This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Im intrigued by that model based on benchmarks I saw elsewhere, of course. In-use: A rocketship for content creators Mignon Alphonso for Engadget The Mac Studio with M4 Max destroyed most synthetic benchmarks, showing the highest single-core Geekbench 6 CPU score for any PC weve tested. Should you buy the Mac Studio?
The 16th annual Blackbaud Luminate Online Benchmark Report is here! It’s also a valuable tool to help nonprofits evaluate their results by giving them a comparison point for their performance against organizations of similar sizes and issue areas. We look forward to this report every year.
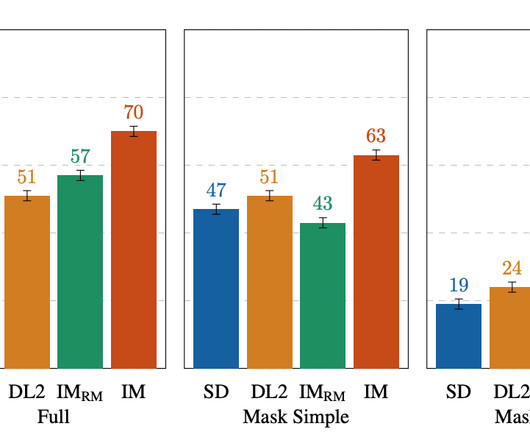
EditBench The EditBench dataset for text-guided image inpainting evaluation contains 240 images, with 120 generated and 120 natural images. We evaluate Mask Simple, Mask Rich and Full Image prompts, consistent with conventional text-to-image models. In the section below, we demonstrate how EditBench is applied to model evaluation.
In this post, I point to several problems with the way we currently evaluate ANN indexes and suggest a new type of evaluation. Static workload benchmark is insufficient. Static workload benchmark is insufficient. A static workload benchmark. See the Qdrant benchmark and Timescale benchmark.
At DataRobot , we define the benchmark of AI maturity as AI you can trust. Accuracy is best evaluated through multiple tools and visualizations, alongside explainability features, and bias and fairness testing. It enables direct comparisons of accuracy between diverse machine learning approaches. Download Now.
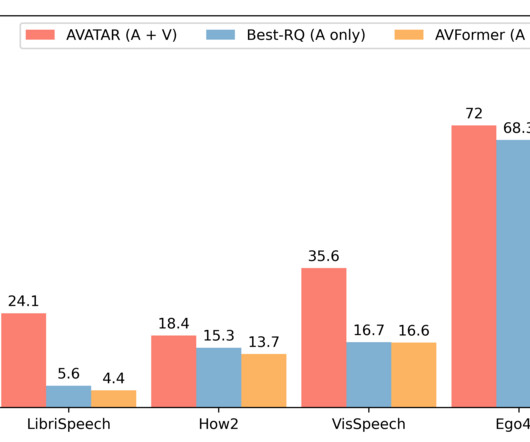
The resulting AVFormer model achieves state-of-the-art zero-shot performance on three different AV-ASR benchmarks (How2, VisSpeech and Ego4D ), while also crucially preserving decent performance on traditional audio-only speech recognition benchmarks (i.e., LibriSpeech ). Unconstrained audiovisual speech recognition.
After co-founder and CEO Munjal Shah sold his previous company, Like.com, a shopping comparison site, to Google in 2010, he spent the better part of the next decade building Hippocratic. Hippocratic’s benchmark results on a range of medical exams. ” AI in healthcare, historically, has been met with mixed success.
Our experimental evaluation shows that within these constraints we are able to discover top-performance models. Experimental results When comparing NAS algorithms, we evaluate the following metrics: Quality : What is the most accurate model that the algorithm can find? Comparison on models under different #MAdds.
Results We evaluate REVEAL on knowledge-based visual question answering tasks using OK-VQA and A-OKVQA datasets. REVEAL achieves higher accuracy in comparison to previous works including ViLBERT , LXMERT , ClipCap , KRISP and GPV-2. We also evaluate REVEAL on the image captioning benchmarks using MSCOCO and NoCaps dataset.
A baseline is a measurement that you can use as a comparison to measure progress against a goal or do before/after comparisons. Chris suggests: Before you start the clock it is a good idea to benchmark where you’re at. Make a note of ROI benchmarks. Make a note of the obvious numb ers.
Published on March 12, 2025 5:56 PM GMT Summary The Stages-Oversight benchmark from the Situational Awareness Dataset tests whether large language models (LLMs) can distinguish between evaluation prompts (such as benchmark questions) and deployment prompts (real-world user inputs).
