This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Pinterest has updated itsprivacy policy to reflect its use of platform user data and images to train AItools. In the update, Pinterest claims its goal in training AI is to "improve the products and services of our family of companies and offer new features." Later, the company provided us with an emailed statement.
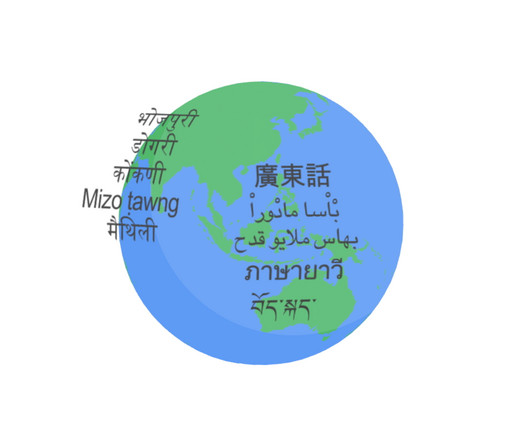
Posted by Yu Zhang, Research Scientist, and James Qin, Software Engineer, Google Research Last November, we announced the 1,000 Languages Initiative , an ambitious commitment to build a machine learning (ML) model that would support the world’s one thousand most-spoken languages, bringing greater inclusion to billions of people around the globe.
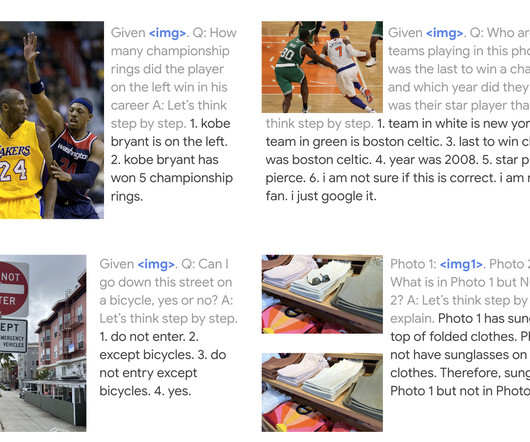
Posted by Ziniu Hu, Student Researcher, and Alireza Fathi, Research Scientist, Google Research, Perception Team Large-scale models, such as T5 , GPT-3 , PaLM , Flamingo and PaLI , have demonstrated the ability to store substantial amounts of knowledge when scaled to tens of billions of parameters and trained on large text and image datasets.
Posted by Danny Driess, Student Researcher, and Pete Florence, Research Scientist, Robotics at Google Recent years have seen tremendous advances across machine learning domains, from models that can explain jokes or answer visual questions in a variety of languages to those that can produce images based on text descriptions.
Transform modalities, or translate the world’s information into any language. I will begin with a discussion of language, computer vision, multi-modal models, and generative machine learning models. We want to solve complex mathematical or scientific problems. Diagnose complex diseases, or understand the physical world.
Previously, the stunning intelligence gains that led to chatbots such ChatGPT and Claude had come from supersizing models and the data and computing power used to train them. The big AI labs would now need even more of the Nvidia GPUs theyd been using for training to support all the real-time reasoning their models would be doing.
Additionally, nonprofits can create their own custom-trained GPT chatbot with their custom data. This enables the creation of a tailor-made AI assistant, specifically trained to understand and address your nonprofit’s unique needs. Fortunately, you don’t need to learn coding or a new language.
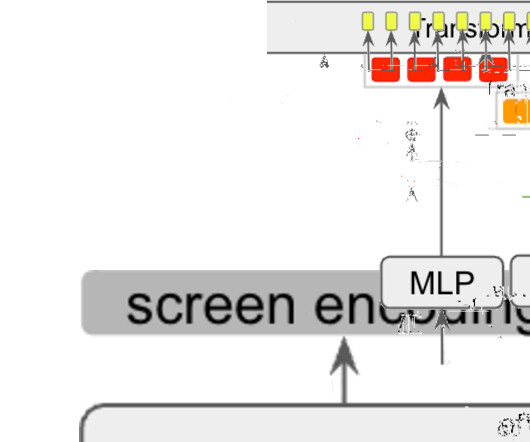
In “ Spotlight: Mobile UI Understanding using Vision-Language Models with a Focus ”, accepted for publication at ICLR 2023 , we present a vision-only approach that aims to achieve general UI understanding completely from raw pixels. Spotlight drastically exceeded the state-of-the-art across four UI modeling tasks. Tappability - - - 87.9
1) Master the art of Plain Language. . Plain language is communication your audience can understand the first time they read or hear it. The Plain Language Movement started in the 1970s based on the idea to make it easier for the public to read, understand, and use government communications. Plain language is concise.
