This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
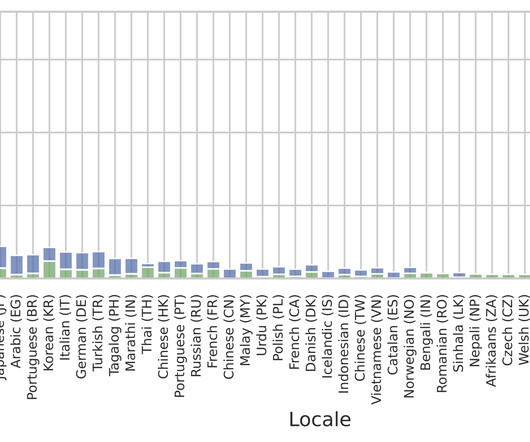
Posted by Thibault Sellam, Research Scientist, Google Previously, we presented the 1,000 languages initiative and the Universal Speech Model with the goal of making speech and language technologies available to billions of users around the world. Such evaluation is a major bottleneck in the development of multilingual speech systems.
Building robots that are proficient at navigation requires an interconnected understanding of (a) vision and natural language (to associate landmarks or follow instructions), and (b) spatial reasoning (to connect a map representing an environment to the true spatial distribution of objects).
For international organizations, you may face additional complexity such as handling multiple currencies and multiple languages. To find the right product for your needs, the best place to begin is with requirements to help you evaluatealternatives. Support multiple languages. High-Level Requirements. Financial Tool Kit.
Posted by Tal Schuster, Research Scientist, Google Research Language models (LMs) are the driving force behind many recent breakthroughs in natural language processing. Models like T5 , LaMDA , GPT-3 , and PaLM have demonstrated impressive performance on various language tasks. The encoder reads the input text (e.g.,
Posted by Shunyu Yao, Student Researcher, and Yuan Cao, Research Scientist, Google Research, Brain Team Recent advances have expanded the applicability of language models (LM) to downstream tasks. On the other hand, recent work uses pre-trained language models for planning and acting in various interactive environments (e.g.,
Google DeepMind broke through with a family of natively multi-modal models called Gemini that understand imagery and audio as well as they do language. Mistral released impressive new small language models that can run on laptops and even phones with its Ministral 3B and Ministral 8B, as did Microsoft with its Phi-3 and Phi-4 models.
The analytics tools will also evaluate your posts to deduce the best possible times to share your content. Dulingo provides access to free online language learning tools. For nonprofit social media managers that work internationally, Dulingo’s design and gamification make it fun to learn the basics of a new language.
6) Sharing Impact With just a few details about your organization, ChatGPT can write boilerplate language about your impact, mission, and programs. This technology is particularly valuable for mission work, such as monitoring changes in wildlife populations or evaluating the effectiveness of conservation efforts.
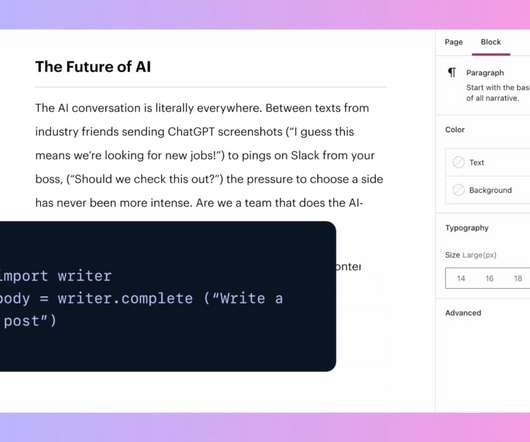
Writer is such a one, and it just announced a new trio of large language models to power its enterprise copy assistant. More than just catching typos and recommending the preferred word, Writer’s new models can evaluate style and write content themselves, even doing a bit of fact-checking when they’re done.
By combining the worlds largest manufacturing data foundation with proprietary algorithms, the company claims to deliver real-time lifecycle assessments 100 times faster than the best available alternatives. Air Force, Varda Space Industries, and others, continue to transform testing and evaluation.
The analytics tool evaluates the effectiveness of your posts and provides the best times to share your content. Rote is a web-based grant writing tool that saves your past language in one place – organized, filterable, and at your fingertips when you need it to write a first draft of a new proposal. Buffer :: buffer.com.
Alternatively, 69 percent of email recipients flag an email as spam based on the subject line. Since it sounds a bit disingenuous, its best to remove or replace them with more accessible language. To knock your subject line out of the park, Mailmeteor will also provide a list of alternative subject lines based on the one you entered.
