This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Hey data friends, it’s our favorite time of the year, the birds are singing, the flowers are blooming, you can sip your iced coffee outside and read Benchmarks ! Even comparing Total Users from UA to GA4 is not an apples-to-apples comparison since the method Google Analytics uses to track users changed from UA to GA4.
When Apple first announced that it would be transitioning its computers — specifically, the MacBook Air and entry-level 13-inch MacBook Pro, its most popular PCs — to a new and wildly different type of processor, there were plenty of reasons to be skeptical. Paul Hudson (@twostraws) November 17, 2020.
Static workload benchmark is insufficient. The standard way to evaluate ANN indexes is to use a static workload benchmark , which consists of a fixed dataset and a fixed query set. A static workload benchmark. This evaluation approach was popularized by the ann-benchmarks project which started 5 years ago. MIT Licence.
World Giving Index Charities Aid Foundation looked at three different types of charitable behavior – giving money, giving time and helping a stranger and used the results to produce the “World Giving Index.&# 2011 eNonprofit Benchmarks Study A visual version of the 2011 eNonprofit Benchmarks Study by M+R Strategic Services and NTEN.
Over the holidays, I used DataRobot to reproduce a few machine learning benchmarks. The SARCOS dataset is a widely used benchmark dataset in machine learning. I tested this dataset because it appears in various benchmarks by Google and fast.ai. For comparison, a random forest model achieves 2.38 SARCOS Dataset Failure.
We’d like to try to benchmark it against other disruptive pinterest campaigns but we’re not sure there is a good comparison case study. We predicted it might be smaller as the campaign is disruptive to the usual pinterest pattern. Please tell us if you know of one! Is your nonprofit placing a little bet on pinterest?
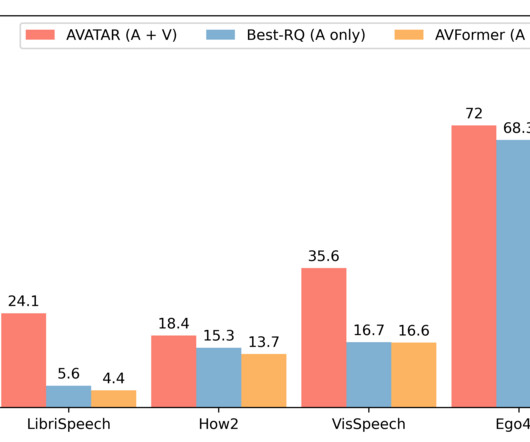
The resulting AVFormer model achieves state-of-the-art zero-shot performance on three different AV-ASR benchmarks (How2, VisSpeech and Ego4D ), while also crucially preserving decent performance on traditional audio-only speech recognition benchmarks (i.e., LibriSpeech ). Unconstrained audiovisual speech recognition.
Different NAS algorithms, such as MNasNet and TuNAS , have been proposed and have discovered several efficient model architectures, including MobileNetV3 , EfficientNet. Problem formulation NAS tackles a variety of different problems on different search spaces. Burgers taste differently with different mixtures of options.
1/4th of Annual Nonprofit Revenue is Raised in December Source: M+R Benchmarks According to the 2023 M+R Benchmarks Report , December giving accounts for roughly one fourth (26%) of annual nonprofit revenue. Fundraising Nonprofit CRM Comparison: The 6 Top CRMs for Nonprofits 10 min read Read Now 8. Get the guide 2.
LRB , LHD , storage applications ), it remains a challenge to outperform robust heuristics in a way that can generalize reliably beyond benchmarks to production settings, while maintaining competitive compute and memory overheads. Each cache server runs in a potentially different environment (e.g.,
You can download the complete report here , and don''t forget the companion online benchmarking tool , where you can compare some of your organization''s data against your peers in our research. In our latest survey, we decided to ask about technology staffing levels differently.
Each type dictates a different process and therefore requires different measurement and analysis methods. Knowing what work you need done and the quality of work you’d like to receive and set benchmarks to measure outcomes. Of all the three different types of crowdsourcing, measuring action can be the most straightforward.
Memory construction from multimodal knowledge corpora Our approach is similar to REALM in that we precompute key and value embeddings of knowledge items from different sources and index them in a unified knowledge memory, where each knowledge item is encoded into a key-value pair. GPT-3) as an implicit source of knowledge.
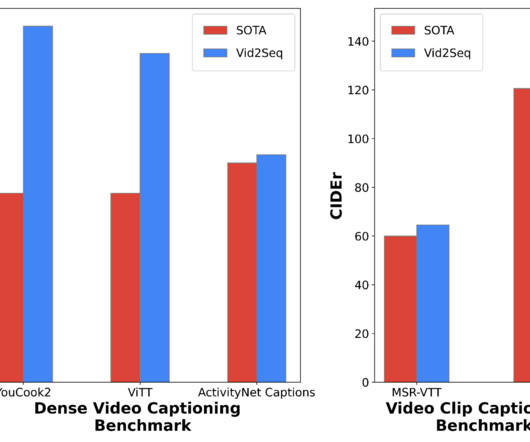
Understanding the content of videos, however, is a challenging task as videos often contain multiple events occurring at different time scales. This differs from single image captioning and standard video captioning , which consists of describing short videos with a single sentence. Learn more from the paper and grab the code here.
