This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
are nowhere near achieving AGI (Artificial General Intelligence), according to a new benchmark. The Arc Prize Foundation, a nonprofit that measures AGI progress, has a new benchmark that is stumping the leading AI models. Google, OpenAI, DeepSeek, et al. OpenAI's o3-low model scored 75.7 percent on the first edition of ARC-AGI.
The 16th annual Blackbaud Luminate Online Benchmark Report is here! It’s also a valuable tool to help nonprofits evaluate their results by giving them a comparison point for their performance against organizations of similar sizes and issue areas. We look forward to this report every year.
The A14 is an ideal machine for writing on the go, since you can travel with it effortlessly and it offers a whopping 18 hours and 16 minutes of battery life (according to the PCMark 10 benchmark). But in comparison to the Surface Pro and Laptop, it's like driving an entry-level car instead of a true luxury offering.
We’ve been chatting about how to measure the impact of the crowd and she offered to write this guest post on the topic. Measuring Your Crowdsourcing Efforts by Aliza Sherman. In order to know how to measure crowdsourcing results, you first need to understand what kind of crowdsourcing you’re implementing. Measuring Work.
While techniques and equipment are important, it is also useful to have some benchmarks and best practices in the nonprofit sector to inform your strategy and measurement plan. Tactics will only go so far. Currently, there are no significant benchmarks around video for nonprofits. Why should you participate?
One of the best storytelling tips I can give you is to set yourself up for measurement success from the very beginning. It can be near impossible to measure the success of a story if you haven’t first thought about what your desired outcomes are and drivers of success. This could be a quarter, month or week.
Static workload benchmark is insufficient. The standard way to evaluate ANN indexes is to use a static workload benchmark , which consists of a fixed dataset and a fixed query set. A static workload benchmark. This evaluation approach was popularized by the ann-benchmarks project which started 5 years ago. MIT Licence.
And, as I was sharing earlier, we usually teach this in person over a period of two to three hours, so, you all are getting the, what we’ll call, the boot-camp version of “Measure of Success.” Was there anything helpful about that comparison between service engagement and impact? Is it measurable? 0001 pounds.
Over the holidays, I used DataRobot to reproduce a few machine learning benchmarks. The SARCOS dataset is a widely used benchmark dataset in machine learning. I tested this dataset because it appears in various benchmarks by Google and fast.ai. For comparison, a random forest model achieves 2.38 SARCOS Dataset Failure.
We’d like to try to benchmark it against other disruptive pinterest campaigns but we’re not sure there is a good comparison case study. We predicted it might be smaller as the campaign is disruptive to the usual pinterest pattern. Please tell us if you know of one! Pinterest has only been around for short time.
About a year ago, I decided to benchmark my blog using some tips suggested by Avinash Kaushik. A year ago, he said that measuring outcomes for social media is, "an evolving art (not quite a science yet) and you have to be up to the challenge of both thinking a bit differently and be ok with leveraging several different tools.
HowSociable provides a simple way for you to begin measuring your brand???s It measures mentions on these twenty sites. For comparison, I benchmarked myself against Chris Pirillo. Click for larger image or here. s visibility on the social web. I scored 359 on September 1st.
Take her ROI and Measurement list. I've definitely added that link to my social media metrics personal learning space ) She recently pointed to a blog post called " Ten Ways To Measure Social Media Success " by Chris Lake. What I found most valuable was the tip about getting a baseline measurement before you begin.
You can download the complete report here , and don''t forget the companion online benchmarking tool , where you can compare some of your organization''s data against your peers in our research. Another way we measure technology staffing levels is determing the Tech Staff - to - Organizational Staff Ratio.
LRB , LHD , storage applications ), it remains a challenge to outperform robust heuristics in a way that can generalize reliably beyond benchmarks to production settings, while maintaining competitive compute and memory overheads. The labels for these pending comparisons can only be resolved at a random future time.
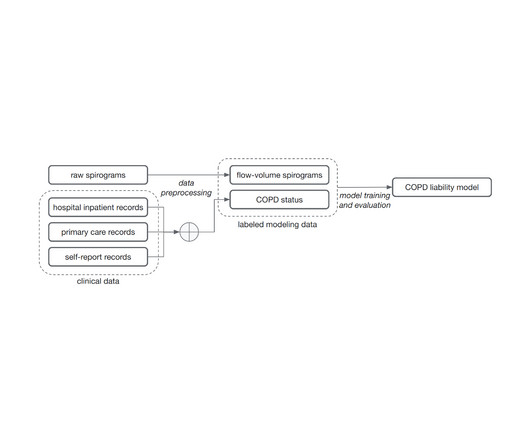
One challenge in this process is how we make sense of the vast amount of clinical measurements — the UK Biobank has many petabytes of imaging, metabolic tests, and medical records spanning 500,000 individuals. Precision-recall curves for COPD status and outcomes for our ML model (green) compared to traditional measures.
