This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Using the ADDIE for designing your workshop, you arrive at the “E” or evaluation. ” While a participant survey is an important piece of your evaluation, it is critical to incorporate a holistic reflection of your workshop. There are two different methods to evaluate your training. Formative Evaluation.
Previously, the stunning intelligence gains that led to chatbots such ChatGPT and Claude had come from supersizing models and the data and computing power used to train them. o1 required more time to produce answers than other models, but its answers were clearly better than those of non-reasoning models.
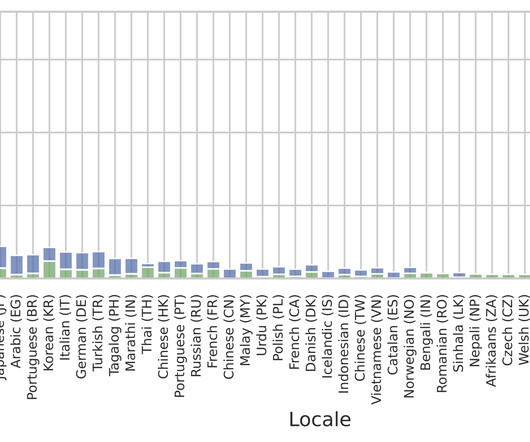
Posted by Thibault Sellam, Research Scientist, Google Previously, we presented the 1,000 languages initiative and the Universal Speech Model with the goal of making speech and language technologies available to billions of users around the world. Such evaluation is a major bottleneck in the development of multilingual speech systems.
It used to be that the decision to hold a fundraising event – and what kind – was determined by evaluating the revenue potential of a particular event and by what the expense would be to the organization, in both capital outlay and staffing time. The advantage of this model for the museum was threefold: .
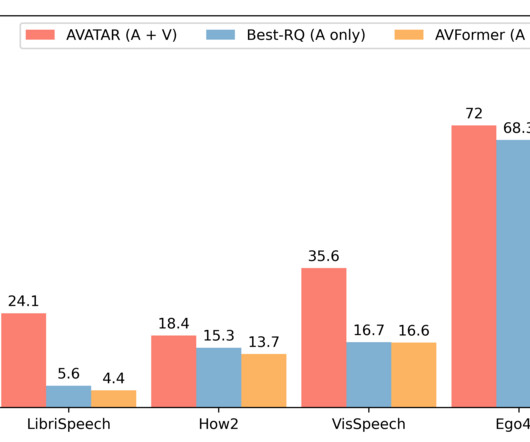
Building audiovisual datasets for training AV-ASR models, however, is challenging. In contrast, the models themselves are typically large and consist of both visual and audio encoders, and so they tend to overfit on these small datasets. LibriSpeech ). LibriSpeech ). Unconstrained audiovisual speech recognition.
Companies face several hurdles in creating text-, audio- and image-analyzing AI models for deployment across their apps and services. Cost is an outsize one — training a single model on commercial hardware can cost tens of thousands of dollars, if not more. ” Image Credits: Deci.
Posted by Tal Schuster, Research Scientist, Google Research Language models (LMs) are the driving force behind many recent breakthroughs in natural language processing. Models like T5 , LaMDA , GPT-3 , and PaLM have demonstrated impressive performance on various language tasks. The encoder reads the input text (e.g.,
“Based on our experience, we decided to build a platform — Taktile — to empower experts, such as a head of risk, to design, evaluate and deploy decision flows on their own without the need for developers,” Wehmeyer said in an email interview. ” Image Credits: Taktile.
Although the most popular accounting software products- like QuickBooks and SAP- handle the needs of businesses in many industries, nonprofits have a unique business model and accounting standards and require different features and functionality from accounting software. Here are some common requirements that may apply to your organization.
Posted by Shunyu Yao, Student Researcher, and Yuan Cao, Research Scientist, Google Research, Brain Team Recent advances have expanded the applicability of language models (LM) to downstream tasks. On the other hand, recent work uses pre-trained language models for planning and acting in various interactive environments (e.g.,
Models of Collaboration , by professor Mark Hager and Tyler Curry, identifies and describes types of nonprofit collaborations from an analysis of the 177 nominations submitted in 2009 for the prestigious Collaboration Prize. We noticed that a great deal did not fit neatly into any one model outlined in Models of Collaboration.
