This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
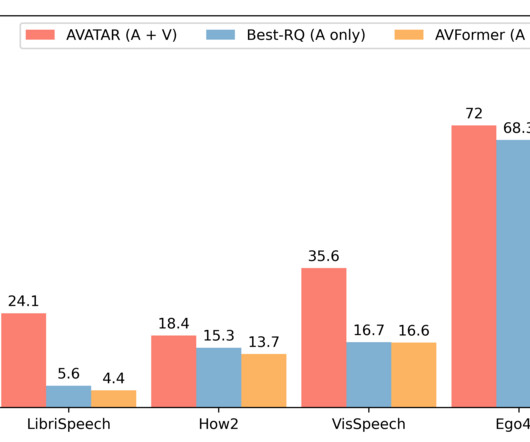
The resulting AVFormer model achieves state-of-the-art zero-shot performance on three different AV-ASR benchmarks (How2, VisSpeech and Ego4D ), while also crucially preserving decent performance on traditional audio-only speech recognition benchmarks (i.e., LibriSpeech ). Unconstrained audiovisual speech recognition.
Using data-centric approaches, we show state-of-the-art results in both. In “ SPADE: Semi-supervised Anomaly Detection under Distribution Mismatch ”, we propose a novel semi-supervised AD framework that yields robust performance even under distribution mismatch with limited labeled samples. We consider methods with both shallow (e.g.,
In light of these challenges, we propose “ MatCha: Enhancing Visual Language Pretraining with Math Reasoning and Chart Derendering ”. We also propose “ DePlot: One-shot visual language reasoning by plot-to-table translation ”, a model built on top of MatCha for one-shot reasoning on charts via translation to tables.
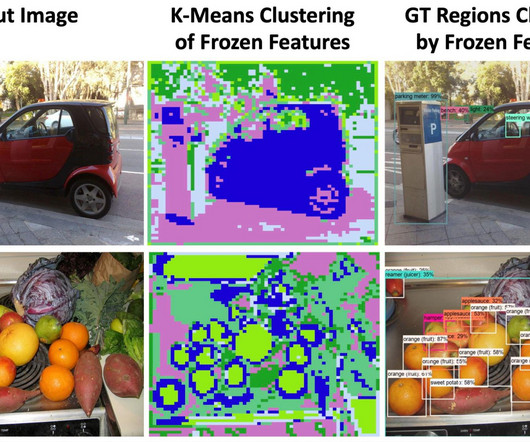
Various techniques such as image-text pre-training , knowledge distillation , pseudo labeling , and frozen models, often employing convolutional neural network (CNN) backbones, have been proposed. To address this, we propose cropped positional embeddings (CPE). We are also releasing the code here.
We proposed a theoretical architecture that would “remember events” in the form of sketches stored in an external LSH table with pointers to modules that process such sketches. We have proposed a new constrained optimization algorithm for automating hyperparameter tuning. T5-Large models have <1% nonzero entries.
A number of neural network–based solutions have been able to show good performance on benchmarks and also support the above criterion. However, other work has suggested that even linear models can outperform these transformer variants on time-series benchmarks. Left: MSE on the test set of a popular traffic forecasting benchmark.
We demonstrate that this model is scalable, can be adapted to large pre-trained ViTs without requiring full fine-tuning, and achieves state-of-the-art results across many video classification benchmarks. Importantly, it outperforms all state-of-the-art methods trained jointly on image+video datasets.
At test time, F-VLM uses the region proposals to crop out the top-level features of the VLM backbone and compute the VLM score per region. Evaluation We apply F-VLM to the popular LVIS open-vocabulary detection benchmark. average precision (AP) on rare categories ( APr ), which outperforms the state of the art by 6.5
In 2022, we continued this journey, and advanced the state-of-the-art in several related areas. We also proposed a new hybrid architecture to overcome the depth requirements of existing GNNs for solving fundamental graph problems, such as shortest paths and the minimum spanning tree. closures, incidents).
While large language models (LLMs) are now beating state-of-the-art approaches in many natural language processing benchmarks, they are typically trained to output the next best response, rather than planning ahead, which is required for multi-turn interactions.
We show that state-of-the-art SFDA methods can underperform or even collapse when confronted with realistic distribution shifts in bioacoustics. Furthermore, existing methods perform differently relative to each other than observed in vision benchmarks, and surprisingly, sometimes perform worse than no adaptation at all.
Here’s an example of 25 SMART social media objectives from arts organizations. Benchmarking comparing your organization’s past performance to itself or doing a formal or informal analysis of peer organizations can help. It also helps to break down your goal into monthly or quarterly benchmarks.
For example, we are combining regulatory expertise with a state-of-the-art B2B customer experience including merchant ads, benchmarking and business intelligence and many other future features.”.
