any goals youve set; and, finally, a link to your month-in-review. The mobile app is mostly self-explanatory.
We organize all of the trending information in your field so you don't have to. Join 12,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content