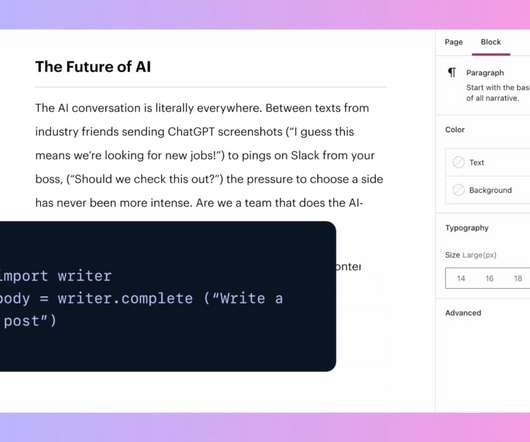
Writer is such a one, and it just announced a new trio of large language models to power its enterprise copy assistant. The company lets customers fine-tune these models on their own content and style guides, from which point forward the AI can write, help write or edit copy so that it meets internal standards.
Posted by Shekoofeh Azizi, Senior Research Scientist, and Laura Culp, Senior Research Engineer, Google Research Despite recent progress in the field of medical artificial intelligence (AI), most existing models are narrow , single-task systems that require large quantities of labeled data to train.
Addressing the Key Mandates of a Modern Model Risk Management Framework (MRM) When Leveraging Machine Learning . The regulatory guidance presented in these documents laid the foundation for evaluating and managing model risk for financial institutions across the United States.
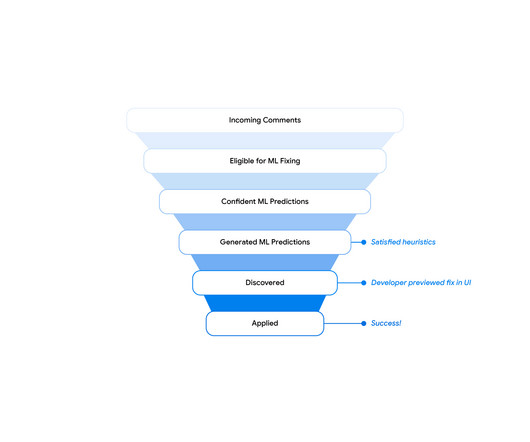
Today, we describe applying recent advances of large sequence models in a real-world setting to automatically resolve code review comments in the day-to-day development workflow at Google (publication forthcoming). Predicting the code edit We started by training a model that predicts code edits needed to address reviewer comments.
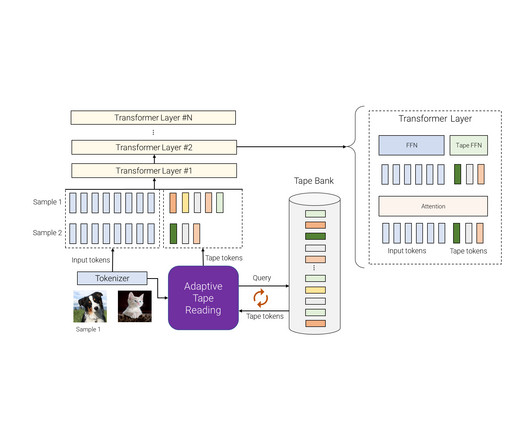
While conventional neural networks have a fixed function and computation capacity, i.e., they spend the same number of FLOPs for processing different inputs, a model with adaptive and dynamic computation modulates the computational budget it dedicates to processing each input, depending on the complexity of the input.
Subsequent models will incorporate changes based on consumer feedback. It opens services and activities to ongoing evaluation and adjustment. Making a habit of game planning alternate scenarios is another way to promote agile thinking. The MVP is the first of several iterations.
In our previous two posts, we discussed extensively how modelers are able to both develop and validate machine learning models while following the guidelines outlined by the Federal Reserve Board (FRB) in SR 11-7. Monitoring Model Metrics.
This is a really great post to read for anyone thinking about how to measure, evaluate, and even consider the impact of social media use (and that should be everyone). "Over Additional models of collaboration from The Collaboration Prize will be added soon.