That light-hearted description probably isn’t worthy of the significance of this advanced language technology’s entrance into the public market. It’s built on a neural network architecture known as a transformer, which enables it to handle complex natural language tasks effectively.
To begin on a lighthearted note: The ways researchers find to apply machine learning to the arts are always interesting — though not always practical. Audeo , the system trained by Eli Shlizerman, Kun Su and Xiulong Liu, watches video of piano playing and first extracts a piano-roll-like simple sequence of key presses. .
Many of these people have their work taken, either as training material for the large-language model scraped from the internet or improperly taken and modified by ChatGPT users, without any credit or compensation. One of the more visible examples have been the many memes image inspired by the animation style of Studio Ghibli.
Stability AI , the startup behind the generative AI art tool Stable Diffusion , today open-sourced a suite of text-generating AI models intended to go head to head with systems like OpenAI’s GPT-4. But Stability AI claims it created a custom training set that expands the size of the standard Pile by 3x. make up) facts.
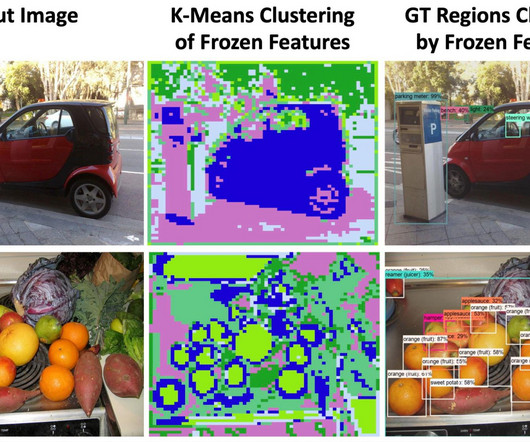
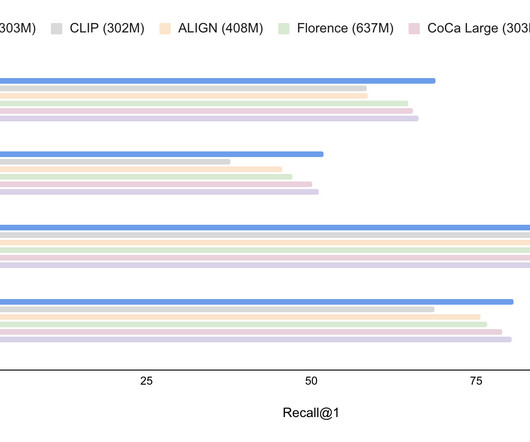
Recent vision and language models (VLMs), such as CLIP , have demonstrated improved open-vocabulary visual recognition capabilities through learning from Internet-scale image-text pairs. We explore the potential of frozen vision and language features for open-vocabulary detection.
million books, to train its AI models. A lawsuit in the US alleges Meta CEO Mark Zuckerberg approved the use of LibGen's data to train its AI. It reported that Meta had used LibGen, a pirated collection of over 7.5 The lawsuit's plaintiffs include writers Sarah Silverman and Ta-Nehisi Coates.
The heated race to develop and deploy new large language models and AI products has seen innovation surgeand revenue soarat companies supporting AI infrastructure. Lambda Labs new 1-Click service provides on-demand, self-serve GPU clusters for large-scale model training without long-term contracts. billion, a 33.9% increase over 2023.
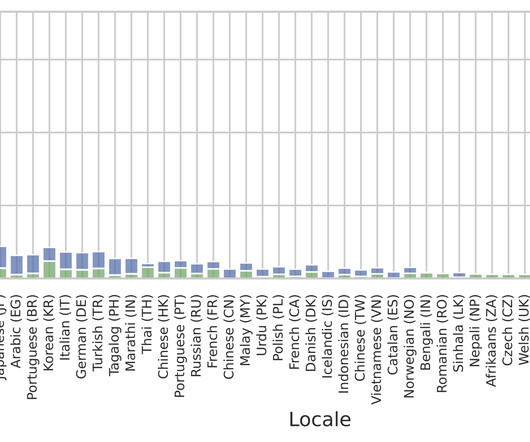
Posted by Thibault Sellam, Research Scientist, Google Previously, we presented the 1,000 languages initiative and the Universal Speech Model with the goal of making speech and language technologies available to billions of users around the world. a localized variant of a language, such as "Brazilian Portuguese" or "British English").