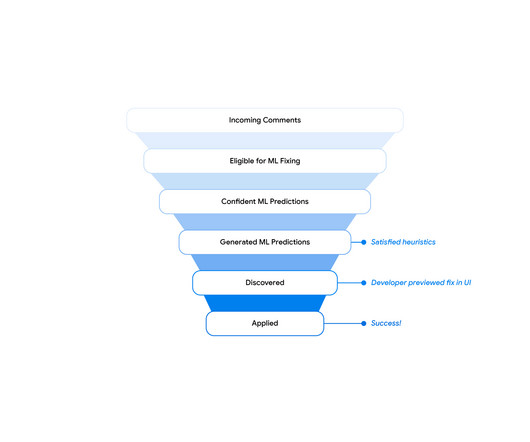
As part of this process, the reviewer inspects the proposed code and asks the author for code changes through comments written in natural language. As part of this, we explored different user experience (UX) alternatives through a series of user studies. We then refined the feature based on insights from an internal beta (i.e.,
In the nonprofit space, large language models like ChatGPT can support overworked staff that operate with limited resources. Nonprofits may lack the technical expertise and staff capacity to evaluate or adopt AI effectively. This reframing can reduce skepticism and encourage broader adoption. Build AI literacy. Foster collaboration.
Disseminates automated notifications for policy updates and acknowledgment in employees’ preferred languages, ensuring everyone is up-to-date. Generates reports in various languages to cater to diverse workforces and ensure clear communication across all levels of the organization.
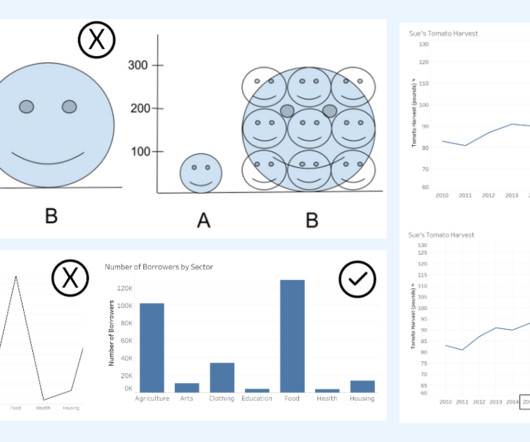
Alberto Cairo, data visualization expert and author of How Charts Lie Whether you are reading a social post, news article or business report, it’s important to know and evaluate the source of the data and charts that you view. When viewing summary numbers, evaluate if the summary number is appropriate.
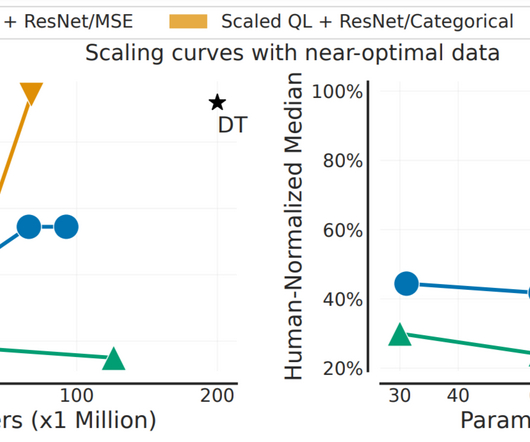
Pre-training on diverse datasets has proven to enable data-efficient fine-tuning for individual downstream tasks in natural language processing (NLP) and vision problems. However, running RL algorithms in the real world requires expensive active data collection. only data from highly suboptimal policies).
We evaluated the power of “why” questions for your donors in a recent webinar. Desired Action vs. Alternative Action : Your value proposition applies at every step along the donor mountain, not just with donations. give to you”) and an alternative action (e.g. Check it out ! With each step, there will be a desired action (e.g.
Businesses usually plot their growth strategies on spreadsheets, but Drivetrain wants to provide a faster alternative for financial planning and decision-making. During his six years at the firm, Goel evaluated hundreds of SaaS companies and served on many of their boards.
It turns out that the latest generation of language models, such as PaLM , are capable of complex reasoning and have also been trained on millions of lines of code. To explore this possibility, we developed Code as Policies (CaP), a robot-centric formulation of language model-generated programs executed on physical systems.
Kanopis nonprofit website maintenance guide recommends taking a continuous improvement approachthis involves regularly evaluating your websites analytics and user feedback and implementing the insights you learn. Review your website regularly to ensure a positive visitor experience from the very beginning of the user journey.