Posted by Yicheng Fan and Dana Alon, Software Engineers, Google Research Every byte and every operation matters when trying to build a faster model, especially if the model is to run on-device. Using a search space built on backbones taken from MobileNetV2 and MobileNetV3 , we find models with top-1 accuracy on ImageNet up to 4.9%
In the same way that BERT or GPT-3 models provide general-purpose initialization for NLP, large RL–pre-trained models could provide general-purpose initialization for decision-making. Our shared vision backbone also utilized a learned position embedding (akin to Transformer models) to keep track of spatial information in the game.
The refined data, with a lower anomaly ratio, are shown to yield superior anomaly detection models. GOAD , CutPaste ) models. Since the anomaly ratio of real-world data can vary, we evaluatemodels at different anomaly ratios of unlabeled training data and show that SRR significantly boosts AD performance.
There has been some discussion about for-profit alternatives to the traditional nonprofit model, such as “B” (for benefit) and “L3C” (Low-profit Limited Liability Company) corporations, which combine low profits with a social mission. One such model is the Social Impact Bond (SIB). The Role of Evaluation.
In the nonprofit space, large language models like ChatGPT can support overworked staff that operate with limited resources. Nonprofits may lack the technical expertise and staff capacity to evaluate or adopt AI effectively. This reframing can reduce skepticism and encourage broader adoption. Build AI literacy. Foster collaboration.
Alternatively, companies try to build their own solutions using Elasticsearch. As its business model, Tilo charges a license fee based on the volume of data companies are processing through TiloRes. Steven Renwick, Tilo CEO, said: “Our biggest advantage is that searching, matching and evaluating data (e.g.
Google has removed 1% of cookies to test their cookie alternative, and are planning to fully remove support for them in Q1 2025. Google and many advertising platforms propose that we replace this identifier (cookies) with alternatives based on first-party data (like email, name, or phone number).
The scratchpads from reasoning models look human understandable: when reasoning about a math problem, reasoning models consider intermediate steps similar to the ones I would use, backtrack and double-check their work as I would. [1] Sonnet, and then fine-tune the base model of Claude 3.7 Sonnet, paraphrase them using Claude 3.5
via a model spec ) or instructions directly given to Agent-3 (e.g. Alternatively, perhaps there is something like objectively true morality, and AIs will naturally converge to it as they get smarter. In fact by this point models are rarely trained from scratch but instead are mostly old models with lots of additional training.
Robust algorithm design is the backbone of systems across Google, particularly for our ML and AI models. We provided a model-based taxonomy that unified many graph learning methods. In addition, we discovered insights for GNN models from their performance across thousands of graphs with varying structure (shown below).
Pricing models can be powerful growth levers. A bad pricing model will impede growth, and can even doom an otherwise promising startup, whereas a good model will capture some of the value that a product creates as revenue, and keep growth flywheels humming along. What are their alternatives?
TomoCredit is a credit card that operates with a debit card model that is issued by Community Federal Savings Bank, a member of the FDIC. Another unique aspect of Tomo’s model, Kim believes, is that it makes money through merchant fees and not through the consumers who use its card. . And that’s not their fault.
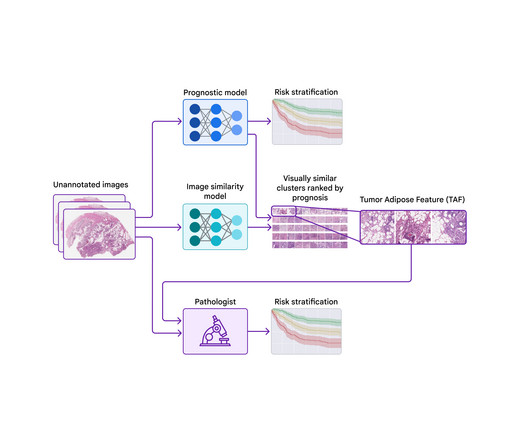
While these efforts focus on using ML to detect or quantify known features, alternative approaches offer the potential to identify novel features. We describe this feature and evaluate its use by pathologists in our recently published paper, “ Pathologist validation of a machine-learned feature for colon cancer risk stratification ”.
Businesses usually plot their growth strategies on spreadsheets, but Drivetrain wants to provide a faster alternative for financial planning and decision-making. During his six years at the firm, Goel evaluated hundreds of SaaS companies and served on many of their boards.
While there have been many recent advances in training joint visual-language models on Internet-scale data, figuring out how to best connect them to a spatial representation of the physical world that can be used by robots remains an open research question.