Human object recognition alignment To find out how aligned ViT-22B classification decisions are with human classification decisions, we evaluated ViT-22B fine-tuned with different resolutions on out-of-distribution (OOD) datasets for which human comparison data is available via the model-vs-human toolbox. Cat or elephant? Car or clock?
Knowing what work you need done and the quality of work you’d like to receive and set benchmarks to measure outcomes. You should also review how you’ve traditionally done the work or solicited the input or encouraged the action in the past and note what worked and what didn’t work previously to use as a comparison to crowdsourced efforts.
Comparison of four prompting methods, (a) Standard, (b) Chain of thought (CoT, Reason Only), (c) Act-only, and (d) ReAct, solving a HotpotQA question. A comparison of the ReAct ( top ) and CoT ( bottom ) reasoning trajectories on an example from Fever (observation for ReAct is omitted to reduce space).
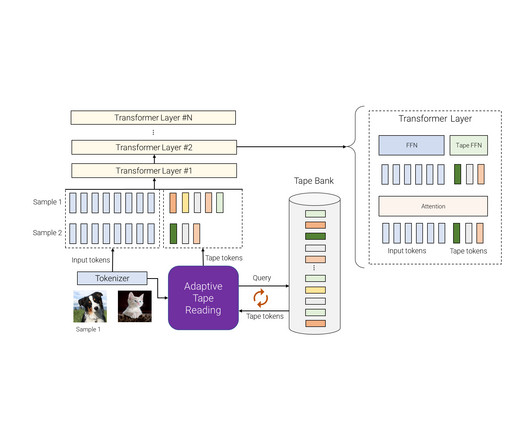
This model is a Transformer-based architecture that uses a dynamic set of tokens to create elastic input sequences, providing a unique perspective on adaptivity in comparison to previous works. Evaluation on the parity task. Evaluation on image classification We also evaluate AdaTape on the image classification task.
To improve a model for this use case, we created the Real Conversation test set to benchmark performance. Results To evaluate the adapted USM, we compared it to older ASR models using the two test sets described above. We have previously shown that this approach works very well to adapt ASR models to disordered speech.
Posted by Amir Yazdanbakhsh, Research Scientist, and Vijay Janapa Reddi, Visiting Researcher, Google Research Computer Architecture research has a long history of developing simulators and tools to evaluate and shape the design of computer systems. It comprises two main components: 1) the ArchGym environment and 2) the ArchGym agent.
Cookieless reporting: what’s your approach, and what are your benchmarks? The point is, a fractured landscape makes comparisons across vendors harder. This is also a good time to look at your attribution model and consider investing in media mix modeling to help you evaluate performance across platforms without cookies.
My post wasa riff on evaluating the effectiveness of blogs, and in particular, a set of metrics from Avinash Kaushik: "Raw Author Contribution (posts and words in post). I agree with you that it is meaningless to use the numbers to get into "mine is bigger than yours" comparisons to measure quality or popularity.
My many years of experience collecting and analyzing data as an evaluator naturally lead me to ask: What has been the measurable impact of this important shift? At the 2022 Asian Americans/Pacific Islanders in Philanthropy (AAPIP) conference, a few fellow evaluators and I discussed the findings of the AAPIP report Seeking to Soar.
As an example, for graphs with 10T edges, we demonstrate ~100-fold improvements in pairwise similarity comparisons and significant running time speedups with negligible quality loss. We find that academic GNN benchmark datasets exist in regions where model rankings do not change. All transactions are stored to allow fault-tolerance.
In this blog we take a technical deep dive into the cost and performance of their serverless SQL warehouse product by utilizing the industry standard TPC-DI benchmark. In the table above, we look at the cost comparison of on-demand vs. spot costs as well. What are Databricks’ SQL warehouse offerings? AWS EC2 bill). Image by author.
We think this adversarial style of evaluation and iteration is necessary to ensure an AI system has a low probability of catastrophic failure. Wed like to support more such evaluations, especially on scalable oversight protocols like AI debate. and Which rules are LLM agents happy to break, and which are they more committed to? .
To establish benchmarks for measuring success of our design efforts. Ideally, we’d evaluate the previous year of data to observe patterns in different giving cycles. If a client hasn’t had Analytics for a year, 3 months would be the shortest timeframe we’d want to evaluate to ensure we get a clear enough picture of trends over time.
Performance comparison between the PaLM 540B parameter model and the prior state-of-the-art (SOTA) on 58 tasks from the Big-bench suite. Minerva 540B significantly improves state-of-the-art performance on STEM evaluation datasets. We show the MattNet results for comparison. See paper for details.)
