This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Built-in speakers just dont cut it when you want room-filling audio for movies, gaming or even just hearing dialogue clearly. Thats where a good soundbar comes in an easy space-saving way to dramatically improve your TVs audio without the hassle of a full home theater system. One company I would keep an eye on is Sennheiser.
Whether you're listening to playlists on your daily commute or zoning out with a podcast at home, wireless headphones can make your audio experience much more comfortable. Sure, you can find on-ear models with ANC, but over-ear designs are much more effective at blocking sound. Do you prefer on-ear or over-ear headphones?
The new model is known as Fugatto, which is short for Foundational Generative Audio Transformer Opus 1. For example, Fugatto can create a tune based solely on text, change the emotion in a singer's voice or modify their accent, and even add or. According to Nvidia, its capabilities are unparalleled. Read Entire Article
You’ll need to prick up your ears for this slice of deepfakery emerging from the wacky world of synthesized media: A digital version of Albert Einstein — with a synthesized voice that’s been (re)created using AI voice cloning technology drawing on audio recordings of the famous scientist’s actual voice.
This model still rivals newer releases and usually goes for $348, so yes, this 48% price cut got me clicking “Add to Cart” faster than I’d like to admit. With five microphones and some serious audio magic, your voice comes through clearly without you needing to shout like you're reporting live from a storm.
Announced at the CES trade show in January, NVIDIA NIM provides prepackaged, state-of-the-art AI models optimized for the NVIDIA RTX platform, including the NVIDIA GeForce RTX 50 Series and, now, the new NVIDIA Blackwell RTX PRO GPUs. 8B-instruct Image Generation: Flux.dev Audio: Riva Parakeet-ctc-0.6B-asr
TL;DR: Enjoy access to multiple AI models in one easy spot with 1min.AI , now only $79.97 This handy platform combines several popular AI models — including ChatGPT, Gemini, and Midjourney — into one app, letting you test out their unique features without hopping between services. 540) through April 30. is a great tool.
Microsoft's voice AI tool, called Vall-E, is trained on "discrete codes derived from an off-the-shelf neural audio codec model" as well as 60,000 hours of speech—100 times more than existing systems—from more than 7,000 speakers, most of which come from LibriVox public domain audiobooks.
“Voice skins” have become a very popular feature for AI-based voice assistants, to help personalize some of the more anodyne aspects of helpful, yet also kind of bland and robotic, speaking voices you get on services like Alexa. Our goal is to be a global leader in providing AI voices that touches people’s hearts and emotions.
." Say hello to GPT-4o, our new flagship model which can reason across audio, vision, and text in real time: [link] Text and image input rolling out today in API and ChatGPT with voice and video in the coming weeks. The "o" stands for "omni", which is a reference to the models multimodal capabilities.
Posted by Zalán Borsos, Research Software Engineer, and Marco Tagliasacchi, Senior Staff Research Scientist, Google Research The recent progress in generative AI unlocked the possibility of creating new content in several different domains, including text, vision and audio. In the case of audio, neural audio codecs (e.g.,
London and Barcelona based audio-as-a-service SaaS startup Aflorithmic has scooped up $1.3 “Text in beautiful audio out” is its pithy slogan. . “Text in beautiful audio out” is its pithy slogan. Elon Musk busts Clubhouse limit, fans stream to YouTube, he switches to interviewing Robinhood CEO.
This tiny porcelain box delivers fast, customizable streaming with support for 4K HDR, Dolby Vision, and even Dolby Atmos audio if you’ve got the right speakers. It’s got voice search, a customizable button, and a way to make the remote ring when it disappears into the couch cushions. And it does it fast.
The introduction of voice has already started happening in several mobile apps, and presents a tremendous opportunity for developers. This indeed seems like a paradox, as a few years ago text messages and apps had brought down voice revenues for operators. But now, voice presents a plethora of opportunities for these apps.
