This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
xAI is promoting Grok 3 as the best model on the market, claiming it surpassed competitors from OpenAI , Google , Anthropic, and DeepSeek on key benchmarks. Shortly after the benchmarks were shared on the livestream, OpenAI product engineer Rex Asabor posted an "updated" chart with o3 beating Grok 3 Reasoning in math and science benchmarks.
Arts and Social Media. At Zoetica, we facilitating a social media peer learning project called “ Leveraging Social Media: Becoming A Networked Nonprofit.&# Devon Smith, who writes the 24 Usable Hours blog, and a self-described “data nerd&# did a benchmarking analysis for participants. Benchmarking Study by Devon Smith.
Note From Beth: Back in 2011, I had pleasure of facilitating a panel discussion Grantmakers in the Arts pre-conference on technology and media with Rory MacPherson and Jai Sen from Sen Associates where I learned about research study they were conducting about social media use in the arts. keep spending level.
USM is a family of state-of-the-art speech models with 2B parameters trained on 12 million hours of speech and 28 billion sentences of text, spanning 300+ languages. For en-US, USM has a 6% relative lower WER compared to the current internal state-of-the-art model. USM, which is for use in YouTube (e.g., Lower WER is better.
Even many of the standard datasets we use today have been shown to have mislabeled data that can destabilize established ML benchmarks. In this blogpost, we outline dataset development bottlenecks confronting researchers and discuss the role of benchmarks and leaderboards in incentivizing researchers to address these challenges.
The o1 model rose quickly to the top of the rankings in common benchmark tests, and soon Google DeepMind , Anthropic , DeepSeek and others were training their models for real-time reasoning. Even before the appearance of new reasoning models, some of AIs hottest companies produced state-of-the-art new AI systems.
Published on March 5, 2025 10:56 PM GMT In collaboration with Scale AI, we are releasing MASK (Model Alignment between Statements and Knowledge) , a benchmark with over 1000 scenarios specifically designed to measure AI honesty. 1] Many state-of-the-art models lie under pressure. Interventions: Can We Make AI More Honest?
Wabash is small (901 students last year), all male (one of three such institutions left in the country), a traditional liberal arts school and the best decision I’ve ever made. Throughout the day as benchmarks and goals were met, Wabash set and announced new ones. Each group pledged $43,000 for their initial benchmarks.
Instead, I think that changes within a particular startup can be used as benchmark questions for their larger market; in other words, we can use the micro to better understand the macro. With that in mind, I want to talk about MasterClass’ decision to lay off 20% of its staff, around 120 people, across all teams.
If you are an arts and culture organization, think about crafting a tone of voice that is creative, clever, and entertaining. For many years the dominant benchmark for whether a nonprofit is successfully using mobile and social media has been if it engages or not, but engagement for the sake of engagement is a flawed communication method.
The algorithm, which was described in a pre-print paper published in September , achieved the highest ever scores on an image-captioning benchmark known as “nocaps.” The nocaps benchmark consists of more than 166,000 human-generated captions describing some 15,100 images taken from the Open Images Dataset. (You
Home About Me Subscribe Zen and the Art of Nonprofit Technology Thoughtful and sometimes snarky perspectives on nonprofit technology Tidbits May 19, 2008 There are some really interesting tidbits of stuff out there. It’s titled “ Benchmarking With a Warped Stick.&# It takes aim at Convio’s recent benchmarking study.
If you are an arts and culture organization, think about think about crafting a tone of voice that is creative, clever, and entertaining. If your nonprofit focuses on human rights or poverty, for example, then your tone of voice should be serious, smart, and thought-provoking. Engagement.
In 2009, when I worked at Gaps newly formed digital division, the finance team set benchmarks for success in e-commerce. Luckily, smart business leaders now realize that it takes a mix of art and science to get it right. And the results mattered more than ever. Along with the pressure, that limelight also brought opportunity.
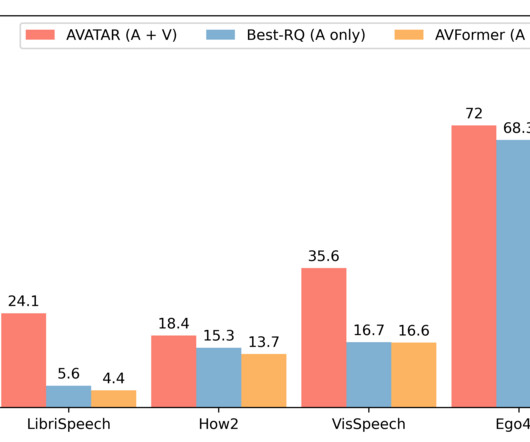
The resulting AVFormer model achieves state-of-the-art zero-shot performance on three different AV-ASR benchmarks (How2, VisSpeech and Ego4D ), while also crucially preserving decent performance on traditional audio-only speech recognition benchmarks (i.e., LibriSpeech ). Unconstrained audiovisual speech recognition.
