This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Creatives in the UK are once again speaking out against AI developers accessing copyrighted material. The Society of Authors have published an open letter calling for UK Secretary of State Lisa Nandy to hold Meta accountable for possible copyright infringement regarding its LLM, Llama 3. million books, to train its AI models.
Movies and other complex works created through AI means cannot be copyrighted, except when these AI tools are used to further develop pre-existing content. Read Entire Article
YouTube's "Erase Song" feature lets users precisely zap copyrighted tunes from their clips while keeping all the other audio intact. YouTube chief Neal Mohan hyped the new tool on X/Twitter, saying it will help easily remove copyright-claimed music from videos while preserving everything else. Read Entire Article
OpenAI filed a copyright complaint to Reddit over the unauthorized use of the company's copyrighted logo by the r/ChatGPT subreddit. Read Entire Article
Suno and Udio were hit with separate copyright infringement lawsuits from music labels Universal Music Group, Warner Music Group, and Sony Music Group on June 24. Read Entire Article
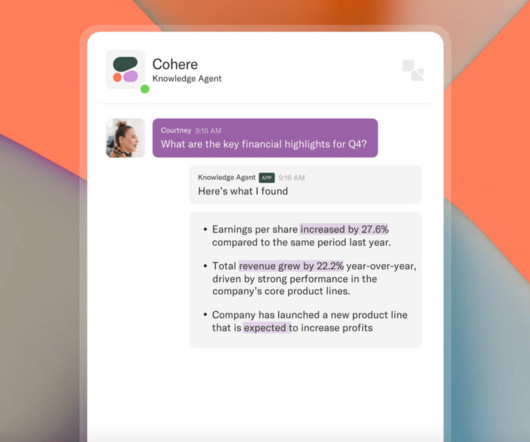
Cond Nast and several other media companies sued the AI startup Cohere today, alleging that it engaged in "systematic copyright and trademark infringement" by using news articles to train its large language model. Read full article Comments
Major publishers, including Politico and Vox , and their parent companies are suing the AI startup Cohere for copyright and trademark infringement, according to the Wall Street Journal. Additionally, the startup has been accused of passing off large segments of entire articles to its users without proper attribution. Thats theft.
The two new cases – Raw Story and AlterNet have the same owner, which filed a single suit – mirror the New York Times' arguments against OpenAI: that the company used copyrighted material to train ChatGPT. Read Entire Article
Bookshare pretty much has been made possible by the Chafee Amendment, a copyright exception provision in U.S. My impression from additional tweets, emails, posts and articles is that the French are really leading the charge against a treaty. Tags: print disabled blind SCCR18 copyright copyfight SCCR Bookshare WIPO.
One of the groups at the forefront of this fight is the Electronic Frontier Foundation (EFF), which has filed an amicus brief in the US Supreme Court providing an overview of the copyright trolling problem. Read Entire Article The filing is part of the Warner Chappell Music v. Nealy case, which does not.
It's no secret that LLMs use swaths of information from the internet as training data, but the NYT claims in its copyright infringement lawsuit that its content has been given "particular emphasis." Read Entire Article The suit, filed in Manhattan federal court, claims that the companies "seek to free-ride on the Times's massive.
The publishers argue that OpenAI's practices amount to copyright infringement on a massive scale, potentially threatening the future of journalism. Read Entire Article The case has merged lawsuits from three publishers: The New York Times, The New York Daily News, and the Center for Investigative Reporting.
The Tennesse lawsuit alleges that Twitter "fuels its business with countless infringing copies of musical compositions, violating Publishers' and others' exclusive rights under copyright law." Read Entire Article
Hollywood studios would not enforce copyright on these videos. This article originally appeared on Engadget at [link] As it turns out, major movie studios have actually been making money from the videos, according to reporting by Deadline. The scheme worked sort of like a mob shakedown.
The trend had raised concerns, yet again, about the legality of using copyrighted work as training data for artificial intelligence. pic.twitter.com/fnen1aDjNZ OpenAI (@OpenAI) March 25, 2025 This article originally appeared on Engadget at [link] "I strongly feel that this is an insult to life itself," the director said.
Howell upheld the finding by the US Copyright Office that a piece of AI-generated art cannot be copyrighted, writes the Hollywood Reporter. Read Entire Article United States District Court Judge Beryl A. The agency had refused to grant a patent to Stephen Thaler, who wanted an AI-generated image he produced with the Creativity.
Read Entire Article , features recordings of empty studios and performance spaces. Organizers say this represents the potential impact on artists' livelihoods, and creativity in general, should the government's plans go ahead.
Researchers gathered more than a thousand training examples from the models, which ranged from individual person photographs to film stills, copyrighted news images, and trademarked firm logos, and discovered that the AI reproduced many of them almost identically. Read Entire Article
The US Copyright Office has dealt a significant blow to video game preservation efforts by denying a request for a Digital Millennium Copyright Act (DMCA) exemption, allowing libraries to provide remote access to preserved video games. The decision, announced last week, marks the fourth time since 2015 that the copyright.
Meta openly admitted to using the Book3 dataset, a well-known 37GB compilation of 195,000 copyrighted books used by developers to train LLMs. Read Entire Article In January 2024, a group of writers filed a lawsuit in California against Meta for using their works to train various versions of the Llama large language model.