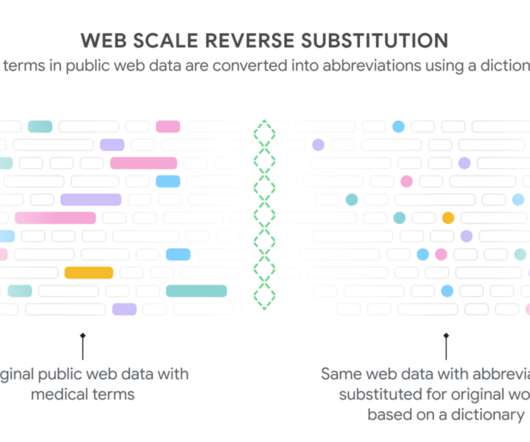
lbp” means “low back pain”), and even familiar abbreviations, such as “pt” for “patient”, can have alternate meanings, such as “physical therapy.” We built the model using only public data on the web that wasn't associated with any patient (i.e., The model input is a string that may or may not contain medical abbreviations.
Published on February 7, 2025 3:57 AM GMT DeepSeek-R1 has recently made waves as a state-of-the-art open-weight model, with potentially substantial improvements in model efficiency and reasoning. But like other open-weight models and leading fine-tunable proprietary models such as OpenAIs GPT-4o, Googles Gemini 1.5
” ADDIE is an instructional design method that stands for Analysis, Design, Development, Implementation, and Evaluation. Sometimes you don’t have the ability to do a survey before, especially if it is an online webinar or a conference session. There are alternative ways to do research. This is evaluation.
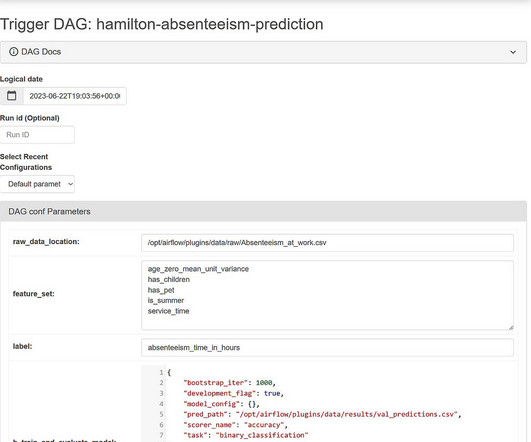
Note: Hamilton actually enables you to logically model everything that you’d want an Airflow DAG to do. Let’s look at some code that create a single node Airflow DAG but uses Hamilton to train and evaluate a ML model: [link] Now, we didn’t show the Hamilton code here, but the benefits of this approach are: Unit & integration testing.
Published on March 12, 2025 5:56 PM GMT Summary The Stages-Oversight benchmark from the Situational Awareness Dataset tests whether large language models (LLMs) can distinguish between evaluation prompts (such as benchmark questions) and deployment prompts (real-world user inputs).
Adaptive learning models can empower teachers to customize instruction for each student’s needs, and students can even personalize a digital tutoring experience. Imagine empowering a teacher with generative AI to improve question-building workflows for online assessments and open-book evaluations.
Security When evaluating an LMS, prioritize providers with a robust Cloudops Security Policy. Solution: Utilize analytics, reports, and feedback tools to monitor LMS activity and consult with experts and users to evaluate compliance, effectiveness, and improvement opportunities.
Improve how your nonprofit evaluates, recognizes, and motivates its employees. If you would like to significantly improve how your nonprofit evaluates, recognizes, and motivates its employees, there are a few strategies that you might implement to help guarantee success. So How Do We Achieve This Gold Standard of Evaluation?
Many startups rely on venture debt: it’s both a cheaper alternative to raising equity and can serve as a capital tool that helps companies build in ways that equity isn’t great for. Lastly, we’re seeing lenders take extreme caution to evaluate startups for venture debt based on the strength of their leadership team. -based startups.
It turns out that the latest generation of language models, such as PaLM , are capable of complex reasoning and have also been trained on millions of lines of code. To explore this possibility, we developed Code as Policies (CaP), a robot-centric formulation of language model-generated programs executed on physical systems.
We organize all of the trending information in your field so you don't have to. Join 12,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content