The traditional measure of open rates – total messages opened ÷ total messages delivered – should be used to gauge the overall health of your e-mail program. Because the comparisons will never be exact, the most important thing to watch is your True Open Rate over time. That's where the "Unweighted Open Rate" comes in. and take action.
If I have learned anything from co-writing a book about measurement , that it is not only important to collect your data, but leave space for reflection at the end of a campaign to harvest insights for the next campaign. I try to do this with any project I work on, whether it is a social media campaign as well as a training workshops.
Human object recognition alignment To find out how aligned ViT-22B classification decisions are with human classification decisions, we evaluated ViT-22B fine-tuned with different resolutions on out-of-distribution (OOD) datasets for which human comparison data is available via the model-vs-human toolbox. Cat or elephant? Car or clock?
Stephen Downes summarized my post on Social Media Metrics and Measuring Blog Outcomes and added some commentary. Conversation Rate (measuring success in a social medium). Technorati "Authority" (measuring your impact on the world!). Stephen goes on to say: Measuring "your blog's outcome" is ridiculous.
According to the “ eNonprofit Benchmarks Study ” done by NTEN (shout out to Holly Ross ) email is still the “killer app” that reaches the most people. By understanding your activity and performance, fan response, trends and comparisons, you are better equipped to improve your presence on Facebook. What is measured you ask? .
REVEAL achieves higher accuracy in comparison to previous works including ViLBERT , LXMERT , ClipCap , KRISP and GPV-2. We also evaluate REVEAL on the image captioning benchmarks using MSCOCO and NoCaps dataset. REVEAL achieves a higher score in comparison to Flamingo , VinVL , SimVLM and CoCa.
Then Google and Benchmark pumped $258 million more into it this past August. There’s also the enormous looming cost of distribution — one that’s hard to measure and even harder to predict. In comparison to creating effective and data-driven distribution funnels to get your app out to millions, software is cheap.
As an example, for graphs with 10T edges, we demonstrate ~100-fold improvements in pairwise similarity comparisons and significant running time speedups with negligible quality loss. We find that academic GNN benchmark datasets exist in regions where model rankings do not change. All transactions are stored to allow fault-tolerance.
inches) and slightly slimmer, the Nvidia card is also a bit quieter under load — both in terms of the RX 6800 having a somewhat louder hum and audibly ramping its fan up and down a tad more often in the middle of a benchmark. Not only is it a full inch shorter than the RX 6800 (9.5 inches versus 10.5 Each still has HDMI 2.1
To me, you don’t include a “pro” model on day one unless you are very confident in the benchmarks and performance. Apple is surely going to tout some impressive benchmarks for these Macs. tons and measures about 15-18 feet long, according to Giegel. Better to stick with just the mid-range model if you’re not sure. It weighs 2.5
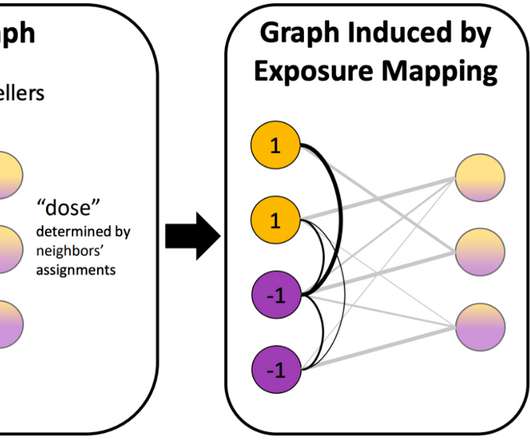
The user’s satisfaction is measured by a reward that depends on unknown factors such as user preferences and road segment delays. The best expert in hindsight (and hence the benchmark to compare against) is the middle one, with total reward 21. An instance of the experts problem.
Published on March 12, 2025 5:56 PM GMT Summary The Stages-Oversight benchmark from the Situational Awareness Dataset tests whether large language models (LLMs) can distinguish between evaluation prompts (such as benchmark questions) and deployment prompts (real-world user inputs).
The Kirin 9010 processor achieved a single-core score of 1,442 and a multi-core score of 4,471 on Geekbench, a cross-platform benchmarking tool used to measure and compare the performance of CPUs and GPUs across various computing devices.