When you send a fundraising email can be the difference between improved engagement metrics (open rate, click-through rate, donation amount, etc.) Even with some adjustments for different time zones, this data shows us that nonprofits across the board typically send their emails in the late morning and early afternoon.
There’s also a hint that its new A15 Bionic processor might be downclocked in comparison to the version that appears in the iPhone 13 line ( via MacRumors ). The GeekBench benchmarks MacRumors cites points to the Mini’s performance coming in at 2.9 Maybe not a huge loss for the Mini just yet. GHz , a bit slower than the 3.2
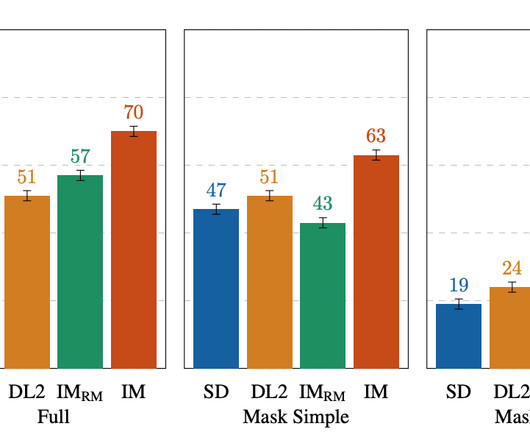
To provide insight into the relative strengths and weaknesses of different models, EditBench prompts are designed to test fine-grained details along three categories: (1) attributes (e.g., For the rest, the performance order is IM-RM > DL2 > SD (with 3–6% difference) except for with Mask Simple, where IM-RM falls 4-8% behind.
Taking into account the difference in storage costs in 2002, Schippers estimates that Zuckerberg was spending $3,000 per month on hosting for the first year and about $10 million per month by 2006 as the network grew exponentially in that time period. Then Google and Benchmark pumped $258 million more into it this past August.
Thanking donors individually on Facebook and including the link to the fundraiser triggered donations based on comparison of time posted and donation made, second most effective solicitation was a personal ask via private message. Set A Realistic Goal Based On Benchmarking. Think About Different Levels of Influence.
A baseline is a measurement that you can use as a comparison to measure progress against a goal or do before/after comparisons. Chris suggests: Before you start the clock it is a good idea to benchmark where you’re at. Make a note of ROI benchmarks. Make a note of the obvious numb ers.
I’ve spent the past week with the Core i9-12900K running on both Windows 10 and Windows 11, and there’s barely a difference between the two for gaming. I’ve tested a variety of workloads, synthetic benchmarks, and games across both Windows 10 and Windows 11, and the results are very similar. We’re now at the stage where just using M.2
Comparison of four prompting methods, (a) Standard, (b) Chain of thought (CoT, Reason Only), (c) Act-only, and (d) ReAct, solving a HotpotQA question. Scaling results for prompting and fine-tuning on HotPotQA with ReAct and different baselines. In-context examples are omitted, and only the task trajectory is shown.
This is the number you can use to compare the relative robustness of your messaging program with the results reported by the " eNonprofit Benchmarks Study " (or Convio's " Online Nonprofit Benchmarks Study " or MailChimp's " Email Marketing Benchmarks by Industry ", or.). What was different about those messages?
In the meantime, here are my benchmark results to give you an idea of the frame rates you can expect from this chip on a few different games. The 6800M also clearly has a large amount of raw power, even if it doesn’t translate to every game: it also beat all of these systems on the 3DMark Time Spy benchmark. to $1,699.99
However, comparison is inevitable, and Chinese companies focusing on AI products have always benchmarked their products against OpenAI’s models. Such comparisons have often drawn scorn on Chinese social media, with Baidu itself often suffering in comparison to ChatGPTs innovative progress.
If you’re switching over from an older iPad, though, be aware that the cable is different. Other than the new colors, there are really only two exterior differences between the Pro and the Air, both of them subtle. However, the comparison isn’t apples-to-apples (pardon the pun). Geekbench 5 Pro compute benchmark results.
To me, you don’t include a “pro” model on day one unless you are very confident in the benchmarks and performance. Apple is surely going to tout some impressive benchmarks for these Macs. The difference, though, is that fewer Mac apps are likely to use the right kind of code to get the most out of whatever Apple puts in these Macs.
Meanwhile, the average order value per shopping cart is $350, less than a third of the benchmark — typically $750 to $1,500 — recorded by widely used luxury e-commerce stores, according to Rufai. Customers are warming up to our platform, and selling luxury online is a different ball game.