Different NAS algorithms, such as MNasNet and TuNAS , have been proposed and have discovered several efficient model architectures, including MobileNetV3 , EfficientNet. better than current state-of-the-art alternatives. Problem formulation NAS tackles a variety of different problems on different search spaces.
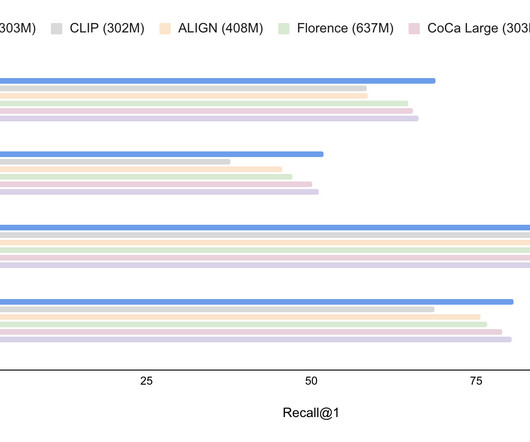
While modest in size, our model outperforms the state of the art or achieves competitive performance on image-text and text-image retrieval , video question answering (VideoQA), video captioning , open-vocabulary detection , and VQA. The results on VQA are competitive with state-of-the-art results, which are achieved by much larger models.
Performance comparison between the PaLM 540B parameter model and the prior state-of-the-art (SOTA) on 58 tasks from the Big-bench suite. Published state-of-the-art 6.9% Minerva 540B significantly improves state-of-the-art performance on STEM evaluation datasets. See paper for details.)
We propose periodic feature similarity that explicitly defines how to measure similarity in the context of periodic learning. To explicitly define how to measure similarity in the context of periodic learning, SimPer proposes periodic feature similarity. This construction allows us to formulate training as a contrastive learning task.
These models achieve state-of-the-art results on downstream tasks, such as image captioning, visual question answering and open vocabulary recognition. Therefore, we propose to use the Perceiver architecture to encode and compress knowledge items. Visual question answering results on A-OKVQA.
In “ ReAct: Synergizing Reasoning and Acting in Language Models ”, we propose a general paradigm that combines reasoning and acting advances to enable language models to solve various language reasoning and decision making tasks. We propose ReAct, a new paradigm that combines reasoning and acting advances in language models.
Mixture-of-experts (MoE), a type of conditional computation where parts of the network are activated on a per-example basis, has been proposed as a way of dramatically increasing model capacity without a proportional increase in computation. Final Thoughts We propose a new routing method for sparsely activated mixture-of-experts models.
Set criteria for contacts, proposals, planning, and forecasting. For example, you may want to measure total visits, the number of proposals submitted, the dollars raised, and first-time or qualification visits. Set portfolio size and distribution standards to level the playing field across teams. Clarify roles and responsibilities.
We propose Hyper BayesOpt (HyperBO), a highly customizable interface with an algorithm that removes the need for quantifying model parameters for Gaussian processes in BayesOpt. Even for experts with relevant experience, it can be challenging to narrow down appropriate model parameters.
This year, we designed state-of-the-art serving techniques for large models , improved automatic partitioning of tensor programs and reworked the APIs of our libraries to make sure all of those developments are accessible to a wide audience of users. PRIME improves performance over state-of-the-art simulation-driven methods by about 1.2x–1.5x
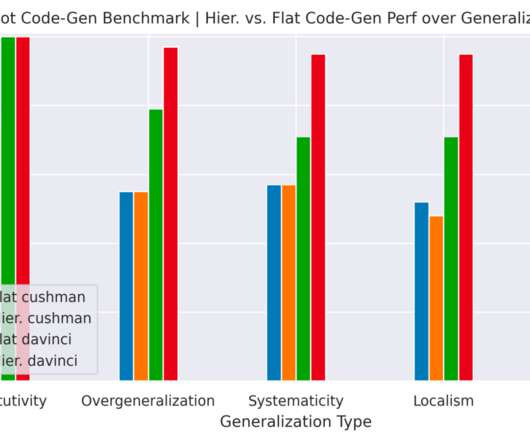
With CaP, we propose using language models to directly write robot code through few-shot prompting. Hierarchical code generation improves state-of-the-art on both robotics as well as standard code-gen benchmarks in natural language processing (NLP) subfields, with 39.8%
Published on February 8, 2025 1:40 AM GMT The Open Philanthropy has just launched a large new Request for Proposals for technical AI safety research. Were interested in more research on this, and other stress tests of todays state-of-the-art alignment methods.
For example, the quintessential benchmark of training a deep RL agent on 50+ Atari 2600 games in ALE for 200M frames (the standard protocol) requires 1,000+ GPU days. Here, we propose an alternative approach to RL research, where prior computational work, such as learned models, policies, logged data, etc.,
2008 was a benchmark year in online fundraising history as Obama won the presidential election with 87% of funds coming through social networking. On the site, social entrepreneurs propose their idea or project, set a funding goal, and identify a “tipping point.” They also jointly run the street art blog StreetSideSF.