Benchmark Studies and Examples. In the US, there are several terrific benchmark studies of nonprofits and technology , including some on social networking but these are focused mostly on US nonprofits. I spent some time searching for similar studies or compilations for international organizations as well as some specific examples.
Evaluate your websites revenue and costs holistically to determine the current return on various investments made to build and improve the site. Your websites donation page conversion rate is among the most important metrics to track when evaluating your nonprofit websites ROI. Prioritize conversion optimization.
Are you ready to evaluate the success of your major gifts program? Why is it important to track fundraising benchmarks? But, to be honest, carefully tracking and evaluating each and every point would be more stress than it’s worth! Let’s look at this in comparison to some of the metrics discussed above.
We’ve created this guide to nonprofit CRM options, through which you’ll review the basics of CRM software and a side-by-side comparison of the top solutions through the following points: Overview of CRM for Nonprofits. Nonprofit CRM Comparison: Top 7 Solutions. Nonprofit CRM Comparison: Top 7 Solutions.
Want to learn more about the nonprofit email benchmarks that your organization should be using to measure success? If your abandonment rate is significantly higher than your conversion rate, you’ll know that it’s time to evaluate your donation form and look for areas to improve. Download the full report today!
to care a whole lot about how many hits they got in comparison to similar (or different) organizations. On a related note, I think a benchmarking study might be a useful exercise for nonprofits. And, I actually hope that doesn’t change. This could ultimately be detrimental to the very people you are trying to help.
A review of the M16, then, isn’t just an opportunity to evaluate Asus’ product. Intra-Asus comparisons aside, six hours isn’t a great result for a laptop that’s supposed to be able to double as a primary driver when needed (which is the primary benefit of the 16:10 screen). You’ll want to turn on Silent mode if you’re not gaming. (To
Financial calculations: net gain, opportunity cost, or comparison to other method. I've been doing the ROI analysis openly on my blog for the past two years and the presentation uses a slightly more refined version of this benchmarking process. Benchmark studies. Use of metrics to measure your results. Communicating the results.
In those days, we were tackling terrible Android and BlackBerry tablets, evaluating the first wave of Intel ultrabooks , and heaping praise on the then-revolutionary Galaxy Nexus. It was the first time The Verge evaluated VR as a product, not just a dream. Even figuring out how to photograph the Rift was an exhilarating experience.
Conversely, if the technology your nonprofit uses is actually making things harder for your team, it may be time to evaluate a new solution. Alternatively, you can run two different email campaigns and compare their performance, then use that comparison to inform future campaigns.
Fundraising Donor Management Software Comparison: What’s Right for Your Nonprofit? Evaluation In this stage, the potential donor begins to consider making a donation to your nonprofit. When trying to measure success, it helps to have benchmarks —and it helps even more if those benchmarks speak specifically to your sector.
Are you going to use this to evaluate your internal operations so that you can become more efficient, more effective. Was there anything helpful about that comparison between service engagement and impact? How will they to be evaluated and organized? ” What are the things donors want to see? Does that make sense?
For example, the quintessential benchmark of training a deep RL agent on 50+ Atari 2600 games in ALE for 200M frames (the standard protocol) requires 1,000+ GPU days. Given the PVRL algorithm requirements, we evaluate whether existing approaches, designed with closely related goals, will suffice. Left: Fine-tuning DQN with Adam.
These layout analysis efforts are parallel to OCR and have been largely developed as independent techniques that are typically evaluated only on document images. Below we summarize the characteristics of HierText in comparison with other OCR datasets. As such, the synergy between OCR and layout analysis remains largely under-explored.
Investors and developers need to understand where to acquire real estate assets and when to trigger development, while portfolio managers need to optimize their holdings and recurrently evaluate real estate conditions to decide if they should divest or not. Real estate developers aim to identify underused but high-value land for development.
And the few positive applications with clear comparisons to baselines, like Karvonen et al , largely occur in somewhat niche or contrived settings (e.g. Both of these approaches lead to improvements on our probing benchmarks relative to the baseline GemmaScope SAEs, matching Kissane et al , as discussed in the section below.
The reality is that I collaborate with strong partners on data and the associated analytics then spend the time needed to understand and evaluate our fundraising programs at Project HOPE. Data and the understanding and interpreting of metrics is something I have to work hard at, because it simply does not come naturally to me.
We organize all of the trending information in your field so you don't have to. Join 12,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content