This was a considerable commitment, but many in the sector saw a need to measure the impact and effectiveness of such funding—specifically, whether the funds were going to nonprofits led by communities of color or to more traditional, white-led institutions. The best way to answer these questions is to measure and analyze consistent data.
At DataRobot , we define the benchmark of AI maturity as AI you can trust. This includes the basics: Computing summary statistics on each feature Measuring associations between features Observing feature distributions and their correlation with the predictive target Identifying outliers. Use Multiple Tools and Visualizations.
To establish benchmarks for measuring success of our design efforts. Once we’ve set the timeframe, we then start digging into the data to answer some key questions: What are some benchmark stats for improvement? Our purposes for using Analytics as User Research are: To learn about current visitors to the website. Methodology.
And, it also includes measurement - not just qualitative information. It uses metrics to measure your results and help you improve your strategy over time. ROI had it origins as an accounting term and was originally a measure of return on the total investment in the entire business. Use of metrics to measure your results.
Polar Areas charts are particularly effective for showcasing relationships and proportions among multiple variables in a format emphasizing comparisons and trends. To build your own, assign one dimension with categories to the Level mark and assign one or multiple measures to Value. Radial Chart Viz Extension by Actinvision in Tableau.
I’m teaching a graduate class at the Monterey Institute of International Studies based on my books, The Networked Nonprofit and Measuring the Networked Nonprofit. Benchmark Studies and Examples. The course is about how to leverage networks and social media for learning and impact.
As some sort of measure of accountability, raw web statistics (this site got x visits and y pageviews in t timeframe) mean zilch. to care a whole lot about how many hits they got in comparison to similar (or different) organizations. On a related note, I think a benchmarking study might be a useful exercise for nonprofits.
The Dell XPS 15 with the same processor and a GTX 1650 Ti took four minutes and 23 seconds (though different versions of Premiere Pro can impact export times, so synthetic benchmarks such as Cinebench are more precise for direct comparison).
Performance comparison between the PaLM 540B parameter model and the prior state-of-the-art (SOTA) on 58 tasks from the Big-bench suite. One of the areas where multi-step reasoning is most clearly beneficial and measurable is in the ability of models to solve complex mathematical reasoning and scientific problems.
Because of this, it’s important to carefully measure major gifts key performance indicators (KPIs) to understand the success of your program as a whole and specific strategies individually. What are the major gift metrics that matter when measuring success? Why is it important to track fundraising benchmarks?
This year’s summit included data from a variety of sectors, drawn directly from participant CRMs and standardized to allow for consistent comparisons. Offering a premium can work for conversion, though careful monitoring of retention should be a part of the measured results. A lower ask amount may be necessary to convert more donors.
I previously tested the RTX 3080 on an older Core i7-7700K , so I’ve gone back and tested Nvidia’s flagship on this new system to provide a comparison between the RTX 2080, RTX 3070, and RTX 3080. As you can see in the benchmark chart below, you won’t often need an RTX 3080 to max out today’s games with a 1440p monitor.
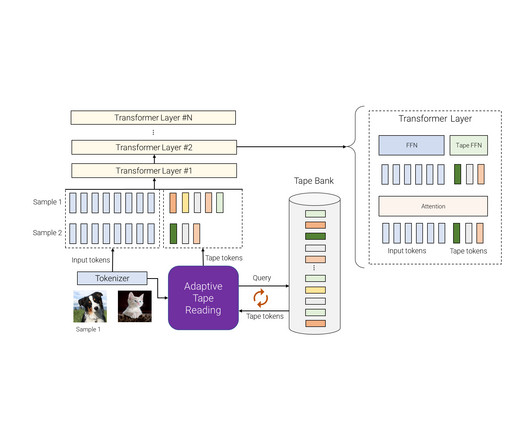
This model is a Transformer-based architecture that uses a dynamic set of tokens to create elastic input sequences, providing a unique perspective on adaptivity in comparison to previous works. In the paper “ Adaptive Computation with Elastic Input Sequence ”, we introduce a new model that utilizes adaptive computation, called AdaTape.
Want to learn more about the nonprofit email benchmarks that your organization should be using to measure success? However, this metric doesn’t truly measure social media engagement. It’s a very simple measure of engagement that’s often used in the for-profit sector. Download the full report today!
There are a few standard datasets in the field that are often used to benchmark models and compare accuracies, but new datasets are being developed every day as labeled data continues to become available. In the field of sentiment analysis, one model works particularly well and is easy to set up, making it the ideal baseline for comparison.
We organize all of the trending information in your field so you don't have to. Join 12,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content