Finally, we show that Flan and UL2R can be combined as complementary techniques in a model called Flan-U-PaLM 540B, which outperforms the unadapted PaLM 540B model by 10% across a suite of challenging evaluation benchmarks. Compute versus model performance of PaLM 540B and U-PaLM 540B on 26 NLP benchmarks (listed in Table 8 in the paper ).
such, formative assessments can include: Summarizing the main points of a lecture A weekly quiz to test comprehension Visual art, such as drawing, collages, etc. It measures how much a student has learned by comparing their performance to a standard or benchmark. Summative assessments are often high-stakes.
such, formative assessments can include: Summarizing the main points of a lecture A weekly quiz to test comprehension Visual art, such as drawing, collages, etc. It measures how much a student has learned by comparing their performance to a standard or benchmark. Summative assessments are often high-stakes.
Example: “Datamaking” as engagement I recently worked with an arts and culture intermediary nonprofit that focused on capacity development, network building, and connecting local nonprofits to state agencies and grants. This understanding led me to an approach for “datamaking” that I utilize with groups.
such, formative assessments can include: Summarizing the main points of a lecture A weekly quiz to test comprehension Visual art, such as drawing, collages, etc. It measures how much a student has learned by comparing their performance to a standard or benchmark. Summative assessments are often high-stakes.
About a year ago, I decided to benchmark my blog using some tips suggested by Avinash Kaushik. A year ago, he said that measuring outcomes for social media is, "an evolving art (not quite a science yet) and you have to be up to the challenge of both thinking a bit differently and be ok with leveraging several different tools.
As a conference both for and by the nonprofit technology community, community members submit session proposals and then vote on them to help shape the agenda. Reading through 400+ session proposals made my brain hurt, but at the same time pumped me up. Campaign Case Studies.
So, if you’re going to have an overarching goal, such as improve health or improve the stability of families or anything that’s not considered a SMART criteria, you should be following up with objectives that state, “These are the benchmarks to know that we were successful.” Grant proposals. Ask “So what?”
But education is already largely the domain of states, which set curricula, establish academic standards, and determine teacher certification requirements as well as graduation and testing benchmarks for students. In Philadelphia, Marsena Toney is an autistic support specialist at John Story Jenks Academy for Arts and Sciences.
We organize all of the trending information in your field so you don't have to. Join 12,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





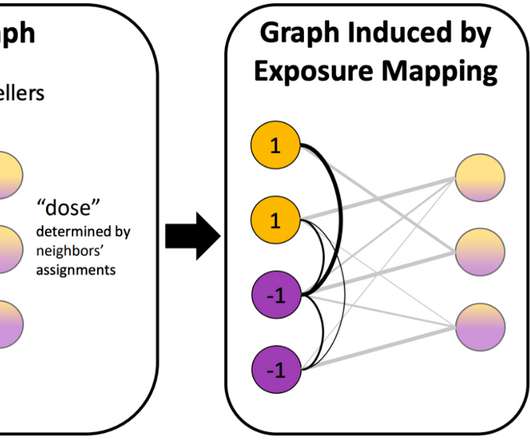

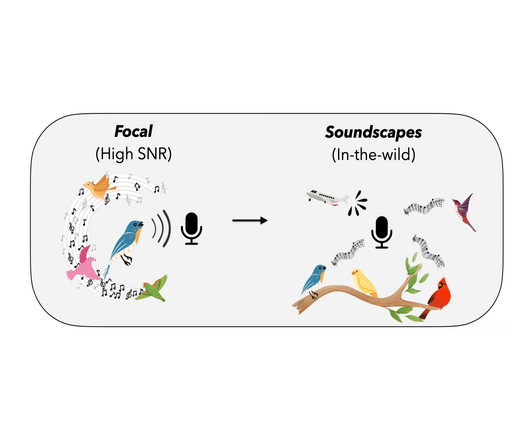













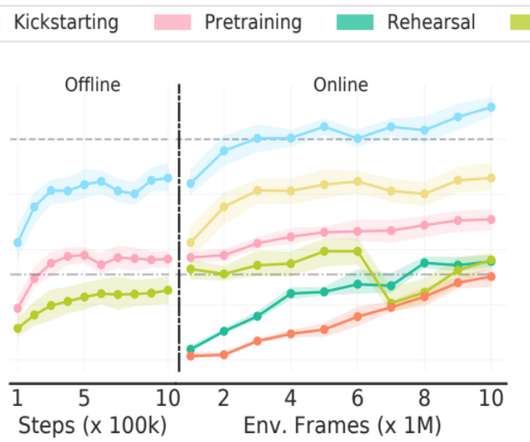






















Let's personalize your content