Improve how your nonprofit evaluates, recognizes, and motivates its employees. If you would like to significantly improve how your nonprofit evaluates, recognizes, and motivates its employees, there are a few strategies that you might implement to help guarantee success. So How Do We Achieve This Gold Standard of Evaluation?
Byteboard , a service designed to replace the pre-onsite technical interview part of a company’s hiring process with a web-based alternative, will be spinning out of Google, TechCrunch learned and Google confirmed. And this evaluation is handled anonymously, with the aim of taking the bias out of the process.
” ADDIE is an instructional design method that stands for Analysis, Design, Development, Implementation, and Evaluation. Sometimes you don’t have the ability to do a survey before, especially if it is an online webinar or a conference session. There are alternative ways to do research. This is evaluation.
The country’s financial system is volatile and often leaves its citizens with few or no alternatives. Yet, it’s a startup with a CEO and co-founder who isn’t Brazilian, didn’t speak the local language of Portuguese, hadn’t started a company before, and didn’t really know a lot about banking to begin with.
Morcos , Dhruv Batra Offline Q-Learning on Diverse Multi-task Data Both Scales and Generalizes (see blog post ) Aviral Kumar , Rishabh Agarwal , Xingyang Geng , George Tucker , Sergey Levine ReAct: Synergizing Reasoning and Acting in Language Models (see blog post ) Shunyu Yao *, Jeffrey Zhao , Dian Yu , Nan Du , Izhak Shafran , Karthik R.
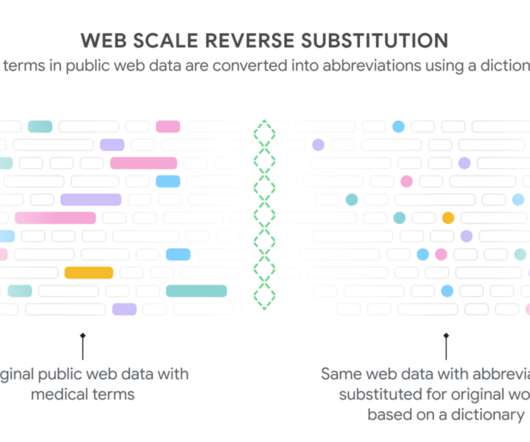
However, clinical notes are hard to understand because of the specialized language that clinicians use, which contains unfamiliar shorthand and abbreviations. Coming up with this translation is tough for laypeople and computers because some abbreviations are uncommon in everyday language (e.g., “lbp”
Published on March 12, 2025 5:56 PM GMT Summary The Stages-Oversight benchmark from the Situational Awareness Dataset tests whether large language models (LLMs) can distinguish between evaluation prompts (such as benchmark questions) and deployment prompts (real-world user inputs).
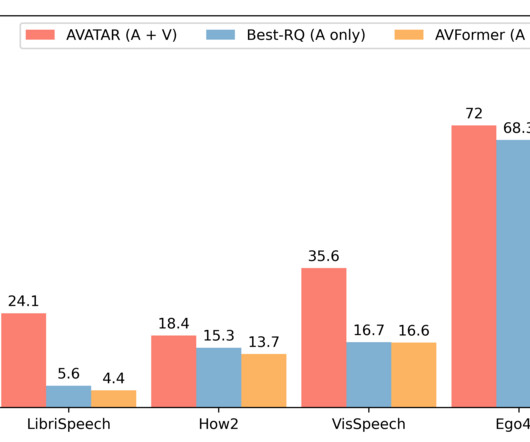
AVFormer injects visual embeddings into a frozen ASR model (similar to how Flamingo injects visual information into large language models for vision-text tasks) using lightweight trainable adaptors that can be trained on a small amount of weakly labeled video data with minimum additional training time and parameters.
Better maybe, for the different pieces to keep to themselves, with their own methods, language, and professional development programs? The alternative is fragmentation and balkanization, which is no alternative at all. Is that really a reason to study , talk about , and define a professional identity of a "nonprofit sector?"
NAS, which is difficult to evaluate , can be expensive and time-consuming.) Due to the growth in Deci’s business and the product expansion opportunities into additional domains such as natural language processing, among others, our existing investors decided to double down to support that growth,” Geifman said. ” .