Read Entire Article Over 400 actors, musicians, filmmakers, writers, and more signed the letter sent to the White House, including Ben Stiller, Mark Ruffalo, Cate Blanchett, Paul McCartney, and Ron Howard, reports The Wrap.
First, it makes creating a national domestic copyright exception an obligation of countries that ratify the Treaty. Second, the Treaty allows for easier import and export of accessible versions of books and other copyrighted works. Noteworthy Articles in the Treaty: Article 2(a). Article 2(c). Articles 5 and 6.
OpenAI recently told members of the House of Lords that it is "impossible" to train large language models (LLMs) without using copyrighted material. Read Entire Article The claim was in response to the UK's Communications and Digital Select Committee, which is looking into the legal issues involving current AI systems.
Read Entire Article Writers and journalists Andrea Bartz, Charles Graeber, and Kirk Wallace Johnson brought the lawsuit, which seeks class action status.
Judge Bibas rejected Ross Intelligence's fair use defense, a key argument used by AI companies in copyright disputes. Read Entire Article The case, filed in 2020, accused Ross Intelligence of reproducing materials from Thomson Reuters' Westlaw legal research database to build a competing AI-powered legal platform.
Stanford law professor Mark Lemley represented Meta in a 2023 copyright case in which the company used a data set containing copyrighted e-books to train its LLMs, something it says should be considered fair use. Read Entire Article
Read Entire Article According to internal Slack chats, emails, spreadsheets, and several other sources obtained by 404 Media, Nvidia asked workers to download videos from various online platforms to compile data to train its Omniverse, autonomous vehicles, and digital human products.
When they break, and they break often, understanding the error codes and accessing the secret, locked service menu requires calling an expensive ($315 per 15 minutes, Read Entire Article
The New York Times is suing OpenAI and its close collaborator (and investor), Microsoft, for allegedly violating copyright law by training generative AI models on Times’ content.
The lawsuit claimed Anthropic was violating US copyright laws with its actions. Read Entire Article UMG, Concord and ABKCO sued Anthropic in 2023 over claims that it used lyrics from at least 500 songs by musicians including Beyonce, the Rolling Stones and the Beach Boys, to train Claude without permission.
Things got off to a rocky start after an app called iGBA was pulled from the App Store less than a week after its debut over violating spam and copyright violations. Read Entire Article The next app to try its luck, an emulator known as Delta, did things the right way and quickly.
According to Japanese media, this marks the first arrest in the country for circumventing the portable device's copyright protection. Read Entire Article A 58-year-old man from Ibaraki Prefecture, Japan, was arrested for selling modified Nintendo Switch consoles designed to play pirated games.
Full TechCrunch+ articles are only available to members Use discount code TCPLUSROUNDUP to save 20% off a one- or two-year subscription “This is really only talking about world-changing, big-ass businesses with a lot of impact that could be a billion dollars or more in value,” he said. “If Are you spending too much on paid acquisition?
Generative AI's true value remains uncertain, and controversies over reliability and copyright haven't faded. Read Entire Article Despite the resources tech giants have recently poured into AI PCs, IDC data suggests their spread into the market will take years, and developers are slow to utilize them.
Monday night, Congress approved an over $2 trillion government spending and coronavirus relief package that included a handful of controversial copyright and trademark measures. The news circulated all across the internet; in a poorly headlined Hollywood Reporter article, tweets, and YouTube videos. Copyright is messy.
Read Entire Article The symposium brought together prosecutors, industry representatives, and anti-piracy experts to discuss the latest piracy trends and potential solutions. TorrentFreak reports that when it came to new measures, site blocking was heavily pushed as an effective remedy that the US has been lacking.
The file sharing service made it trivially easy for the average Joe to share and download copyrighted music with others online, threatening the livelihood of artists and record labels. Read Entire Article Legal issues proved to be Napster's undoing, with the service.
At the same time, many generative video tools also highlight questions and challenges around content ownership and copyright. Read Entire Article Some of these have become a key part of larger discussions on the development and evolution of AI-powered tools.
The NYT sued OpenAI and Microsoft in December for using millions of its articles to train their systems without permission or compensation. The suit states that millions of the Times' copyrighted news pieces, in-depth investigations, opinion features, reviews, how-to guides, and more were used to train the chatbots, which now.
The European Union Intellectual Property Office's most recent biannual report on copyright infringement in the UK and Europe makes for some interesting reading. Read Entire Article Based on data from MUSO, a UK tracking firm, the years-long decline in piracy traffic has reversed since the start of 2021.
In its suit filed in US federal court, Nintendo alleges that Yuzu violates the anti-circumvention and anti-trafficking provisions of the Digital Millennium Copyright Act (DMCA). Read Entire Article
Interesting article over at the icommons.org site called CC Licensing Practice Reviewed Alek Tarkowski, ccPoland It mentions an experiment in a dutch town where they removed the traffic signs or the rules. As noted in the article, Once rules are removed, people become considerate. iron cage of copyright???
The so-called " paper of record " is now encouraging staff to use generative AI tools to write headlines and summarize articles. Along with models from Google, Github, and Amazon, NYT staff will also have access to Echo, a bespoke tool currently in beta that's designed to condense articles into shorter summaries.
We organize all of the trending information in your field so you don't have to. Join 12,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content