The new Nest Audio sits between the Nest Mini and Home Max in price, size, and output. Despite that lower price, the Nest Audio is an improvement over the Google Home in nearly every way. It’s faster to respond to voice commands, and most importantly, it sounds a lot better than the Google Home ever could.
Startup Adthos this week launched a platform that uses AI to generate scripts for audio ads — and even add voiceovers, sound effects and music. To generate ad scripts, Adthos leverages OpenAI’s recently released GPT-4 text-producing model. “We use real-life voice actors for the training of synthetic voices. .
Deepgram, a company developing voice-recognition tech for the enterprise, today raised $47 million in new funding led by Madrona Venture Group with participation from Citi Ventures and Alkeon. ” Launched in 2015, Deepgram focuses on building custom voice-recognition solutions for customers such as Spotify, Auth0 and even NASA.
SEE ALSO: The best Apple deals in Amazon's Big Spring Sale: New iPads and M4 MacBook Airs are already on sale Voice calls come through crisp thanks to multiple built-in mics, and the foldable design with included carrying case makes them easy to travel with (and show off).
I will begin with a discussion of language, computer vision, multi-modal models, and generative machine learning models. Language Models The progress on larger and more powerful language models has been one of the most exciting areas of machine learning (ML) research over the last decade. Let’s get started!
If meme stocks can be a thing, what’s to stop audio meme sharing from going viral!? It’s not hard to predict where this idea goes: Straight to gross out fart sfx and pwning troll clips — which are indeed plentiful on this fledgling platform for user-generated (or, well, sampled) audio. Dank audio memes anyone?
The growing ease with which anyone can create convincing audio in someone else’s voice has a lot of people on edge , and rightly so. AI-generated speech is being used for all kinds of legitimate purposes, from screen readers to replacing voice actors (with their permission, of course). Encode the audio for streaming?
You might think that Clubhouse is the final word on audio-centric social networks, but a San Francisco startup called Swell is launching its own iOS and Android app focused on voice conversations. Audio is hardly immune to ranting and anger — just look at talk radio. Will audio livestreaming take off in America?
Some standalone webcam models let you manually adjust focus, too, if you have specific needs. Check to see if the model youre considering has mono or stereo mics, as the latter is better. Some even use noise-reduction technology to keep your voice loud and clear. This article originally appeared on Engadget at [link]
Highnote launched to the public today, allowing musicians, podcasters, and other creators to collaborate on audio files by recording voice notes directly over a track, making timestamped reactions, and creating polls to get opinions. Highnote also announced its pre-seed funding round of $1.7 Highnote changes that.”.
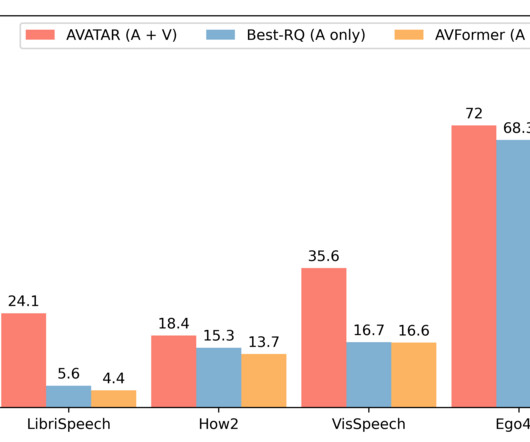
Posted by Arsha Nagrani and Paul Hongsuck Seo, Research Scientists, Google Research Automatic speech recognition (ASR) is a well-established technology that is widely adopted for various applications such as conference calls, streamed video transcription and voice commands. LibriSpeech ).
Samsung Samsungs Ballie will go on sale in the US and South Korea this summer and will now pack Googles Gemini AI model. Having said that, we dont know what kind of OS is running on the device, but it will process voice, audio and visual data. And struggle. with stairs. Engadget In the market for a drone?
based AI startup that has developed speech technology that translates people’s voices into other languages and is already being used in the video and television industry, has raised £8 million in funding. Most of the world’s video and audio content is shackled to a single language,” says Papercup co-founder and CEO Shemen.