Performance comparison between the PaLM 540B parameter model and the prior state-of-the-art (SOTA) on 58 tasks from the Big-bench suite. This approach generally yields high performance on tasks for which we have learned soft prompts, while allowing the large pre-trained language model to be shared across thousands of different tasks.
Models at this scale necessitate “sharding” — distributing the model parameters in different compute devices. The goal is to compute the matrix multiplication y = Ax, but both the matrix A and activation x are distributed across different devices. How different are human and model accuracies (accuracy difference)?
The Verge doesn’t typically review processors, so we don’t own dedicated hardware testing rigs or multiple CPUs and systems to offer all of the benchmarks and comparisons you’d typically find in CPU reviews. Averages during a particular benchmark don’t always tell the whole story, though. Intel’s Core i9-11900K processor.
Here’s a comparison between reading the data without and with thepyarrow backend, using the Hacker News dataset, which is around 650 MB (License CC BY-NC-SA 4.0 ): [link] As you can see, using the new backend makes reading the data nearly 35x faster. So, long story short, PyArrow takes care of our previous memory constraints of versions 1.X
That said, we recognize there will be exceptions: partners for whom advanced data-sharing may prompt a higher level of scrutiny who aren’t to be trusted with this level of data sharing (TikTok, Meta), and organizations whose specific data policies differ from their peers (e.g. All are possibilities depending on who you are working with.
Although prior work has demonstrated the benefits of ML in design optimization, the lack of strong, reproducible baselines hinders fair and objective comparison across different methods and poses several challenges to their deployment. To ensure steady progress, it is imperative to understand and tackle these challenges collectively.
An algorithm’s performance over T rounds is compared against the best fixed action in hindsight by means of the regret (the difference between the reward of the best arm and the reward obtained by the algorithm over all T rounds). An instance of the experts problem. An example in which our algorithm outperforms a UCB based baseline.
This could include noting different points of data exploration, such as filtering data views or comparing specific charts. Also, use consistent design elements to provide a sense of predictability across different charts. Industry benchmarks and comparisons: Consider the larger trends at play that impact your results.
Real Conversation test set Unprompted or conversational speech differs from prompted speech in several ways. To improve a model for this use case, we created the Real Conversation test set to benchmark performance. In conversation, people speak faster and enunciate less. quite a while now i've been talking for quite a while now.
We also use the median for our comparisons, so that one outlier doesn’t skew the whole set. One notable difference when looking at Giving Tuesday year to year is when these emails are sent: every group in our sample sent at least one email before the special day, with groups sending as many as three pre-Giving Tuesday emails.
The guide includes a comparison of 29 different systems and offers detailed reviews of 10 of the most popular. Idealware’s report explores the essential features of nonprofit CRMs and donor management systems and makes recommendations based on specific needs.
Is there a discernible difference in nonprofit focus based on location? The more folks who participate, the better the results and comparisons are, thanks to the abundance of data. What is the age of your organization? Is it location or focus, or both, that affects grant dollars? Is there a "peak" age for nonprofits?
In this blog we take a technical deep dive into the cost and performance of their serverless SQL warehouse product by utilizing the industry standard TPC-DI benchmark. Before we dive into a specific product, let’s take a step back and look at the different options available today. What are Databricks’ SQL warehouse offerings?
Published on March 12, 2025 5:56 PM GMT Summary The Stages-Oversight benchmark from the Situational Awareness Dataset tests whether large language models (LLMs) can distinguish between evaluation prompts (such as benchmark questions) and deployment prompts (real-world user inputs).
Reliable, recent data for some countries remains patchy, but the International Communications Union estimates that there are probably closer to 3 billion global internet users, with most of the difference made up by mobile-only connections. Benchmark Studies and Examples.
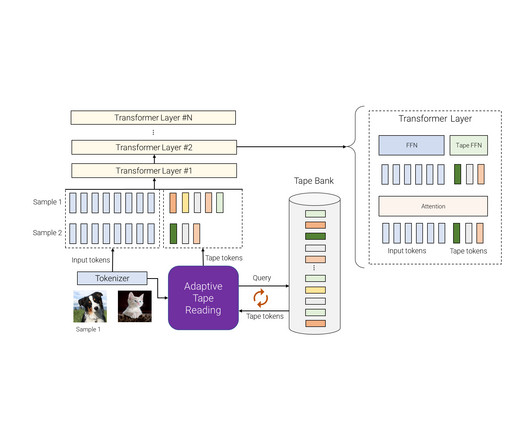
While conventional neural networks have a fixed function and computation capacity, i.e., they spend the same number of FLOPs for processing different inputs, a model with adaptive and dynamic computation modulates the computational budget it dedicates to processing each input, depending on the complexity of the input.
We organize all of the trending information in your field so you don't have to. Join 12,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content