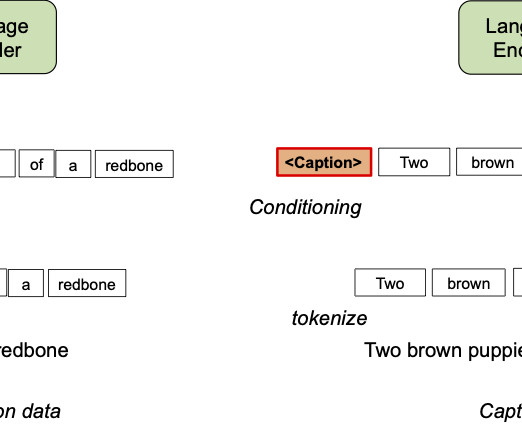
Posted by Kuniaki Saito, Student Researcher, Cloud AI Team, and Kihyuk Sohn, Research Scientist, Perception Team Pre-training visual language (VL) models on web-scale image-caption datasets has recently emerged as a powerful alternative to traditional pre-training on image classification data. classification vs. caption).
. “We use Claude to evaluate particular parts of a contract, and to suggest new, alternativelanguage that’s more friendly to our customers,” Robin CEO Richard Robinson said in an emailed statement. “We’ve Modern chatbots are notoriously prone to toxic, biased and otherwise offensive language.
In light of that trend and all the recent travel upheaval due to COVID – 19, with increasing restrictions being placed on companies and their global workforce, we wanted to address creative alternatives to traditional volunteer events. . There’s an app for that!
In “ Robust Routing Using Electrical Flows ”, we presented a recent paper that proposed a Google Maps solution to efficiently compute alternate paths in road networks that are resistant to failures (e.g., The clients evaluate these suggestions and return measurements. closures, incidents).
In this resource-strapped environment, it's arguable that not considering open source options seriously when evaluating your software toolbox is a disservice to your organization, board, constituents, and clients. . The new wave includes CRM (SugarCRM, CiviCRM) and desktop applications like Open Office and GIMP (a Photoshop alternative). .
Imagine empowering a teacher with generative AI to improve question-building workflows for online assessments and open-book evaluations. Imagine being able to ask your AI to review all your saved topics and suggest alternatives and improvements based on related assessments and grades.
The evaluation of each phase typically relies on comparing a dirty dataset against a clean (ground truth) version, using classification metrics like recall, precision, and F1-score for error detection (see for example Can Foundation Models Wrangle Your Data? or Large Language Models as Data Preprocessors ). 102 instead of 12).
A note on durability Best foldable phones for 2025 How we test foldable phones When evaluating new foldable phones, we consider the same general criteria as we do when were judging the best smartphones. Table of contents Best foldable phones for 2025 How we test foldable phones Are foldable phones worth it?
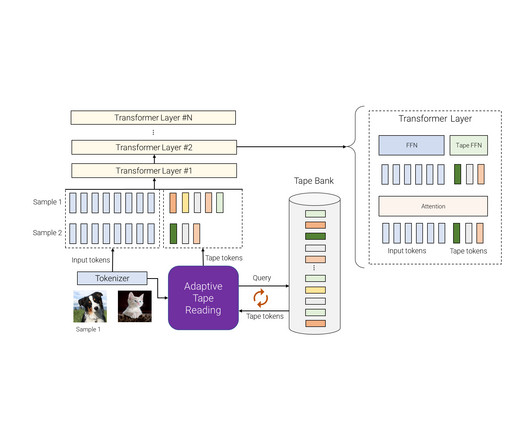
AdaTape provides helpful inductive bias We evaluate AdaTape on parity, a very challenging task for the standard Transformer, to study the effect of inductive biases in AdaTape. Parity is the simplest non-counter-free or periodic regular language , but perhaps surprisingly, the task is unsolvable by the standard Transformer.
From the stories I’ve heard this week, nonprofits of the size that I’m most familiar with (small to medium-sized) still don’t have in-house technology expertise to make evaluations about what directions to go in. The previous sentence is a clumsy attempt to use langage from both parties in the conversation.
We think this adversarial style of evaluation and iteration is necessary to ensure an AI system has a low probability of catastrophic failure. Wed like to support more such evaluations, especially on scalable oversight protocols like AI debate. and Which rules are LLM agents happy to break, and which are they more committed to? .
Data Handling, Overview, Measurement, Evaluation and Reporting (4 percent). Alternative Supports (<1 percent). Miscellaneous (3 percent). Corporate Delegation and Oversight, Organizational Structure (5 percent). Project Demographics/Orientation/Status (2 percent). How Did You Hear of Us (<1 percent).
Alternatively, the developer can continue to rely on human oversight to assure safety. The developer also runs targeted evaluations of M_1 , for example, removing AI safety research from 2024 from its training data and asking it to re-discover 2024 AI safety research results. One method is to perform a holistic control evaluation.
We organize all of the trending information in your field so you don't have to. Join 12,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content