Home About Me Subscribe Zen and the Art of Nonprofit Technology Thoughtful and sometimes snarky perspectives on nonprofit technology The language we use September 6, 2006 I came across, in my catching up period, an article titled " Ten ways to change the world with Web 2.0 Are there actually really any fewer homeless people?
Posted by Shunyu Yao, Student Researcher, and Yuan Cao, Research Scientist, Google Research, Brain Team Recent advances have expanded the applicability of language models (LM) to downstream tasks. On the other hand, recent work uses pre-trainedlanguage models for planning and acting in various interactive environments (e.g.,
AI can be trained to mimic its programmer’s values, but it is unable to independently distinguish right from wrong or good from evil. Make appropriate training available. The cost of online training from providers like Coursera, Udemy, Udacity, and edX, ranges from approximately $10 to about $500 per course.
The Art of Timing Because AI can analyze vast amounts of data very quickly, it excels at identifying patterns that people might miss. Train your AI tool. In the same vein, you can train your AI tools with information specific to your organization. Use this ability to learn to your advantage. Don’t use AI for everything.
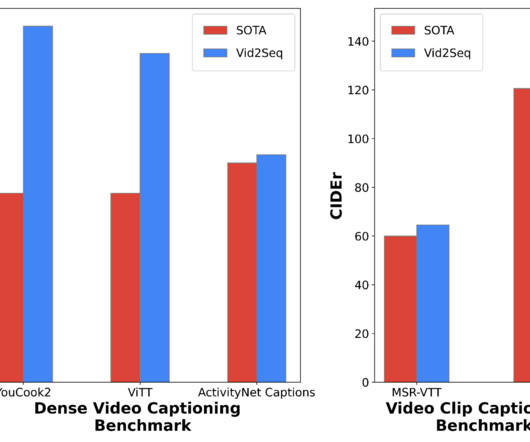
Furthermore, they are often trained exclusively on manually annotated datasets, which are very difficult to obtain and hence are not a scalable solution. In this post, we introduce “ Vid2Seq: Large-Scale Pretraining of a Visual Language Model for Dense Video Captioning ”, to appear at CVPR 2023.
Anyspheres Cursor tool, for example, helped advance the genre from simply completing lines or sections of code to building whole software functions based on the plain language input of a human developer. Or the developer can explain a new feature or function in plain language and the AI will code a prototype of it.
Anthropic , a startup that hopes to raise $5 billion over the next four years to train powerful text-generating AI systems like OpenAI’s ChatGPT , today peeled back the curtain on its approach to creating those systems. Because it’s often trained on questionable internet sources (e.g. So what are these principles, exactly?
Humanoid robots capable of tasks like folding laundry have been a longtime dream, but the state-of-the-art falls wildly short of human level. Fast AI progress, slow robotics progress If youve heard of OpenAI, youve heard of its language models: GPTs 1, 2, 3, 3.5, 4, and most recently 4.5.
Speak , an English language learning platform with AI-powered features, today announced that it raised $27 million in a Series B funding round led by the OpenAI Startup Fund , with participation from Lachy Groom, Josh Buckley, Justin Mateen, Gokul Rajaram and Founders Fund. ” Image Credits: Speak. ” Zwick added.
They said transformer models , large language models (LLMs), vision language models (VLMs) and other neural networks still being built are part of an important new category they dubbed foundation models. Language models have a wide range of beneficial applications for society, the researchers wrote.
Language generation is the hottest thing in AI right now, with a class of systems known as “large language models” (or LLMs) being used for everything from improving Google’s search engine to creating text-based fantasy games. Not all problems with AI language systems can be solved with scale.
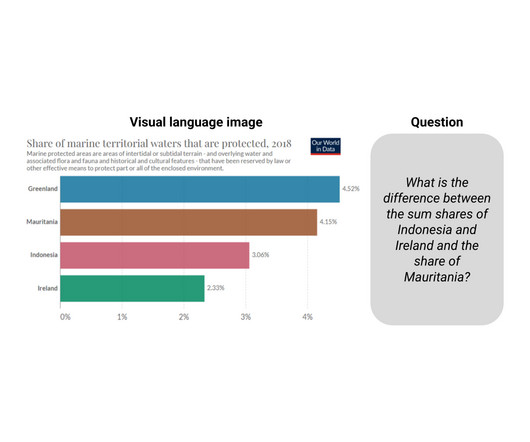
Posted by Julian Eisenschlos, Research Software Engineer, Google Research Visual language is the form of communication that relies on pictorial symbols outside of text to convey information. However, visual language has not garnered a similar level of attention, possibly because of the lack of large-scale training sets in this space.