The Promise of Generative AI Generative AI refers to deep-learning models capable of generating human-like outputs, including text, images, video, and audio. In so doing, is generative AI inadvertently reducing the voices of many to the banality of one? Examples include ChatGPT, Dall-E, and DeepSeek.
Stability AI , the startup behind the generative AI art tool Stable Diffusion , today open-sourced a suite of text-generating AI models intended to go head to head with systems like OpenAI’s GPT-4. make up) facts. “This is expected to be improved with scale, better data, community feedback and optimization.”
The AirPods 4 have Apple’s H2 chip, which is the same one in the Pro model, and that brings serious upgrades to clarity and performance. Calls are clearer thanks to voice isolation, and music sounds richer without having to mess with EQ settings. I’m into Personalized Spatial Audio too.
Use your voice: If talking jogs your memory, use conversation mode in ChatGPT , Claude , Googles Gemini , or Microsofts CoPilot. Experimental Advanced, Googles newest model, was an excellent voice partner in analyzing my current reading interests. For long book lists or extensive highlights, use a pro model for nuanced analysis.
The Pro model is also on sale, down to $320 from $400. General audio quality has been improved as well, and they have a comfy fit. There's also Alexa support built into the remote, so you can use voice commands to search for content. They support wired USB-C audio, plus they have solid ANC as well.
Anyway, in between mashed potato servings, I did my best to “log off” and not think about audio — no offense — so instead, I binged the entire new season of Selling Sunset and played many crosswords. EXCLUSIVE: Hinge makes viral audio happen, despite many other apps trying. 46 percent of users have played a voice prompt.
Nearly a year after Adobe first teased video AI features , the company is finally bringing its new video AI model to market. Today, the company is launching its Firefly Video Model in public beta. Image: Adobe] What is Adobes new Firefly video model? What can it do?
Amazon is working on a new feature for its Alexa voice assistant that will let the software launch Android and iOS apps using voice commands, a first for Amazon’s assistant and a bold expansion of its strategy to position Alexa as a platform-agnostic alternative to Apple’s Siri and Google Assistant.
Synthetic speech tech startup Murf gives a voice, literally, to content creators of all sizes. Murf, which now has a library of more than 120 human-parity AI voices across 20 languages, announced today it has raised $10 million Series A funding led by Matrix partners. Murf’s founders.
From premium options like the AirPods Pro 2, which combine sleek design with impressive active noise cancellation, to models that prioritize exceptional sound quality, theres a pair of Bluetooth earbuds for everyone. Some earbuds even offer app settings to tweak the audio profiles or firmware updates to improve performance over time.
Building usable models to run AI algorithms requires not just adequate data to train systems, but also the right hardware subsequently to run them. But because the theoretical and practical are often not the same thing, there is often a gap between what data scientists may hope to do and what they practically do.
“The primary intended users of [the Whisper] models are AI researchers studying robustness, generalization, capabilities, biases and constraints of the current model. “[The models] show strong ASR results in ~10 languages. “[The models] show strong ASR results in ~10 languages.
VentureBeat reports that Google has been working on the feature for around a year and a half, using thousands of its own meetings to train its AI model. However, unlike a solution such as Nvidia’s RTX Voice software , Google’s processing happens in the cloud, meaning it can work consistently on a much broader range of hardware.
All staff voices are respected and a sense of belonging. Leaders can leverage the hybrid meeting model to change this by looking around the table and making sure all voices are seen and heard, whether participating on-screen or in-person. 50-50 Time Split: This model allows staff to work from home half the time.
AudioQuest’s Dragonfly portable digital-to-analog converter (DAC) brings higher-quality audio to your devices. AudioQuest makes three separate models : the basic Dragonfly Black; the Dragonfly Red, which uses a higher-performance DAC chip; and the Dragonfly Cobalt, its highest-end model. Andrew Marino, audio engineer.
We organize all of the trending information in your field so you don't have to. Join 12,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content