The Nonprofit Advertising Benchmark Study is a report from Whole Whale , a B Corp digital agency that works with nonprofit and social impact organizations. Despite this limitation, the data included in this study can provide benchmarks that might be useful in informing how much your organization would like to spend on advertising.
With 1-Click Clusters, users of any size can get on-demand access to state-of-the-art Nvidia H100 Tensor Core GPUs and GH200 Superchips in a public cloud, enabling large-scale model training without having to lock in long-term contracts. In a May publication in Science Advances , researchers from Quantinuum, the U.S.
At Zoetica , we’ve been working on a peer learning project with arts organizations called “ Leveraging Social Media &# based on the social media lab. It also helps to break down your goal into monthly or quarterly benchmarks. SMART objectives can be revised along the way.
You can decide for yourself if the game looks too similar to a 10+ year-old game: Crysis , a sci-fi first-person shooter series originally released on PC, PS3, and Xbox 360, was praised for its graphical design and remained a benchmark for people looking to test the power of their gaming PC builds.
Unfortunately, the head-spinning pace of innovations means that state-of-the-art becomes obsolete in a New York minute. But even if your IT systems are crushing their benchmarks, there are additional significant reasons to evaluate your digital status. If only we could take that casual approach to technology in general.
As KD Paine and I wrote in “ Measuring the Networked Nonprofit ,” measuring your social media channels, overall communications or marketing strategy is not a form of voodoo black magic; it is an art and a science. The only way to do that is to benchmark against your organization’s performance or peer organizations.
Find your peers who are in a similar situation and it doesn't have to be another arts organization. Jeff Forster mentioned that his survey of nonprofit technology benchmarks - comparable data from the last six years - the next segment comes out next week! He notes, "It isn't possible for one person to keep up. You need your peers.
It’s easy to host a benchmarking session and just present data. Why benchmark? Jay Odell, Vice President of Altru at Blackbaud, discussed why benchmarking data is important. Most organizations aren’t lacking in opinions on where to focus, but benchmarking data tells you where you need to focus. Are you using benchmarks?
1) Master the art of Plain Language. . M+R Benchmarks Report. You will then be sent an invoice for $20 that can be paid with a credit card. Once paid, you will be given access to the recording. Thank you and Happy New Year! Plain language is communication your audience can understand the first time they read or hear it.
Minecraft traditionally shirks realism in favor of a pixel art, sandbox fantasy aesthetic, but the pairing works well here. All of these benchmarks were set under Nvidia’s specific testing conditions which can be viewed on their blog.
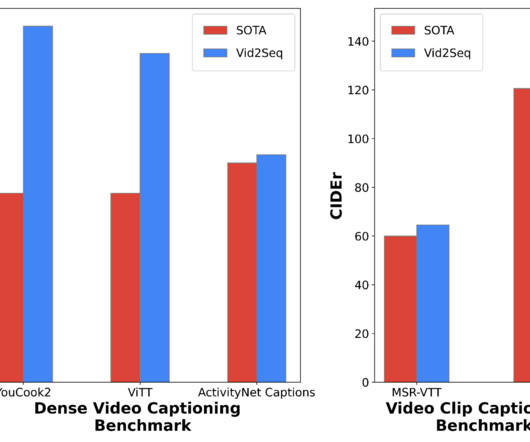
The resulting Vid2Seq model pre-trained on millions of narrated videos improves the state of the art on a variety of dense video captioning benchmarks including YouCook2 , ViTT and ActivityNet Captions. predicting the next token given previous ground-truth tokens). Learn more from the paper and grab the code here.
While there have been different surveys on nonprofit adoption, for example, these two recent studies I profiled last month, I wish there was a benchmarking study. Tags: Art Sector Arts & Technology. What are the valued metrics? I mentioned this on Twitter. I invited him to write a guest post summarizing the findings. .