Don’t worry, Duo the owl isn’t going anywhere Language app Duolingo is unveiling a new cast of characters that it hopes will help users better learn new languages, even during the toughest lessons. The nine characters of Duolingo Project World all have unique personalities, and serve as guides to make a new language feel more familiar.
" In any event, the gravy train has run out of steam. We dont have any actual monetary figures, but the videos have racked up billions of views. Maybe thats enough for short-sighted companies. The actors union SAG-AFTRA has called the whole thing a "race to the bottom."
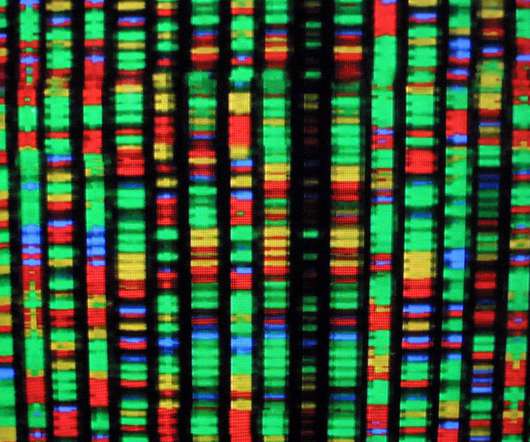
A new algorithm, Evo 2, trained on roughly 128,000 genomes9.3 Evo marks a key moment in the emerging field of generative biology because machines can now read, write, and think in the language of DNA, said study author Patrick Hsu in an Arc Institute blog. The team explicitly included these regions in Evo 2s training.
Posted by Fabian Pedregosa and Eleni Triantafillou, Research Scientists, Google Deep learning has recently driven tremendous progress in a wide array of applications, ranging from realistic image generation and impressive retrieval systems to language models that can hold human-like conversations.
Bringing the capabilities of LLMs to robotics An incredible feature of large language models (LLMs) is their ability to encode descriptions and context into a format that’s understandable by both people and machines. When applied to robotics, LLMs let people task robots more easily — just by asking — with natural language.
AI research company OpenAI is releasing a new machine learning tool that translates the English language into code. In demos of Codex, OpenAI shows how the software can be used to build simple websites and rudimentary games using natural language, as well as translate between different programming languages and tackle data science queries.
Supports multiple locations or chapters, multiple currencies, multiple languages, and multiple character sets. Finally, the system needs to be backed by strong implementation practices, training, and ongoing product development and user support. Has an open API and flexible import and export tools.
Posted by AJ Piergiovanni and Anelia Angelova, Research Scientists, Google Research Vision-language foundational models are built on the premise of a single pre-training followed by subsequent adaptation to multiple downstream tasks. In line with recent language models (e.g.,
Posted by Jason Wei and Yi Tay, Research Scientists, Google Research, Brain Team In recent years, language models (LMs) have become more prominent in natural language processing (NLP) research and are also becoming increasingly impactful in practice. Scaling up LMs has been shown to improve performance across a range of NLP tasks.
However, modern object detectors are limited by the manual annotations of their training data, resulting in a vocabulary size significantly smaller than the vast array of objects encountered in reality. Thus, it could be beneficial for open-vocabulary detection if we build locality information into the image-text pre-training.
Posted by Piotr Padlewski and Josip Djolonga, Software Engineers, Google Research Large Language Models (LLMs) like PaLM or GPT-3 showed that scaling transformers to hundreds of billions of parameters improves performance and unlocks emergent abilities. This approach was used in PaLM and reduced training time by 15%.
Language Model Pretraining Language models (LMs), like BERT 1 and the GPT series 2 , achieve remarkable performance on many natural language processing (NLP) tasks. That is, one would split a text corpus into a list of documents and draw training instances for LMs from each document independently. 6 Challenges.
. “ Stability looks to develop and democratize AI, and through OpenBioML, we see an opportunity to advance the state of the art in sciences, health and medicine.” Its first projects are: BioLM , which seeks to apply natural language processing (NLP) techniques to the fields of computational biology and chemistry.
Earlier this month I was in Boston for the annual convention for Americans for the Arts where I facilitated a leadership development pre-conference workshop, “Impact without Burnout: Resilient Arts Leaders from the Inside/Out.” The first session focused on self-awareness skills.
Very general and vague words can generate very vague responses and language. In fact, generative AI has been known to be trained on biased information. Giving ChatGPT the prompt “Tell me why arts are important for youth development” generates two pages of text. Is it grammatically correct? Is it accurate? Is it up to date?
We organize all of the trending information in your field so you don't have to. Join 12,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content