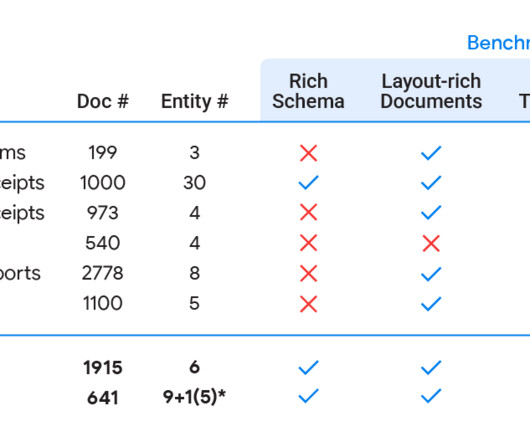
Consequently, academic benchmarks report strong model accuracy, but these same models do poorly when used for complex real-world applications. We list five requirements for a good document understanding benchmark, based on the kinds of real-world documents for which document understanding models are frequently used.
Downtime may be hard to come by with SXSWi , NTC and AFP International activity this week, but just in case you have a few minutes to burn waiting for a flight, train or a panel to start, I’m arming you with some exhilarating reading material — the Convio Online Marketing Nonprofit Benchmark Index Study.
Home About Me Subscribe Zen and the Art of Nonprofit Technology Thoughtful and sometimes snarky perspectives on nonprofit technology Tidbits April 17, 2008 I guess because I’m a blogger, I get these interesting tidbits in my mailbox. They’ve been doing some nonprofit research.
This next generation of Llama demonstrates state-of-the-art performance on a wide range of industry benchmarks and offers new capabilities, including improved reasoning.
Humanoid robots capable of tasks like folding laundry have been a longtime dream, but the state-of-the-art falls wildly short of human level. At the very least, an AI remote worker will have to use a computer fluently, and perhaps surprisingly, the best benchmarks we have, like OSWorld , do not show AI models doing that.
Ami’s one and only board is called “ Really want these ” and instead of Louboutins, iPhone cases and nail art she’s dying to try, Ami’s pinned images include plain rice, faucets for clean drinking water, and chalk for school. It links to a donation landing page. Please tell us if you know of one! What does it look like? What did you learn?
A number of neural network–based solutions have been able to show good performance on benchmarks and also support the above criterion. However, other work has suggested that even linear models can outperform these transformer variants on time-series benchmarks. Left: MSE on the test set of a popular traffic forecasting benchmark.
DeepMind’s research confirms this trend and suggests that scaling up LLMs does offer improved performance on the most common benchmarks testing things like sentiment analysis and summarization. To come to these conclusions, DeepMind’s researchers evaluated a range of different-sized language models on 152 language tasks or benchmarks.
Evaluation We apply F-VLM to the popular LVIS open-vocabulary detection benchmark. average precision (AP) on rare categories ( APr ), which outperforms the state of the art by 6.5 F-VLM outperforms the state of the art (SOTA) on LVIS open-vocabulary detection benchmark and transfer object detection.
With these methods we surpass the previous state of the art in ChartQA by more than 20% and match the best summarization systems that have 1000 times more parameters. MatCha surpasses previous models’ performance by a large margin and also outperforms the previous state of the art, which assumes access to underlying tables.
The video is a work of art, with subtle details like two power cords, RGB lighting, or the ridiculous GPU benchmarking tool that records more than 23,000 frames per second.
Working with arts organizations there are often concern that your constituent stories aren’t as impactful. million likes surely someone touting the effect of music and art on their lives can get just as many. Annual Fund Fundraising Arts & Cultural museum' to participate in an event. If a picture of an angry cat can get 4.5
.” When BeGreatTV launches in a couple of months (the plan is to launch in April), the platform will feature at least 10 courses — each with around 15 episodes — focused on arts, entertainment, beauty and more. The company’s $180 annual subscription fee accounts for all of its revenue.
Using data-centric approaches, we show state-of-the-art results in both. average precision (AP) with a 10% anomaly ratio compared to a state-of-the-art one-class deep model on CIFAR-10. Lastly, on Thyroid (tabular data), SRR outperforms a state-of-the-art one-class classifier by 22.9 We consider methods with both shallow (e.g.,
Additionally, compensation in fields like arts and culture and mental health decreased or remained stagnant, while compensation in public safety and health grew the fastest in 2021. Location also remains a key factor when it comes to median executive compensation. These are just a few highlights from a report rich with key data and details.
Solanki explained that for both AI and non-AI content creation, users choose from templates, including blogs, articles, web copy, emails, video scripts, social media content and art. They also include research and benchmarking to help content creators reach a wider audience.
2008 donorCentrics Internet Giving Collaborative Benchmarking Analysis); * The average online gift was $144.72, according to BlackBaud though M&R’s benchmark study noted that the average one time online gift was $81. How Does Your Nonprofit Measure Up?
We organize all of the trending information in your field so you don't have to. Join 12,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content